Linux VFS
文件系统是操作系统中负责管理持久数据的子系统,其基本数据单位是文件。 在 Linux 中 everything is a file,除了你写的文档、下载的音乐、运行的程序,还包括网络连接的 socket、挂载的设备、管道等等都属于文件。所有不同类型的文件都交由文件系统来管理。对文件的组织形式不同,也就对应着不同类型的文件系统。为了屏蔽不同文件系统的差异和操作细节,接入不同类型的文件系统,Linux 通过 VFS 将 open、read、write 这样的系统调用抽象出来,为用户程序提供了文件和文件系统的统一接口,不再需要考虑具体的文件系统和实际的存储介质。本文将介绍 Linux VFS 的设计与实现,参考 Linux 内核实现版本为 v5.4。

Linux 支持的各种不同类型的文件系统,根据存储位置的不同,可以分为三类:
- 硬盘的文件系统:比如 xfs,ext4 等
- 内存的文件系统,比如 /proc,/sys,读写这类文件,实际上是读写内核中相关的数据结构
- 网络的文件系统,比如 NFS,SMB 等
文件系统的基本单位 Block
磁盘物理结构
如前所述,文件一般是存储在硬盘中的,常见的有机械硬盘和固态硬盘,下图是机械硬盘的常见结构:
- 机械硬盘中有很多层盘片 Cylinder
- 每层盘片有多个刺刀 Track
- 每个磁道分为多个扇区 Sector,每个扇区是 512 字节
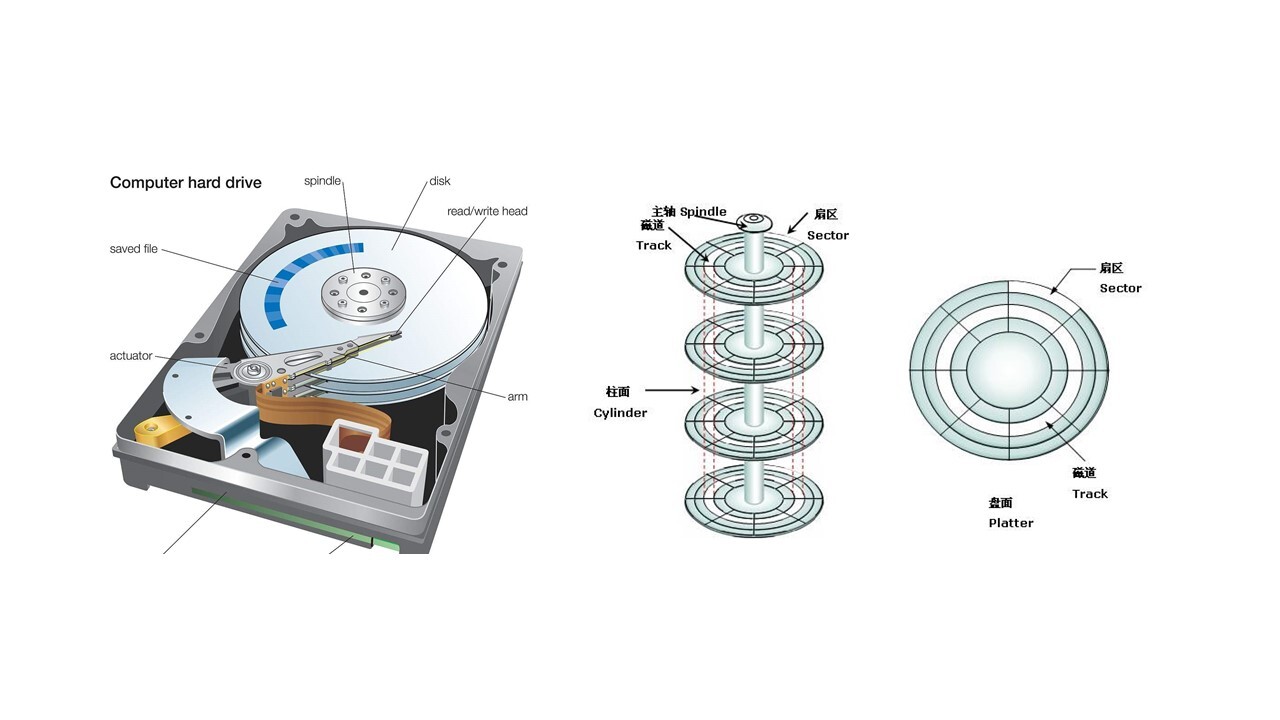
不同硬盘的物理结构可能会有区别,于是 OS 在基本的硬件结构上又抽象出 块 block 的概念。一块的大小是扇区大小的整数倍,默认是 4K。在格式化一个硬盘的时候,这个值是可以设定的。
|
|
因此,从 OS 角度看,硬盘的存储空间被划分为许多个块,这样我们存储一个文件,就不用分配一个连续的空间了。我们可以分散成很多个一个个 block 来存放。
Block 组织方式
我们知道,文件系统的基本单位是 block。数据在磁盘上的存放方式,可以分为:
- 连续空间存放:文件存放在磁盘「连续的」物理空间中
- 非连续空间存放
- 链表方式存放
- 索引方式存放
连续空间存放

- 读写效率高:数据紧密相连,一次磁盘寻道就可以读出所有数据
- 文件头需要指定 起始块的位置 和 长度
- 缺点:
- 存在磁盘空间碎片
- 文件长度不易扩展

链表方式存放
链表的方式存放是离散的,不用连续的,于是就可以消除磁盘碎片,可大大提高磁盘空间的利用率,同时文件的长度可以动态扩展。根据实现的方式的不同,链表可分为「隐式链表」和「显式链接」两种形式。
隐式链表
文件要以「隐式链表」的方式存放的话,实现的方式是文件头要包含「第一块」和「最后一块」的位置,并且每个数据块里面留出一个指针空间,用来存放下一个数据块的位置,这样一个数据块连着一个数据块,从链头开是就可以顺着指针找到所有的数据块,所以存放的方式可以是不连续的。

隐式链表存放方式的缺点在于
- 无法直接访问数据块,只能通过指针顺序访问文件
- 数据块指针消耗了一定的存储空间。
- 分配的稳定性较差,系统在运行过程中由于软件或者硬件错误导致链表中的指针丢失或损坏,会导致文件数据的丢失。
显式链接
如果取出每个磁盘块的指针,把它放在内存的一个表中,就可以解决上述隐式链表的两个不足。那么,这种实现方式是「显式链接」,它指把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
对于显式链接的工作方式,我们举个例子,文件 A 依次使用了磁盘块 4、7、2、10 和 12 ,文件 B 依次使用了磁盘块 6、3、11 和 14 。利用下图中的表,可以从第 4 块开始,顺着链走到最后,找到文件 A 的全部磁盘块。同样,从第 6 块开始,顺着链走到最后,也能够找出文件 B 的全部磁盘块。最后,这两个链都以一个不属于有效磁盘编号的特殊标记(如 -1 )结束。内存中的这样一个表格称为文件分配表(File Allocation Table,FAT)。

由于查找记录的过程是在内存中进行的,因而不仅显著地提高了检索速度,而且大大减少了访问磁盘的次数。但也正是整个表都存放在内存中的关系,它的主要的缺点是不适用于大磁盘。
比如,对于 200GB 的磁盘和 1KB 大小的块,这张表需要有 2 亿项,每一项对应于这 2 亿个磁盘块中的一个块,每项如果需要 4 个字节,那这张表要占用 800MB 内存,很显然 FAT 方案对于大磁盘而言不太合适。
索引方式存放
链表的方式解决了连续分配的磁盘碎片和文件动态扩展的问题,但是不能有效支持直接访问(FAT 除外),索引的方式可以解决这个问题。
索引的实现是
- 为每个文件创建一个「索引数据块」,里面存放的是指向文件数据块的指针列表,说白了就像书的目录一样,要找哪个章节的内容,看目录查就可以。
- 文件头需要包含指向「索引数据块」的指针,这样就可以通过文件头知道索引数据块的位置,再通过索引数据块里的索引信息找到对应的数据块。
创建文件时,索引块的所有指针都设为空。当首次写入第 i 块时,先从空闲空间中取得一个块,再将其地址写到索引块的第 i 个条目。

索引的方式优点在于:
- 文件的创建、增大、缩小很方便;
- 不会有碎片的问题;
- 支持顺序读写和随机读写;
由于索引数据也是存放在磁盘块的:
- 如果文件很小,明明只需一块就可以存放的下,但还是需要额外分配一块来存放索引数据,所以缺陷之一就是存储索引带来的开销。
- 如果文件很大,大到一个索引数据块放不下索引信息,这时又要如何处理大文件的存放呢?我们可以通过组合的方式,来处理大文件的存放。
先来看看链表 + 索引的组合,这种组合称为「链式索引块」,它的实现方式是在索引数据块留出一个存放下一个索引数据块的指针,于是当一个索引数据块的索引信息用完了,就可以通过指针的方式,找到下一个索引数据块的信息。那这种方式也会出现前面提到的链表方式的问题,万一某个指针损坏了,后面的数据也就会无法读取了。

还有另外一种组合方式是索引 + 索引的方式,这种组合称为「多级索引块」,实现方式是通过一个索引块来存放多个索引数据块,一层套一层索引,像极了俄罗斯套娃是吧。

Ext2 方案
那 Ext2 文件系统是组合了前面的文件存放方式的优点,如下图:

它是根据文件的大小,存放的方式会有所变化:
- 如果存放文件所需的数据块小于 12 块,则采用直接查找的方式;
- 如果存放文件所需的数据块超过 12 块,则采用一级间接索引方式;
- 如果前面两种方式都不够存放大文件,则采用二级间接索引方式;
- 如果二级间接索引也不够存放大文件,这采用三级间接索引方式;
那么,文件头(Inode)就需要包含 15 个指针:
- 12 个指向数据块的指针;
- 第 13 个指向索引块的指针;
- 第 14 个指向二级索引块的指针;
- 第 15 个指向三级索引块的指针;
这里的 inode 不是 VFS 的 inode,而是磁盘上面存放的 inode,叫磁盘的索引节点。以 ext2 为例:磁盘索引节点的 inode 有一个 i_block 字段,有 15 个元素:每一个元素指向一个数据块。
|
|
所以,这种方式能很灵活地支持小文件和大文件的存放:
- 对于小文件使用直接查找的方式可减少索引数据块的开销;
- 对于大文件则以多级索引的方式来支持,所以大文件在访问数据块时需要大量查询;
这个方案就用在了 Linux Ext 2/3 文件系统里,虽然解决大文件的存储,但是对于大文件的访问,需要大量的查询,效率比较低。为了解决这个问题,Ext 4 做了一定的改变,具体怎么解决的,本文就不展开了。
空闲空间管理
前面说到的文件的存储是针对已经被占用的数据块组织和管理,接下来的问题是,如果我要保存一个数据块,我应该放在硬盘上的哪个位置呢?难道需要将所有的块扫描一遍,找个空的地方随便放吗?
那这种方式效率就太低了,所以针对磁盘的空闲空间也是要引入管理的机制,接下来介绍几种常见的方法:
- 空闲表法
- 空闲链表法
- 位图法
空闲表法
空闲表法就是为所有空闲空间建立一张表,表内容包括
- 空闲区的第一个块号
- 该空闲区的块个数
注意,这个方式是连续分配的。如下图:

当请求分配磁盘空间时,系统依次扫描空闲表里的内容,直到找到一个合适的空闲区域为止。当用户撤销一个文件时,系统回收文件空间。这时,也需顺序扫描空闲表,寻找一个空闲表条目并将释放空间的第一个物理块号及它占用的块数填到这个条目中。
这种方法仅当有少量的空闲区时才有较好的效果。因为,如果存储空间中有着大量的小的空闲区,则空闲表变得很大,这样查询效率会很低。另外,这种分配技术适用于建立连续文件。
空闲链表法
我们也可以使用「链表」的方式来管理空闲空间,每一个空闲块里有一个指针指向下一个空闲块,这样也能很方便的找到空闲块并管理起来。如下图:

当创建文件需要一块或几块时,就从链头上依次取下一块或几块。反之,当回收空间时,把这些空闲块依次接到链头上。
这种技术只要在内存中保存一个指针,令它指向第一个空闲块。其特点是简单,但不能随机访问,工作效率低,因为每当在链上增加或移动空闲块时需要做很多 I/O 操作,同时数据块的指针消耗了一定的存储空间。
空闲表法和空闲链表法都不适合用于大型文件系统,因为这会使空闲表或空闲链表太大。
位图法
位图是利用二进制的一位来表示磁盘中一个 Block 的使用情况,磁盘上所有的 Block 都有一个二进制位与之对应。
当值为 0 时,表示对应的 Block 空闲,值为 1 时,表示对应的 Block 已分配。它形式如下:
|
|
在 Linux 文件系统就采用了位图的方式来管理空闲空间,不仅用于数据空闲块的管理,还用于 inode 空闲块的管理,因为 inode 也是存储在磁盘的,自然也要有对其管理。
磁盘的组织形式
Disk Layout
前面提到 Linux 是用位图的方式管理空闲空间,用户在创建一个新文件时,Linux 内核会通过 inode 的位图找到空闲可用的 inode,并进行分配。要存储数据时,会通过块的位图找到空闲的块,并分配,但仔细计算一下还是有问题的。
数据块的位图是放在磁盘块里的,假设是放在一个块里,一个块 4K,每位表示一个数据块,共可以表示 4 * 1024 * 8 = 2^15 个空闲块,由于 1 个数据块是 4K 大小,那么最大可以表示的空间为 2^15 * 4 * 1024 = 2^27 个 byte,也就是 128M。
也就是说按照上面的结构,如果采用「一个块的位图 + 一系列的块」,外加「一个块的 inode 的位图 + 一系列的 inode 的结构」能表示的最大空间也就 128M,这太少了,现在很多文件都比这个大。
在 Linux 文件系统,把这个结构称为一个块组,那么有 N 多的块组,就能够表示 N 大的文件。
下图给出了 Linux Ext2 整个文件系统的结构和块组的内容,文件系统都由大量块组组成,在硬盘上相继排布:

最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
- super block: 保存在全局的 super block 结构中, 描述了整个文件系统在磁盘中的信息
- block group descriptor: 包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
- data block bitmap:来表示这些 block 是否占用,它在改变文件大小、创建、删除等操作时,都会改变
- inode bitmap:文件系统使用该 bitmap 来标识,inode table 里面的 inode 是否使用
- inode table : 存放 inode 表,每一个 inode 项代表一个文件,里面存放文件的元信息
- data blocks: 存放文件数据的区域
你可以会发现每个块组里有很多重复的信息,比如超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。
Super Block 结构
每个文件系统有其各自的属性,它通过 Super Block 来描述文件系统在磁盘中的控制信息,包括文件系统的状态、类型、大小、区块数、索引节点数等。每次一个实际的文件系统被安装时, 内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。
|
|
SuperBlock 的重要成员有
- 链表
s_list,包含所有修改过的 Inode,使用该链表很容易区分出来哪个文件被修改过,并配合内核线程将数据写回磁盘 - 操作函数
s_op,定义了针对其 Inode 的所有操作方法,例如标记、释放索引节点等一系列操作 s_type,记录它所属的文件系统类型s_root,本文件系统的根目录
Super Block Operations
|
|
文件的具体组成
Inode
如果一个文件的数据被分到很多个 block 中,那么我们应该如何去寻找这些 block 呢?这需要维护一个索引区域,记录着这个文件分成多少个块,每个块在哪里的信息。另外,文件还包括 meta data,比如文件名和权限等。在内核中有 inode 数据结构 记录了这些信息:
|
|
Inode Operations
|
|
ICache
INode 存储的数据存放在磁盘上,由具体的文件系统进行组织,当需要访问一个 INode 时,会由文件系统从磁盘上加载相应的数据并构造 INode。一个 INode 可能被多个 DEntry 所关联,即相当于为某一文件创建了多个文件路径(通常是为文件建立硬链接)。
硬盘里的 inode diagram 里的数据结构,在内存中会通过 slab 分配器,组织成 xxx_inode_cache,统计在 meminfo 的可回收的内存中。 inode 表也会记录每一个 inode 在硬盘中摆放的位置。这里所说的索引节点高速缓存也就是我们常说的 icache.
|
|
Directory Entry
文件路径中,每一部分都被称为目录项。/home/jie/vfs.c 中,目录 /、home、 jie 和文件 vfs.c 对应了一个目录项。
注意区分目录项和目录,目录在文件系统里面也是一个文件,但是它是一个特殊的文件,文件的内容是一个 inode 号和名字的映射表格

目录在硬盘里是一个特殊的文件。目录在硬盘中也对应一个 inode,记录文件的名字和 inode 号。查找一个文件时(/home/vfs.c),根据文件系统的根据根目录和根 inode,找到根目录所在硬盘的位置,将根目录的文件读出来,再去做字符串匹配,能够找到 home 这个字符串, 于是就再去读 home 这个目录对应的 inode 的文件内容,再做字符串匹配,然后就找到了vfs.c 。最后发现 vfs.c 是一个常规文件,返回他的 inode 即可。(上一小节在讲解 inode 的时候说过,通过 inode 就可以表示整个文件的元信息,数据内容等)
目录文件在磁盘中存放的内容:

DEntry 用来保存文件路径和 INode 之间的映射,从而支持在文件系统中移动。DEntry 由 VFS 维护,所有文件系统共享,不和具体的进程关联。dentry对象从根目录 / 开始,每个dentry对象都会持有自己的子目录和文件,这样就形成了文件树。举例来说,如果要访问 /home/houmin/a.txt 文件并对他操作,系统会解析文件路径,首先从/ 根目录的dentry对象开始访问,然后找到 home/ 目录,其次是 houmin/,最后找到 a.txt 的dentry结构体,该结构体里面d_inode字段就对应着该文件。
下面是 DEntry 的数据结构:
|
|
每一个dentry对象都持有一个对应的inode对象,表示 Linux 中一个具体的目录项或文件。INode 包含管理文件系统中的对象所需的所有元数据,以及可以在该文件对象上执行的操作。
DEntry Operations
|
|
DCache
虚拟文件系统维护了一个 DEntry Cache 缓存,用来保存最近使用的 DEntry,加速查询操作。DEntry 对象都放在名为 dentry_cache 的 slab 分配器高速缓存中。
当调用open()函数打开一个文件时,内核会第一时间根据文件路径到 DEntry Cache 里面寻找相应的 DEntry,找到了就直接构造一个file对象并返回。如果该文件不在缓存中,那么 VFS 会根据找到的最近目录一级一级地向下加载,直到找到相应的文件。期间 VFS 会缓存所有被加载生成的dentry。
管理目录项高速缓存的数据结构有两个:
- 一个是处于正在使用、未使用或负状态的目录项对象的集合。这用的是双向链表。
- 一个叫
dentry_hashtable的散列表,从中能够快速获取与给定的文件名和目录名对应的目录项对象。
如下是 初始化目录项对象的代码:
|
|
在内核中,并不丢弃与未用目录项相关的索引节点,这是由于目录项高速缓存仍在使用它们。
File
文件对象表示进程已打开的文件。用户看到最多的就是它,包含文件对象的使用计数、用户的 UID 和 GID 等。它存放了打开文件与进程之间进行交互的信息,这类信息仅当进程访问文件期间存在与内核内存中。

每个进程都持有一个 files_struct 指针,存放的是指该进程打开的 file 结构体的指针:
|
|
这个 files_struct 有一个 fd_array,里面的每个元素是一个 file 对象,记录了打开的文件:
|
|
file是 内核中的数据结构,表示一个被进程打开的文件,和进程相关联。当应用程序调用open()函数的时候,VFS 就会创建相应的file对象。它会保存打开文件的状态,例如文件权限、路径、偏移量等等。Linux 文件系统会为每个文件都分配两个数据结构,目录项(DEntry, Directory Entry)和索引节点(INode, Index Node)。
|
|
从上面的代码可以看出,文件的路径实际上是一个指向 DEntry 结构体的指针,VFS 通过 DEntry 索引到文件的位置。
除了文件偏移量f_pos是进程私有的数据外,其他的数据都来自于 INode 和 DEntry,和所有进程共享。不同进程的file对象可以指向同一个 Dentry 和 Inode,从而实现文件的共享。
文件系统是对一个存储设备上的数据和元数据进行组织的机制,由于定义如此宽泛,各个文件系统的实现也大不相同,其中常见的文件系统有 ext4、NFS、/proc 等。Linux 采用为分层的体系结构,将用户接口层、文件系统实现和存储设备的驱动程序分隔开,进而兼容不同的文件系统。
虚拟文件系统(Virtual File System, VFS)是 Linux 内核中的软件层,它在内核中提供了一组标准的、抽象的文件操作,允许不同的文件系统实现共存,并向用户空间程序提供统一的文件系统接口。下面这张图展示了 Linux 虚拟文件系统的整体结构:

从上图可以看出,用户空间的应用程序直接、或是通过编程语言提供的库函数间接调用内核提供的 System Call 接口(如open()、write()等)执行文件操作。System Call 接口再将应用程序的参数传递给虚拟文件系统进行处理。
每个文件系统都为 VFS 实现了一组通用接口,具体的文件系统根据自己对磁盘上数据的组织方式操作相应的数据。当应用程序操作某个文件时,VFS 会根据文件路径找到相应的挂载点,得到具体的文件系统信息,然后调用该文件系统的对应操作函数。
VFS 提供了两个针对文件系统对象的缓存 INode Cache 和 DEntry Cache,它们缓存最近使用过的文件系统对象,用来加快对 INode 和 DEntry 的访问。Linux 内核还提供了 Buffer Cache 缓冲区,用来缓存文件系统和相关块设备之间的请求,减少访问物理设备的次数,加快访问速度。Buffer Cache 以 LRU 列表的形式管理缓冲区。
VFS 的好处是实现了应用程序的文件操作与具体的文件系统的解耦,使得编程更加容易:
- 应用层程序只要使用 VFS 对外提供的
read()、write()等接口就可以执行文件操作,不需要关心底层文件系统的实现细节; - 文件系统只需要实现 VFS 接口就可以兼容 Linux,方便移植与维护;
- 无需关注具体的实现细节,就实现跨文件系统的文件操作。
了解 Linux 文件系统的整体结构后,下面主要分析 Linux VFS 的技术原理。
符号链接和硬链接
符号链接
符号链接是 linux 中是真实存在的实体文件,文件内容指向其他文件。符号链接和文件是不同的 inode。
如下图所示:cbw_file 和 my_file 指向不同的 inode. 但是 cbw_file 的文件内容指向了 my_file 的 inode

符号链接特性:
- 针对目录的软链接,用 rm -fr 删除不了目录里的内容
- 针对目录的软链接,”cd ..”进的是软链接所在目录的上级目录
- 可以对文件执行 unlink 或 rm,但是不能对目录执行 unlink
硬链接
硬链接在硬盘中是同一个 inode 存在,在目录文件中多了一个目录和该 inode对应。
硬链接特性
- 硬链接不能跨本地文件系统
- 硬链接不能针对目录
文件缓存
关于文件系统的相关的缓存,前面我们讲到了 icache 以及 dcache. 其实还有一个文件内容的缓存叫 page cache. 那么他是存放在哪里的呢? 我们下面简单来看一下。当打开一个文件后,内核中会为struct fille建立如下的映射关系:图中描述了 struct file、inode、dentry、address_space 之间的关系:
我们通过 file 结构体按照图中箭头指向,可以一步一步找到 page cache. 或者是发起 IO 操作。

上图中的 radix tree 里面的内容就是文件的 page cache. 其中索引值是需要访问的数据在文件里面的偏移量, 关于 radix tree 更详细的信息,请参考:: 页高速缓存。
其中 i_fop(struct file_operations)和 a_ops(struct address_space_operations)的关系是, i_fop 是 hook 到虚拟文件系统中的,a_ops 完成 page cache 的访问,包括 page cache 不存在的时候,发起 IO 请求等操作。
代码只是列举一下,不感兴趣的直接忽略掉。
|
|
处于 ext2 文件系统下的文件对 a_ops 的赋值为:
|
|
读取文件的时候有如下流程:伪代码如下:
|
|
这里我们第一次见到了 IO , 实际上IO就是从a_ops->readpage或者a_ops->wirtepage函数触发的。 关于 IO 流程,请参考其他文章。后面我会梳理一下 IO 流程, 这里不再过多的阐述。
文件系统
关于文件系统的三个易混淆的概念:
- 创建:以某种方式格式化磁盘的过程就是在其之上建立一个文件系统的过程。创建文件系统时,会在磁盘的特定位置写入关于该文件系统的控制信息。
- 注册:向内核报到,声明自己能被内核支持。一般在编译内核的时侯注册;也可以加载模块的方式手动注册。注册过程实际上是将表示各实际文件系统的数据结构
struct file_system_type实例化。 - 挂载:也就是我们熟悉的 mount 操作,将文件系统加入到 Linux 的根文件系统的目录树结构上;这样文件系统才能被访问。
文件系统创建
以某种方式格式化磁盘的过程就是在其之上建立一个文件系统的过程。创建文件系统时,会在磁盘的特定位置写入关于该文件系统的控制信息。用指定文件系统格式话磁盘分区后。磁盘上被格式化的分区如下图所示:

下图是组描述符的缓存示意图:

文件系统的注册
文件系统注册就是文件系统向内核报到,声明该文件系统能被内核支持,一般是在内核的初始化阶段完成或者在文件系统内核模块初始化函数中完成注册。如下是 ext2 文件系统初始化时候的注册:
|
|
注册文件系统就是将该文件系统挂载到 file_systems 链表中,以供后续使用。如下图所示:

|
|
文件系统的挂载
文件系统加入到 Linux 的根文件系统的目录树结构上,这样文件系统上面的文件才能被访问。在内核中描述文件系统的文件系统描述符为如下代码块的结构体所示:
|
|
一个vfs_mount可以理解为一个文件系统的实例。它有挂载点、有挂载点的 dentry 项等、同一个文件系统可以有多个 vfs_mount 实例。也就是同一个文件系统可以被安装多次。例如:/home/test1 、/home/jie/test2、这两个目录可以 mount 同一种文件系统,假设均为 ext2,实际上就是有了 ext2 文件系统的两个实例。对于每个安装操作(mount), 内存里面都需要保存安装点、安装标记、以及已安装文件系统与其他文件系统之间的关系(是否挂在其他文件系统下等)。
|
|
mount 的过程就是把 设备的文件系统 加入到 vfs 框架中
- 首先,要 mount 一个新的设备,需要创建一个新的 super block。 这通过要 mount 的文件系统的 file_system_type, 调用其
get_sb方法来创建一个新的 super block。 - 需要创建一个新的
vfsmount,对于任何一个 mount 的文件系统,都要有一个 vfsmount, 创建这个 vfsmount, 并设置好 vfsmount 中的各个成员 - 将创建好的 vfsmount 加入到系统中,对于新的 vfsmount:
- 其 mount_point 为目录 “my” 的 dentry,
- 其 mnt_root 是设备 sdb1 上的根目录的 dentry
- 其父 vfsmount 就是原文件系统中的那个 vfsmount
syscall
|
|
do_mount
**do_mount()**函数是 mount 操作过程中的核心函数,在该函数中,通过 mount 的目录字符串找到对应的 dentry 目录项,然后通过 do_new_mount()函数完成具体的 mount 操作。
do_new_mount
do_new_mount() 函数主要分成两大部分:
- 建立 vfsmount 对象和 superblock 对象,必要时从设备上获取文件系统元数据
- 将 vfsmount 对象加入到 mount 树和 Hash Table 中,并且将原来的 dentry 对象无效掉
|
|
vfs_create_mount
|
|
vfs_kern_mount 先是创建 struct mount 结构,每个挂载的文件系统都对应于这样一个结构。
|
|
- mnt_parent 是装载点所在的父文件系统
- mnt_mountpoint 是装载点在父文件系统中的 dentry;
- mnt_root 是当前文件系统根目录的 dentry
- mnt_sb 是指向超级块的指针。接下来,我们来看调用 mount_fs 挂载文件系统。
文件操作
路径名查找
如下图所示,当你在硬盘查找 /usr/bin/emacs 文件时:
- 从根的 inode 和 dentry,根据/的 inode 表,找到/ 目录文件所在的硬盘中的位置
- 读硬盘/目录文件的内容,发现 usr 对应 inode 2, bin 对应 inode 3, share 对应 inode4。
- 再去查 inode 表,inode 2 所在硬盘的位置,即/usr 目录文件所在硬盘的位置。
- 读出内容包括 var 对应 inode 10, bin 对应 inode 11, opt 对应 inode 12。
- 于是又去找 inode 11 所在的磁盘位置,emacs 对应的 inode 是 119.
- 我们现在就找到了 119 这个 inode,它就对应了 /usr/bin/emacs 这个文件
- 这个过程会查找很多 inode 和 dentry,这些都会通过 icache 和 dcache 缓存。

前面我们讲了很多文件系统的创建、注册、挂载,那么和我们的路径查找有什么关系呢,关系大着呢。每当我们搜索到目录项对象的时候,如果 dentry->d_mounted 大于 1 的话,说明该目录项被文件系统挂载,那么需要调用lookup_mnt()查找 vfs_mount. 并切换文件系统,这样就会找到新的文件系统的根 dentry 项以及对应的 inode 项。如果没有切换文件系统的,那么是无法继续解析下去的。试想一下,挂载点下面文件都是存放在 ext4 文件系统下的,文件也是按 ext4 文件系统去组织的。这个时候你还是按上一个目录的文件系统,比如 exfat 去解析后面的文件,肯定是解析不了的。
路径名查找完成后,将找到的文件的 dentry 以及 inode 对应的 f_ops 赋值给 struct file 结构体, 系统调用返回文件描述符给应用成,这个时候我们就可以操作通过 fd(文件描述符)号先找到 struct file, 顺藤摸瓜,可以找到对应文件的 inode。
读写文件过程
进程通过 task_struct 中的一个域 files_struct files 来了解它当前所打开的文件对象;而我们通常所说的文件 描述符其实是进程打开的文件对象数组的索引值。文件对象通过域 f_dentry 找到它对应的 dentry 对象,再由 dentry 对象的域 d_inode 找 到它对应的索引结点,这样就建立了文件对象与实际的物理文件的关联。最后,还有一点很重要的是, 文件对象所对应的文件操作函数列表是通过索引结点的域 i_fop 得到的。如下图所示:

如下图所示:通过文件描述符 fd 我们可以找到具体文件的 inode 的文件描述符,通过注册的回调函数 a_ops 以及 page cache. 我们就可以实际的读写文件的内容了。
特殊文件系统操作
套接字以及 pipe、netlink 等文件在磁盘中没有内容,他们的 inode 只有 VFS 中的 inode。下面我们以套接字为例,说明 linux 是如何处理这种特殊的文件系统的。
- 在内核初始化时完成
- 内核初始化过程(/init/main.c):
kernel_init()-> do_basic_setup()-> do_initcalls()-> do_one_initcall(); - socket 文件系统注册过程(/net/socket.c):
core_initcall(sock_init);
core_initcall 宏定义如下:
|
|
宏定义 __define_initcall(level,fn, id) 对于内核的初始化很重要,他指示编译器在编译的时候,将一系列初始化函数的起始地址值按照一定的顺序放在一个 section 中。
在内核初始化阶段,do_initcalls() 将按顺序从该 section 中以函数指针的形式取出这些函数的起始地址,来依次完成相应的初始化。由于内核某些部分的初始化需要依赖于其他某些部分的初始化的完成,因此这个顺序排列常常很重要。该宏的作用分三部分:
- 申明一个函数指针
initcall_t,即 int *(void))变量__initcall_fn_id; - 将该函数指针初始化为 fn;
- 编译的时候需要把这个函数指针变量放置到名称为 “.initcall"level”.init"的 section 中;
根据上面的解释,core_initcall(sock_init) 的作用就是让编译器在编译时声明函数指针变量 __initcall_sock_init1,让其指向 sock_init,并放到名为.initcall1.init 的 section 中;
sockfs 注册
可以看到 sockfs 也有对应的 file_system_type:
|
|
会在内核初始化的时候初始化 sockfs,在这个函数中,将 socket 注册为一个伪文件系统,并安装相应的 mount 点:
|
|
- init_inodecache():创建一块用于 socket 相关的 inode 的调整缓存;后面创建 inode、释放 inode 会使用到;
- register_filesystem():将 socket 文件系统注册到内核中;
- 在内核中,所有的文件系统保存在全局变量 file_systems 中,如下:
|
|
不同的文件系统类型通过结构体的 next 字段形成一个单向链表;这样,注册文件系统实质是将新的结构体插入到单向链表中的过程;
- kern_mount():在内核中安装文件系统,并建立安装点;
在安装的过程中,会初始化该安装点的超级块,此时会将该超级块的操作函数指针记录下来;如:
|
|
其中 sockfs_ops 结构变量如下:
|
|
该操作函数结构体定义了如何分配 inode,如何销毁 inode 等;
套接字的打开 socket
socket
|
|
sock_create
sock_create(family, type, protocol, &sock);
- 协议栈相关的创建 ,其实就是一个 create 函数,inet 协议栈就是 inet_create,如果是 netlink 就是 netlink 的 creat 函数
- 根据 protocol 注册不同的回调函数,那么就可以使用 udp、tcp 了,并分配函数接收的收包和发包函数

sock_map_fd
sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));

读写套接字
内核建立起了虚拟文件系统和套接字的映射关系后,那么直接调用 write、read 等函数就可以操作和读写套接字。

对于套接字 f_op 被初始化为socket_file_ops:
|
|
socket_file_ops为如下定义:
|
|
其中sock_aio_read、sock_aio_write、sock_readv、sock_writev等函数会调用到具体协议的读写函数、比如 udp 就是调用到 udp 的函数、tcp 就调用到 tcp 的函数,这一切的映射关系是根据套接字建立的时候根据传入的 family、type、protocol 这几次参数决定的。
References
-
No backlinks found.