Device Plugin
Kubernetes 原生支持对于CPU和内存资源的发现,但是有很多其他的设备 kubelet不能原生处理,比如GPU、FPGA、RDMA、存储设备和其他类似的异构计算资源设备。为了能够使用这些设备资源,我们需要进行各个设备的初始化和设置。按照 Kubernetes 的 OutOfTree 的哲学理念,我们不应该把各个厂商的设备初始化设置相关代码与 Kubernetes 核心代码放在一起。与之相反,我们需要一种机制能够让各个设备厂商向 Kubelet 上报设备资源,而不需要修改 Kubernetes 核心代码。这即是 Device Plugin 这一机制的来源,本文将介绍 Device Plugin 的实现原理,并介绍其使用。
Device 插件原理
Device Plugin 实际上是一个 gPRC server,Device 插件一般推荐使用 DaemonSet 的方式部署,并将 /var/lib/kubelet/device-plugins 以 Volume 的形式挂载到容器中。当然,也可以手动运行的方式来部署,但这样就没有失败自动恢复的功能了。
为了能够使用某个厂商的特定设备,一般有两步:
kubectl create -f http://vendor.com/device-plugin-daemonset.yaml- 执行
kubectl describe nodes的时候,相关设备会出现在node status中:vendor-domain/vendor-device
当 Device Plugin 向 kubelet 注册后,kubelet 就通过 RPC 与 Device Plugin 交互:
ListAndWatch():让 kubelet 发现设备资源和对应属性,并且在设备资源发生变动的时候接收通知Allocate():kubelet 在创建容器前通过 Allocate来申请相关设备资源

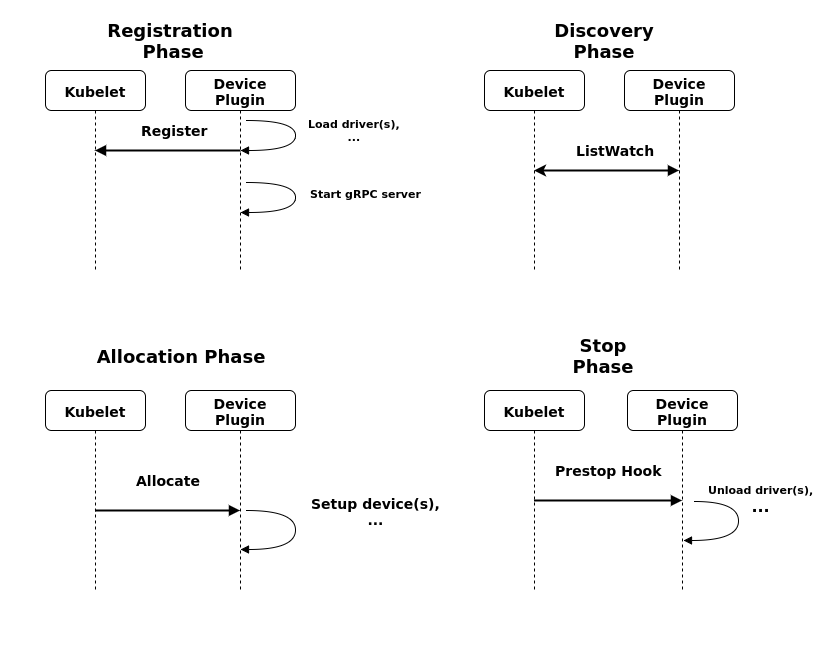
Registration
为了向 kubelet 告知 Device Plugin 的存在,Device Plugin 必须向 kubelet 发出注册请求,这之后 kubelet 才会和 Device Plugin 通过 gRPC交互,具体过程如下:
- Device Plugin 向 Kubelet 发送一个
RegisterRequest的请求 - Kubelet 收到
RegisterRequest请求后,返回一个RegisterResponse,如果Kubelet碰到任何错误,会把错误附在Response中 - 如果 Device Plugin 没有收到任何错误,则启动他的 gRPC server
插件启动后要持续监控 Kubelet 的状态,并在 Kubelet 重启后重新注册自己。比如,Kubelet 刚启动后会清空 /var/lib/kubelet/device-plugins/ 目录,所以插件作者可以监控自己监听的 unix socket 是否被删除了,并根据此事件重新注册自己
Unix Socket
Device Plugin 和 Kubelet 通过在一个 Unix Socket上使用 gRPC 交互,当启动 gRPC server的时候,Device Plugin 将会在 /var/lib/kubelet/device-plugins/ 这个 HostPath 创建一个 UnixSocket,比如 /var/lib/kubelet/device-plugins/nvidiaGPU.sock。
在实现 Device 插件时需要注意
- 插件启动时,需要通过
/var/lib/kubelet/device-plugins/kubelet.sock向 Kubelet 注册,同时提供插件的 Unix Socket 名称、API 的版本号和插件名称(格式为vendor-domain/resource,如nvidia.com/gpu)。Kubelet 会将这些设备暴露到 Node 状态中,方便后续调度器使用 - 插件启动后向 Kubelet 发送插件列表、按需分配设备并持续监控设备的实时状态
Protocol Overview
API specification
|
|
插件生命周期管理
插件启动时,以grpc的形式通过/var/lib/kubelet/device-plugins/kubelet.sock向Kubelet注册,同时提供插件的监听Unix Socket,API版本号和设备名称(比如nvidia.com/gpu)。Kubelet将会把这些设备暴露到Node状态中,以Extended Resource的要求发送到API server中,后续Scheduler会根据这些信息进行调度。
插件启动后,Kubelet会建立一个到插件的listAndWatch长连接,当插件检测到某个设备不健康的时候,就会主动通知Kubelet。此时如果这个设备处于空闲状态,Kubelet就会将其挪出可分配列表;如果该设备已经被某个pod使用,Kubelet就会将该Pod杀掉
插件启动后可以利用Kubelet的socket持续检查Kubelet的状态,如果Kubelet重启,插件也会相应的重启,并且重新向Kubelet注册自己
NVIDIA Device Plugin
NVIDIA 提供了一个基于 Device Plugins 接口的 GPU 设备插件 NVIDIA/k8s-device-plugin。
部署
|
|
创建 Pod 时请求 GPU 资源
|
|
注意:使用该插件时需要配置 nvidia-docker 2.0,并配置 nvidia 为默认运行时 (即配置 docker daemon 的选项 --default-runtime=nvidia)。nvidia-docker 2.0 的安装方法为(以 Ubuntu Xenial 为例,其他系统的安装方法可以参考 这里):
整个Kubernetes调度GPU的过程如下:
- GPU Device plugin 部署到GPU节点上,通过
ListAndWatch接口,上报注册节点的GPU信息和对应的DeviceID。 - 当有声明
nvidia.com/gpu的GPU Pod创建出现,调度器会综合考虑GPU设备的空闲情况,将Pod调度到有充足GPU设备的节点上。 - 节点上的kubelet 启动Pod时,根据request中的声明调用各个Device plugin 的 allocate接口, 由于容器声明了GPU。 kubelet 根据之前
ListAndWatch接口收到的Device信息,选取合适的设备,DeviceID 作为参数,调用GPU DevicePlugin的Allocate接口 - GPU DevicePlugin ,接收到调用,将DeviceID 转换为
NVIDIA_VISIBLE_DEVICES环境变量,返回kubelet - kubelet将环境变量注入到Pod, 启动容器
- 容器启动时,
gpu-container-runtime调用gpu-containers-runtime-hook gpu-containers-runtime-hook根据容器的NVIDIA_VISIBLE_DEVICES环境变量,转换为--devices参数,调用nvidia-container-cli prestartnvidia-container-cli根据--devices,将GPU设备映射到容器中。 并且将宿主机的Nvidia Driver Lib 的so文件也映射到容器中。 此时容器可以通过这些so文件,调用宿主机的Nvidia Driver。
在前面 API Specification 中,通过 Protobuf 定义了 DevicePlugin 应该提供的服务,在 Kubelet 中会调用 DevicePluginClient 来使用对应的服务,这里的 DevicePluginClient 即是通过 Protobuf 自动生成的代码。
|
|
在 NVIDIA/k8s-device-plugin 中,我们可以看到上面不同服务的具体实现:
|
|
对 NVIDIA/k8s-device-plugin 来说,这里的关键数据结构为 NvidiaDevicePlugin,它实现了 Device Plugin 架构定义的API:
|
|
下面根据 Device Plugin 的生命周期,依次分析每个部分的实现机制。
NVIDIA DevicePlugin 启动
NVIDIA 的 k8s-device-plugin 启动之后逻辑如下,总的来说干了三件事:
- Serve:启动
gRPC server - Register:向
Kubelet注册给定的resourceName - CheckHealth:执行设备的健康检查逻辑,当检查到不健康的设备时,写到
unhealthy的 channel 中
|
|
Serve
Serve 监听在 /var/lib/kubelet/device-plugins/nvidia-gpu.sock 这 个 Unix Socket,并且启动了 gRPC server,其他的就是启动失败重试的逻辑了。
|
|
Register
Register 通过和 /var/lib/kubelet/device-plugins/kubelet.sock 这个 Unix Socket 向 Kubelet 注册,传递了 DevicePlugin 的 Unix Socket 的 Endpoint、资源的名称、API的版本号等信息。
|
|
CheckHealth
这里调用了 nvml.NewEventSet 来监听 GPU 是否发生变化的事件,并且将 unhealthy Device 传递给 m.health 这个 channel。
|
|
Kubelet DeviceManager
DeviceManager 启动
|
|
Device Manager 在 kubelet 启动时的 NewContainerManager 中创建,属于 containerManager 的子模块。
|
|
具体创建 DeviceManager 的代码如下:
|
|
其中除了构建 DeviceManager 相关的结构之外,另外做的一个事情就是注册了一个 callback,用来处理对应 devices 的 add,delete,update 事件。
|
|
接下来到了 DeviceManager 启动的方法,它读取了 checkpoint file 中的数据,恢复 ManagerImpl中的相关数据,包括:
- podDevices
- allocatedDevices
- healthyDevices
- unhealthyDevices
- endpoints
然后将 /var/lib/kubelet/device-plugins/ 下面的除了 checkpiont文件 的所有文件清空,也就是清空所有的socket文件,包括自己的 kubelet.sock,以及其他所有之前的 DevicePlugin 的socket文件。最后创建 kubelet.sock 并启动 gRPC Server对外提供gRPC服务,其中 Register()用于 DevicePlugin 调用进行插件注册。
|
|
DeviceManager 注册
DeviceManager 接收到 DevicePlugin的 RegisterRequest请求,其结构体如下
|
|
检查注册的device Name、version是否符合 Extended Resource 的规则,Name不能属于kubernetes.i o,得有自己的domain,比如 nvidia.com
根据 endpoint 信息创建 EndpointImpl 对象,即根据 endpoint 建立 socket 连接:
|
|
下面是 endPointsImpl 的具体实现:
|
|
执行 EndpointImpl 对象的 run(),在 run方法中:
|
|
- 调用
DevicePlugin的ListAndWatch gRPC接口,通过长连接持续获取ListAndWatch gRPC stream - 从
stream流中获取的devices详情列表然后调用Endpoint的callback,也就是ManagerImpl注册的callback方法genericDeviceUpdateCallback进行Device Manager的缓存更新并写到checkpoint文件中 - run()是通过协程启动的,持续获取device server的ListAndWatch结果,持续更新device状态
- 当获取异常时,deviceManager断开连接,将device设置为不健康的状态。
ListAndWatch
看一下 DevicePlugin 实现的 ListAndWatch,先是立马返回device详情列表,然后开启协程,一旦感知device的健康状态发生变化了,更新 device 详情列表再次返回给 deviceManager。回想起健康检查,DevicePlugin 的 CheckHealth 就就会将设备的健康状态传递给 m.health 这个 channel。
|
|
那么问题来了,DevicePlugin 是如何知道有多少 Device 的呢?我们看看 apiDevices 的实现:
|
|
这里的 cachedDevices 是通过 ResourceManager 获得的 Device 信息,其具体通过 GpuDeviceManager 结构来实现,可以看到它们是调用了 nvml 库而实现的。这里还有一个 MigDeviceManager 本质上相同,不再概述。
|
|
Allocation
kubelet 接收到被调度到本节点的pods后
HandlePodAdditions
当 Node 上的 Kubelet 监听到有新的 Pod 创建时,会调用 HandlerPodAdditions 来处理 Pod 创建的事件。
|
|
接下来进一步看下 HandlerPodAdditions 的实现,对于传入的每一个 Pod ,如果它没有被 terminate,则通过 canAdmitPod 检查是否可以允许该 Pod 创建。
|
|
canAdmitPod 里面,Kubelet 将会依次执行每一个 admit handler 来看 Pod 能否通过。
|
|
admitHandlers 是一个 PodAdmitHandler 的切片,其接口如下:
|
|
Kubelet 在创建的时候会添加一系列的 PodAdmitHandler 用于检查,对pod的资源做一些准入判断,比如:
evictionAdmitHandler:当节点有内存压力时,拒绝创建best effort的pod,还有其它条件先略过TopologyPodAdmitHandler:拒绝创建因为Topology locality冲突而无法分配资源的pod
|
|
与我们 DevicePlugin 相关的则是 containerManager 的 resourceAllocator,这里会分别调用 DeviceManager 和 CpuManager 的 Allocate 函数,看是否能够申请到相关的资源。这里会对 Pod 的每一个 InitContainer 和 Container检查,看能否申请到。
|
|
接下来我们看 ManagerImpl 的 Allocate 函数实现。
ManagerImpl.Allocate
- allocateContainerResources为Pod中的init container分配devices,并更新deviceManager中PodDevices缓存;
allocateContainerResources为Pod中的regular container分配devices,并更新deviceManager中PodDevices缓存- 每次在为Pod分配devices之前,都去检查一下此时的active pods,并与podDevices缓存中的pods进行比对,将已经terminated的Pods的devices从podDevices中删除,即进行了devices的GC操作。
- 从
healthyDevices中随机分配对应数量的devices给该Pod,并注意更新allocatedDevices,否则会导致一个device被分配给多个Pod。 - 拿到devices后,就通过Grpc调用
DevicePlugin的Allocate方法,DevicePlugin返回ContainerAllocateResponse(包括注入的环境变量、挂载信息、Annotations),deviceManager - 根据
pod uuid和container name将返回的信息存入podDevices缓存,更新podDevices缓存信息,并将deviceManager中缓存数据更新到checkpoint文件中。
|
|
接下来我们看 allocateContainerResource 的实现,因为扩展资源是 DevicePlugin 所发现的,而扩展资源不允许过量提交,因此要求容器中的 Request 与 Limits 相等,并且 DevicePlugin 会遍历所有的 Limits 保证资源是充足的。
|
|
我们看到,这里通过 resp, err := eI.e.allocate(devs) 执行 RPC 调用,进入到了 DevicePlugin 的逻辑。这里有一个问题,RPC 远程调用中的 deviceIDs 参数是怎么来的呢?我们看到这里有一个 devicesToAllocate的调用。这里的主要逻辑如下:
- 拿到对应Pod的对应容器已经申请的资源的设备列表,检查是否只申请了部分,如果只有一部分,那么报错
- 然后从
resuableDevices结构中拿到可以使用的设备列表,如果可用的足够则返回,否则继续从healthyDevices中找 - 从
healthyDevices去掉已经在使用的设备,然后检查是否足够,如果不够则报错 - 如果足够的话,根据是否有满足拓扑亲和性去拿到足够的设备列表
|
|
RPC 调用成功后,会将对应的 Response 记录到 m.podDevices 中。
|
|
DevicePlugin.Allocate
Allocate 接口给容器加上 NVIDIA_VISIBLE_DEVICES 环境变量,设置了相关的 DeviceSpec参数,将 Response 返回给 Kubelet。
|
|
前面我们提到, Nvidia的 gpu-container-runtime 根据容器的 NVIDIA_VISIBLE_DEVICES 环境变量,会决定这个容器是否为GPU容器,并且可以使用哪些GPU设备。 而Nvidia GPU device plugin做的事情,就是根据kubelet 请求中的GPU DeviceId, 转换为 NVIDIA_VISIBLE_DEVICES 环境变量返回给kubelet, kubelet收到返回内容后,会自动将返回的环境变量注入到容器中。当容器中包含环境变量,启动时 gpu-container-runtime 会根据 NVIDIA_VISIBLE_DEVICES 里声明的设备信息,将设备映射到容器中,并将对应的Nvidia Driver Lib 也映射到容器中。
Device 的使用
在kubelet的 GetResource 中,会调用 DeviceManager 的 GetDeviceRunContainerOptions,并将这些 options添加到 kubecontainer.RunContainerOptions 中。RunContainerOptions 包括 Envs、Mounts、Devices、PortMappings、Annotations等信息。kubelet调用 GetResources() 为启动 container获取启动参数 runtimeapi.ContainerConfig{Args...}
|
|
GetDeviceRunContainerOptions() 根据 pod uuid 和 container name 从 podDevices 缓存(device的分配过程中会设置缓存数据)中取出Envs、Mounts、Devices、PortMappings、Annotations等信息,另外对于一些PreStartRequired为true的 DevicePlugin,deviceManager需要在启动container之前调用 DevicePlugin的 PreStartContainer grpc接口,做一些device的初始化工作,超时时间限制为30秒。
|
|
Device 的状态管理
device的状态管理涉及到以下3个部分:
- node上的device状态管理当kubelet更新node status时会调用GetCapacity更新device plugins对应的Resource信息。
kubelet_node_status.go调用deviceManager的GetCapacity()获取device的状态,将device状态添加到node info并通过kube-apiserver存入etcd,GetCapacity()返回device server含有的所有device、已经分配给pod使用的device、pod不能使用的device即no-active的device kubelet_node_status.go根据返回的数据更新node info
- kubelet deviceManager服务的device状态管理其实在device的注册、device分配中都有讲解,即使用checkpoint机制默认是将podDevices以 PodDevicesEntry的格式存入*/var/lib/kubelet/device-plugins/kubelet_internal_checkpoint 文件*
|
|
只要device的状态发生了变化(如注册新device、device被分配、device的健康状态发生变化、device被删除),就要将podDevices存入kubelet_internal_checkpoint 文件。kubelet在启动或重启时,都需要读取kubelet_internal_checkpoint 文件里的数据,并以podDevices格式存入podDevices缓存。
DevicePlugin上报device状态在device的注册部分已经讲解过,归纳为deviceManager注册完DevicePlugin后,会跟DevicePlugin建立长连接,持续获取DevicePlugin的ListAndWatch结果,持续更新device状态;- 当获取异常时,
deviceManager断开连接,将device设置为不健康的状态; DevicePlugin默认会重启重新注册,重新上报device的状态
参考资料
-
No backlinks found.