KVM

KVM 是 Linux 下基于Intel VT或AMD-V 等 CPU 硬件虚拟化技术 实现的虚拟化解决方案,全称为 Kernel-based Virtual Machine。KVM 由处于内核态的 KVM 模块kvm.ko和用户态的 QEMU 两部分构成。内核模块kvm.ko实现了 CPU 和内存虚拟化 等决定关键性能和核心安全的功能,并向用户空间提供了使用这些功能的接口,QEMU 利用 KVM 模块提供的接口来实现设备模拟、I/O 虚拟化和网络虚拟化等。单个虚拟机是宿主机上的一个普通 QEMU 进程,虚拟机中的 vCPU是 QEMU 的一个线程,VM 的物理地址空间是 QEMU 的虚拟地址空间。
技术背景
在 虚拟化概览 中介绍了 虚拟化准则,提出 VMM 应当满足的三个条件,并提出了两种类型的 VMM:
- Resource Control,控制程序必须能够管理所有的系统资源。
- Equivalence,在控制程序管理下运行的程序(包括操作系统),除时序和资源可用性之外的行为应该与没有控制程序时的完全一致,且预先编写的特权指令可以自由地执行。
- Efficiency,绝大多数的客户机指令应该由主机硬件直接执行而无需控制程序的参与。

QEMU-KVM
KVM 是必须依赖硬件虚拟化技术辅助(例如 Intel VT-x、AMD-V)的 Hypervisor:
- CPU:有 VMX root 和 non-root 模式的支持,其运行效率是比较高的
- 内存:有 Intel EPT/AMD NPT 的支持,内存虚拟化的效率也比较高
- I/O:KVM 客户机的 I/O 操作需要
VM-Exit到用户态由 QEMU 进行模拟- 传统的方式是使用纯软件的方式来模拟 I/O 设备,效率并不高
- 现在应用最为广泛的 I/O 虚拟化是 virtio,可以参考 半虚拟化 I/O 框架 Virtio
作为一个Hypervisor,KVM 本身只关注虚拟机调度和内存管理 这两个方面,I/O 外设 的任务就交给了 Linux 内核 和 QEMU。
KVM 将整个虚拟化应用抽象成三层:
- KVM 包含了一个内核加载模块
kvm.ko,它只会负责提供vCPU以及对虚拟内存进行管理和调度 /dev/kvm是 KVM 内核模块提供给用户空间的一个接口,这个接口被qemu-kvm调用,通过ioctl系统调用就可以给用户提供一个工具,用以创建、删除、管理虚拟机- VM 运行期间,QEMU 会通过
kvm.ko模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于特殊模式运行 - QEMU-KVM 是 KVM 团队通过修改 QEMU 代码而得出的专门用来创建和管理虚拟机的管理工具,为的是 KVM 能更好的和内核打交道
qemu-kvm就是通过open()、close()、ioctl()等方法去打开、关闭和调用这个接口,从而实现与 KVM 的互动
|
|
Guest 特点
Guest作为一个普通进程运行于宿主机Guest的 CPU(vCPU)作为进程的线程存在,并受到宿主机内核的调度Guest继承了宿主机内核的一些属性,例如Huge PagesGuest的 磁盘 I/O 和 网络 I/O 会受到宿主机设置的影响Guest通过宿主机上的虚拟网桥与外部相连
每一个虚拟机Guest在Host上都被模拟为一个 QEMU 进程,即emulation进程。创建虚拟机后,使用virsh命令即可查看:
|
|
可以看到,此虚拟机就是一个普通的 Linux 进程,有自己的PID,并且有四个线程。线程数量不是固定的,但是至少会有三个(vCPU、I/O、Signal)。其中有两个是vCPU线程,一个I/O线程,还有一个Signal信号处理线程。
|
|
KVM 整体架构

CPU 虚拟化
在 虚拟化技术概览 中介绍了 CPU 虚拟化的三种技术方案,这里总结如下:
| 全虚拟化 | 半虚拟化 | 硬件辅助虚拟化 | |
|---|---|---|---|
| 实现 | 动态二进制翻译、优先级压缩 | HyperCall | VMX 模式切换 |
| 兼容性 | 不修改内核,兼容性好 | 需要定制 GuestOS 内核,不支持 Windows,兼容性差 | 修改内核,兼容性好 |
| 性能 | 步骤繁琐,性能差 | 性能好 | 较好,接近半虚拟化 |
| 厂商 | VMware、QEMU | Xen | KVM、VMware ESXi、Xen 3.0 等 |
在 KVM 中,使用的是硬件辅助虚拟化技术。
创建 vCPU
前文有提及 IOCTL 命令控制虚拟机,这里我们以 kvm_vm_ioctl 作为入口函数分析,看虚拟机如何创建 vCPU。
|
|
通过接受 ioctl 的 CPU 创建指令,执行 kvm_vm_ioctl_create_vcpu,紧接着,会先后执行 kvm_arch_vcpu_create 和 kvm_arch_vcpu_setup
|
|
kvm_arch_vcpu_create 主要负责:
- 为结构体
kvm_vcpu分配内存空间(这个数据结构表示一个 VCPU 描述符,所有对 VCPU 的操作都是对该数据结构相应字段的设置) - 对 vmcs 结构初始化(Virtual-Machine Control Structure, 该结构记录了 cpu 切换的上下文环境,帮助 cpu 在做 VM-entry 和 VM-exit 时保存信息)
- 其他寄存器初始化
|
|
kvm_arch_vcpu_setup 主要负责:
- 为 vcpu 对应的 vmcs 绑定当前 cpu
- 初始化虚拟 MMU 部件
VM-entry
当接受 ioctl 入口函数收到的虚拟机运行的指令时,会通过 kvm_arch_vcpu_ioctl_run->__vcpu_run->vcpu_enter_guest 的路径进入到 vcpu_enter_guest 函数。
在一系列操作后会执行 kvm_x86_ops->run,这个函数在初始化时,映射成了另外一个函数 vmx_vcpu_run,该函数做如下操作:
- 记录进入 Guest 时间
- 保存 host 寄存器信息
- 加载 Guest 寄存器信息
- 通过 VMLAUNCH 或 VMRESUME 进入 Guest(汇编指令)
VM-exit
在 vmx_vcpu_run 的函数中会因为接受到中断、异常或主动调用 VMCall 导致退出,vmx_complete_interrupts 函数即通过中断退出。vmx_complete_interrupts 函数中会对中断类型做判断,如软中断、硬中断、软件异常、硬件异常等做相应处理。
内存虚拟化
为了实现内存虚拟化,让Guest使用一个隔离的、从零开始且连续的内存空间,KVM 引入了一层新的地址空间,即客户机物理地址空间(Guest Physical Address,GPA)。这个地址空间并不是真正的物理地址空间,它只是Host虚拟地址空间在Guest地址空间的一个映射。对客户机来说,客户机物理地址空间都是从零开始的连续地址空间。但对宿主机来说,客户机的物理地址空间并不一定是连续的,客户机物理地址空间有可能映射在若干个不连续的宿主机地址区间,如下图所示:
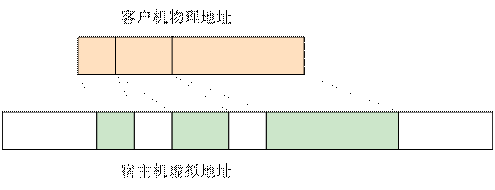
为了将客户机物理地址转换成宿主机虚拟地址(Host Virtual Address,HVA),KVM 用一个kvm_memory_slot数据结构来记录每一个地址区间的映射关系,此数据结构包含了对应此映射区间的起始客户机页帧号(Guest Frame Number,GFN)、映射的内存页数目以及起始宿主机虚拟地址,从而实现 GPA 到 HPA 的转换。
实现内存虚拟化,最主要的是实现客户机虚拟地址GVA到宿主机物理地址HPA之间的转换。如果通过之前提到的两步映射的方式,客户机的每次内存访问都需要 KVM 介入,并由软件进行多次地址转换,其效率是非常低的。
因此,为了提高GVA到HPA的转换效率,KVM 提供了两种实现方式来进行GVA到HPA之间的直接转换:
- 影子页表(Shadow Page Table)
- 基于硬件对虚拟化的支持:EPT
在 虚拟化技术概览 中可以看到对这两种技术的详细介绍。
EPT 的入口处理函数是 handle_ept_violation,该函数会依次调用 kvm_mmu_page_fault-»vcpu->arch.mmu.page_fault(该函数实际是执行 tdp_page_fault)。
tdp_page_fault 函数主要做几件事情:
- 为核心结构体 kvm_mmu_page 等申请内存(kvm_mmu_page 表示一个 EPT 中的页表页)
- 如果没有 kvm_memory_slot 映射 pfn,则申请空闲 kvm_memory_slot(kvm_memory_slot,客户机可根据页表实现 GVA 到 GPA 转换,再通过 kvm_memory_slot 实现 GPA 转换成 HVA,可根据宿主机的页表实现 GPA 转 HPA,进而完成 GVA 到 HPA 转换)
- 做 EPT 缺页处理,建立 gfn 和 pfn 映射关系(gfn (Guest Frame Number)起始客户机页帧号,pfn(Page Frame Number)物理页页帧号)
EPT 页表页结构如下:
- EPT 的页表结构分为四层(PML4(level-4)、PDPT(level-3)、PD(level-2)、PT(level))
- EPT Pointer (EPTP)指向 PML4 的首地址
- gpa 到 hpa:gpa 通过四级页表的寻址,得到相应的 pfn,然后加上 gpa 最后 12 位的 offset,得到 hpa
- 物理页(physical page)是真正存放数据的页,页表页(MMU page)是存放 EPT 页表的页
- 每个页表页(MMU page)对应一个数据结构 kvm_mmu_page
I/O 虚拟化
I/O 虚拟化现在主流三种方案如下,在 虚拟化技术概览 中可以看到对这两种技术的详细介绍。
- 全虚拟化:完全由 QEMU 软件模拟
- 半虚拟化:借助 virtio 实现
- PCI pass-through:直接通过 PCI 直连设备
Guest虽然作为一个进程存在,但其内核的所有驱动都依然存在。只是硬件设备由 QEMU 模拟。Guest的所有硬件操作都会由 QEMU 来接管,QEMU 负责与真实的宿主机硬件打交道。
-
No backlinks found.