Job & CronJob
之前介绍了 Kubernetes 中用于长期提供服务的 ReplicaSet、Deployment、StatefulSet 和 DaemonSet 等资源,但是作为一个容器编排引擎,任务和定时任务的支持是一个必须要支持的功能。
Kubernetes 中使用 Job 和 CronJob 两个资源分别提供了一次性任务和定时任务的特性,这两种对象也使用控制器模型来实现资源的管理,我们在这篇文章种就会介绍它们的实现原理。
概述
Kubernetes 中的 Job 可以创建并且保证一定数量 Pod 的成功停止,当 Job 持有的一个 Pod 对象成功完成任务之后,Job 就会记录这一次 Pod 的成功运行;当一定数量的Pod 的任务执行结束之后,当前的 Job 就会将它自己的状态标记成结束。
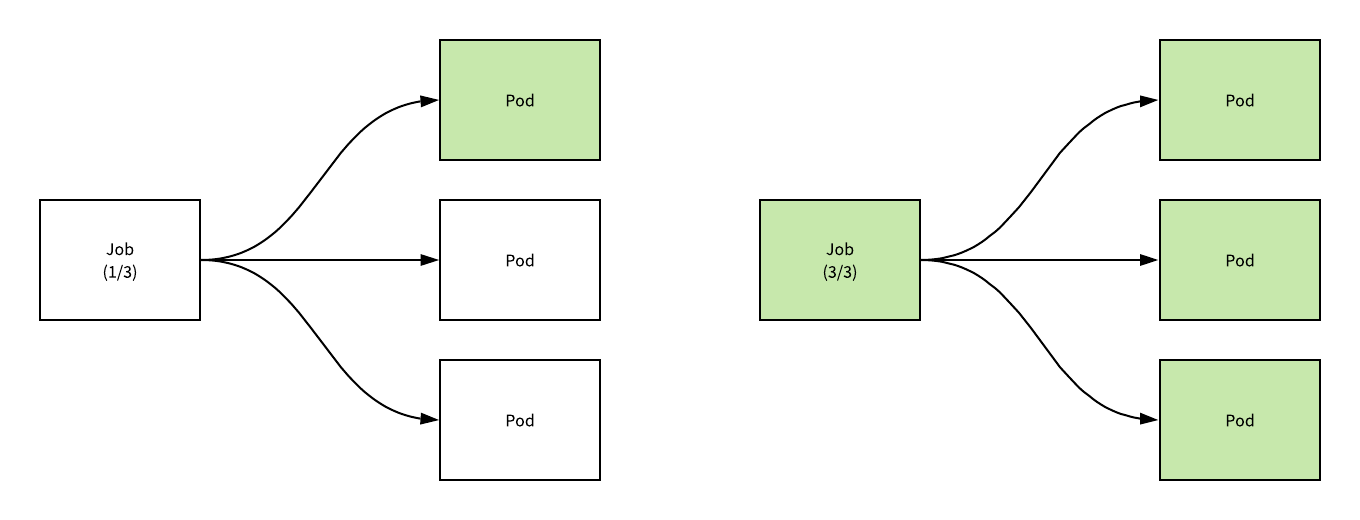
上述图片中展示了一个 spec.completions=3 的任务的状态随着 Pod 的成功执行而更新和迁移状态的过程,从图中我们能比较清楚的看到 Job 和 Pod 之间的关系,假设我们有一个用于计算圆周率的如下任务:
|
|
当我们在 Kubernetes 中创建上述任务时,使用 kubectl 能够观测到以下的信息:
|
|
由于任务 pi 在配置时指定了 spec.completions=10,所以当前的任务需要等待 10 个 Pod 的成功执行,另一个比较重要的 spec.parallelism=5 表示最多有多少个并发执行的任务,如果 spec.parallelism=1 那么所有的任务都会依次顺序执行,只有前一个任务执行成功时,后一个任务才会开始工作。

每一个 Job 对象都会持有一个或者多个 Pod,而每一个 CronJob 就会持有多个 Job 对象,CronJob 能够按照时间对任务进行调度,它与 crontab 非常相似,我们可以使用 Cron 格式快速指定任务的调度时间:
|
|
上述的 CronJob 对象被创建之后,每分钟都会创建一个新的 Job 对象,所有的 CronJob 创建的任务都会带有调度时的时间戳,例如:pi-1551660600 和 pi-1551660660 两个任务:
|
|
CronJob 中保存的任务其实是有上限的,spec.successfulJobsHistoryLimit 和 spec.failedJobsHistoryLimit 分别记录了能够保存的成功或者失败的任务上限,超过这个上限的任务都会被删除,默认情况下这两个属性分别为 spec.successfulJobsHistoryLimit=3 和 spec.failedJobsHistoryLimit=1。
任务
Job 遵循 Kubernetes 的控制器模式进行设计,在发生需要监听的事件时,Informer 就会调用控制器中的回调将需要处理的资源 Job 加入队列,而控制器持有的工作协程就会处理这些任务。
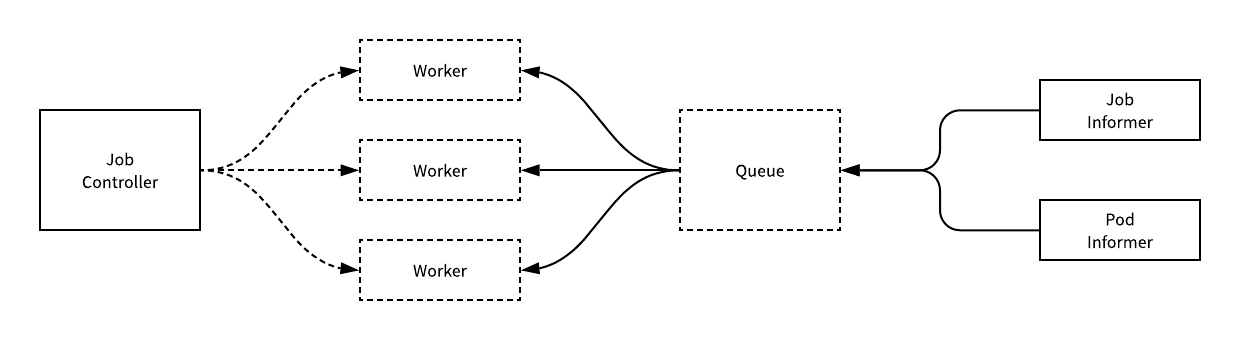
用于处理 Job 资源的 JobController 控制器会监听 Pod 和 Job 这两个资源的变更事件,而资源的同步还是需要运行 syncJob 方法。
同步
syncJob 是 JobController 中主要用于同步 Job 资源的方法,这个方法的主要作用就是对资源进行同步,它的大体架构就是先获取一些当前同步的基本信息,然后调用 manageJob 方法管理 Job 对应的 Pod 对象,最后计算出处于 active、failed 和 succeed 三种状态的 Pod 数量并更新 Job 的状态:
|
|
这一部分代码会从 apiserver 中该名字对应的 Job 对象,然后获取 Job 对应的 Pod 数组并根据计算不同状态 Pod 的数量,为之后状态的更新和比对做准备。
|
|
准备工作完成之后,会调用 manageJob 方法,该方法主要负责管理 Job 持有的一系列 Pod 的运行,它最终会返回目前集群中当前 Job 对应的活跃任务的数量。
|
|
最后的这段代码会将 Job 规格中设置的 spec.completions 和已经完成的任务数量进行比对,确认当前的 Job 是否已经结束运行,如果任务已经结束运行就会更新当前 Job 的完成时间,同时当 JobController 发现有一些状态没有正确同步时,也会调用 updateHandler 更新资源的状态。
并行执行
Pod 的创建和删除都是由 manageJob 这个方法负责的,这个方法根据 Job 的 spec.parallelism 配置对目前集群中的节点进行创建和删除。

如果当前正在执行的活跃节点数量超过了 spec.parallelism,那么就会按照创建的升删除多余的任务,删除任务时会使用 DeletePod 方法:
|
|
当正在活跃的节点数量小于 spec.parallelism 时,我们就会根据当前未完成的任务数和并行度计算出最大可以处于活跃的 Pod 个数 wantActive 以及与当前的活跃 Pod 数相差的 diff:
|
|
在方法的最后就会以批量的方式并行创建 Pod,所有 Pod 的创建都是通过 CreatePodsWithControllerRef 方法在 Goroutine 中执行的。
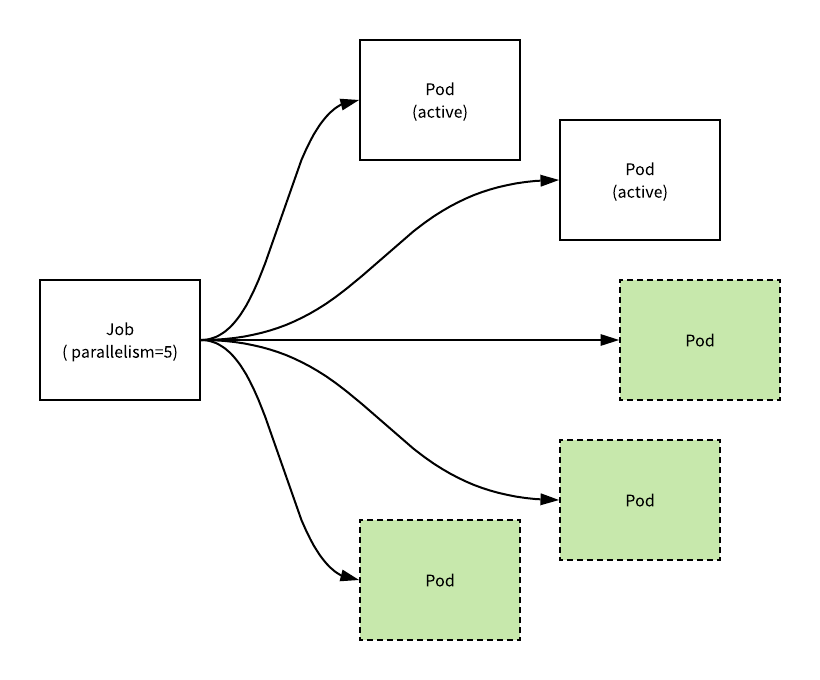
这里会使用 WaitGroup 等待每个 Batch 中创建的结果返回才会执行下一个 Batch,Batch 的大小是从 1 开始指数增加的,以冷启动的方式避免首次创建的任务过多造成失败:
|
|
通过对 manageJob 的分析,我们其实能够看出这个方法就是根据规格中的配置对 Pod 进行管理,它在较多并行时删除 Pod,较少并行时创建 Pod,也算是一个简单的资源利用和调度机制,代码非常直白并且容易理解,不需要花太大的篇幅。
定时任务
用于管理 CronJob 资源的 CronJobController 虽然也使用了控制器模式,但是它的实现与其他的控制器不太一样,他没有从 Informer 中接受其他消息变动的通知,而是直接访问 apiserver 中的数据:
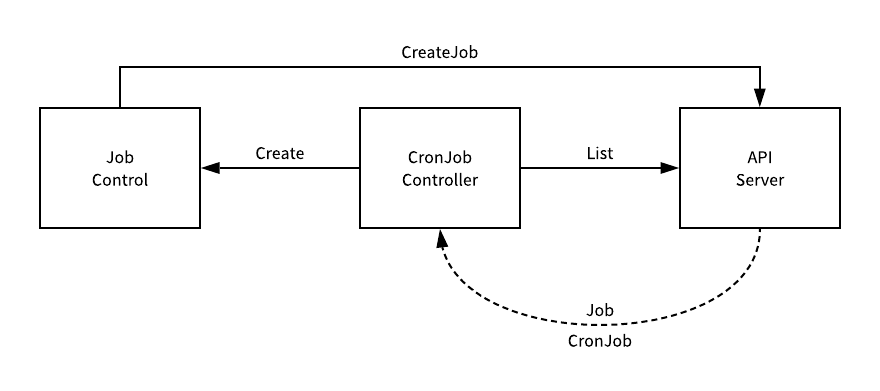
从 apiserver 中获取了 Job 和 CronJob 的信息之后就会调用 JobControl 向 apiserver 发起请求创建新的 Job 资源,这一个过程都是由 CronJobController 的 syncAll 方法驱动的,我们接下来就来介绍这一方法的实现。
同步
syncAll 方法会从 apiserver 中取出所有的 Job 和 CronJob 对象,然后通过 groupJobsByParent 将任务按照 spec.ownerReferences 进行分类并遍历去同步所有的 CronJob:
|
|
syncOne 就是用于同步单个 CronJob 对象的方法,这个方法会首先遍历全部的 Job 对象,只保留正在运行的活跃对象并更新 CronJob 的状态:
|
|
随后的 getRecentUnmetScheduleTimes 方法会根据 CronJob 的调度配置 spec.schedule 和上一次执行任务的时间计算出我们缺失的任务次数。
|
|
如果现在需要调度新的任务,但是当前已经存在活跃的任务,就会根据并发策略的配置执行不同的操作:
- 使用
ForbidConcurrent策略跳过这一次任务的调度直接返回; - 使用
ReplaceConcurrent策略获取并删除全部活跃的任务,通过创建新的 Pod 替换这些正在执行的活跃 Pod;
|
|
在方法的最后,它会从 CronJob 的 spec.jobTemplate 中拿到创建 Job 使用的模板并调用 JobControl 的 CreateJob 向 apiserver 发起创建任务的 HTTP 请求,接下来的操作就都是由 JobController 负责了。
总结
Job 作为 Kubernetes 中用于处理任务的资源,与其他的资源没有太多的区别,它也使用 Kubernetes 中常见的控制器模式,监听 Informer 中的事件并运行 syncHandler 同步任务
而 CronJob 由于其功能的特殊性,每隔 10s 会从 apiserver 中取出资源并进行检查是否应该触发调度创建新的资源,需要注意的是 CronJob 并不能保证在准确的目标时间执行,执行会有一定程度的滞后。
两个控制器的实现都比较清晰,只是边界条件比较多,分析其实现原理时一定要多注意。
-
No backlinks found.