Huggingface Transformers
在 transformers 中,每个模型都需要三个核心 class:
- Configuration class
- Model class
- Preprocessing class
Config
PretrainedConfig
Base class for all configuration classes
|
|
LlamaConfig
|
|
|
|
ModelOutput
ModelOutput 是所有模型输出的基类。下面是其源码核心部分,可以看到 ModelOutput 其实就是一个有序的字典(OrderedDict)。
|
|
基于 ModelOutput,hf 预先定义了 40 多种不同的 sub-class,这些类是 Hugging Face Transformers 库中用于表示不同类型模型输出的基础类,每个类都提供了特定类型模型输出的结构和信息,以便于在实际任务中对模型输出进行处理和使用。每个 sub-class 都需要用装饰器 @dataclass。
CausalLMOutput
CausalLMOutput 是一个基础的输出类,通常在训练阶段或不需要缓存(cache)进行快速解码的推理场景中使用。它包含了模型前向传播后的核心结果:
loss: 当你传入labels(即正确答案)时,模型会计算并返回语言建模的损失值。这是模型训练所必需的。logits: 模型对词汇表中每个词的原始预测分数。在生成文本时,通常会通过 argmax 或采样(sampling)等策略从logits中选择下一个词元。hidden_states: (可选) 模型所有层的隐藏状态。这对于模型分析和特征提取很有用。attentions: (可选) 模型所有注意力层的注意力权重。这可以用于理解模型在不同词元上的关注程度。
|
|
CausalLMOutputWithPast
CausalLMOutputWithPast 继承了 CausalLMOutput 的所有属性,并额外增加了一个关键属性:
past_key_values: 这是它与CausalLMOutput最核心的区别。该属性用于存储注意力机制中的键(Key)和值(Value)的状态。在自回归生成(如生成一篇文章)的推理过程中,模型每生成一个新词元,就可以利用之前所有词元的past_key_values,而无需重新计算它们,从而极大地提升生成速度。这个机制通常被称为 “KV 缓存”。
|
|
这里的参数:
- loss 为
torch.FloatTensorof shape(1,) - logits 为
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)
为了保持代码规范,我们需要在模型的 forward 函数中对输出结果进行封装,示例如下:
|
|
MoEModelOutput
这是 MoE 模型 基础输出 的基类。它代表了 MoE Transformer 模型(不带任何特定任务头)的裸输出。
last_hidden_state:torch.FloatTensor,维度是(batch_size, sequence_length, hidden_size)。- 这是模型最后一层输出的隐藏状态序列。这是 Transformer 模型最核心的输出。
hidden_states: (可选)tuple(torch.FloatTensor)。- 包含了模型所有层的隐藏状态,以及初始的词嵌入向量。如果你在模型配置中启用了
output_hidden_states=True,这个字段才会被返回。 - 每一层的输出 shape 为
(batch_size, sequence_length, hidden_size)
- 包含了模型所有层的隐藏状态,以及初始的词嵌入向量。如果你在模型配置中启用了
attentions: (可选)tuple(torch.FloatTensor)。- 包含了模型所有注意力层的注意力权重。如果你在模型配置中启用了
output_attentions=True,这个字段才会被返回。 - 每一层的 shape 为
(batch_size, num_heads, sequence_length, sequence_length)
- 包含了模型所有注意力层的注意力权重。如果你在模型配置中启用了
router_probs/router_logits: (可选)tuple(torch.FloatTensor)。- 这是 MoE 模型特有的输出。它包含了每一层 MoE 模块中“路由器”(Router)的输出。路由器决定了每个词元(token)应该被发送到哪个专家(expert)去处理。
- 这些值对于计算 MoE 模型的“辅助损失”(Auxiliary Loss)至关重要。这个损失函数用来确保所有专家被均匀地使用,避免某些专家过载而另一些专家空闲。
- (注意:文档中
router_probs和router_logits的描述稍有混淆,但你可以理解为它们都是指路由器的原始输出,用于计算辅助损失。)
|
|
MoeModelOutputWithPast
这个类继承自 MoEModelOutput 的概念,并额外增加了一个用于 自回归生成(autoregressive generation) 的关键部分。
它包含了 MoEModelOutput 的所有字段,并增加了:
past_key_values: (可选)Cache对象。- 这就是我们常说的 KV 缓存。在生成文本时,为了提高效率,模型会缓存已经计算过的 Key 和 Value 向量。这样,在生成下一个词元时,就不需要重新计算前面所有词元的 Key-Value,从而大大加快了生成速度。
- 只有在调用模型时设置了
use_cache=True,这个字段才会被返回。
|
|
MoECausalLMOutputWithPast
MoECausalLMOutputWithPast 是最具体的一个类,专门用于 带有因果语言模型头(Causal Language Modeling Head)的 MoE 模型。当你使用像 Mixtral 这样的模型进行文本生成或微调时,你通常会直接接触到这个输出对象。
它包含了 MoeModelOutputWithPast 的所有字段,并增加了针对特定任务的输出:
loss: (可选)torch.FloatTensor,维度是(1,)。- 语言模型损失。只有当你向模型提供了
labels(即正确答案)时,这个字段才会被计算并返回。它通常是交叉熵损失(Cross-Entropy Loss),用于衡量模型预测的下一个词元与真实词元之间的差距。
- 语言模型损失。只有当你向模型提供了
logits:torch.FloatTensor,维度是(batch_size, sequence_length, config.vocab_size)。- 预测分数。这是语言模型头的原始输出,在经过 Softmax 激活函数之前。它为词汇表中的每个词元都提供了一个分数,分数越高的词元,模型认为它越有可能成为下一个词元。
aux_loss: (可选)torch.FloatTensor。- 辅助损失。这就是前面提到的,根据
router_logits计算出的 MoE 负载均衡损失。在训练过程中,这个损失会与主要的loss相加,共同指导模型的优化。
- 辅助损失。这就是前面提到的,根据
|
|
Seq2SeqModelOutput
|
|
TokenClassifierOutput
|
|
这里简单介绍以下几种,更多的可以查看官方文档和源码:
BaseModelOutput: 该类是许多基本模型输出的基础,包含模型的一般输出,如 logits、hidden_states 等。BaseModelOutputWithNoAttention: 在模型输出中不包含注意力(attention)信息。BaseModelOutputWithPast: 包含过去隐藏状态的模型输出,适用于能够迭代生成文本的模型,例如语言模型。BaseModelOutputWithCrossAttentions: 在模型输出中包含交叉注意力(cross attentions)信息,通常用于特定任务中需要跨注意力的情况,比如机器翻译。BaseModelOutputWithPastAndCrossAttentions: 同时包含过去隐藏状态和交叉注意力的模型输出。MoEModelOutput: 包含混合专家模型(Mixture of Experts)输出的模型。MoECausalLMOutputWithPast: 混合专家语言模型的输出,包括过去隐藏状态。Seq2SeqModelOutput: 序列到序列模型输出的基类,适用于需要生成序列的模型。
Model
PreTrainedModel
PreTrainedModel 是 Hugging Face Transformers 库中定义预训练模型的基类。它继承了 nn.Module,同时混合了几个不同的 mixin 类,如 ModuleUtilsMixin、GenerationMixin、PushToHubMixin 和 PeftAdapterMixin。这个基类提供了创建和定义预训练模型所需的核心功能和属性。
以下是 PreTrainedModel 中的部分代码:
|
|
在这个基类中,我们可以看到一些重要的属性和方法:
config_class:指向特定预训练模型类的配置文件,用于定义模型的配置。base_model_prefix:基本模型前缀,在模型的命名中使用,例如在加载预训练模型的权重时使用。main_input_name:指定模型的主要输入名称,通常是 input_ids。_init_weights方法:用于初始化模型权重的方法。
在这个基类中,大多数属性都被定义为 None 或空字符串,这些属性在具体的预训练模型类中会被重写或填充。接下来我们将看到如何使用 PretrainedModel 类定义 llama 模型。
LlamaPreTrainedModel
|
|
在这个例子中,首先定义了 LlamaPreTrainedModel 类作为 llama 模型的基类,它继承自 PreTrainedModel。在这个基类中,我们指定了一些 llama 模型特有的属性,比如配置类 LlamaConfig、模型前缀 model、支持梯度检查点(gradient checkpointing)、跳过的模块列表 _no_split_modules 等等。
然后,我们基于这个基类分别定义了 LlamaModel、LlamaForCausalLM 和 LlamaForSequenceClassification。这些模型的逻辑关系如下图所示:
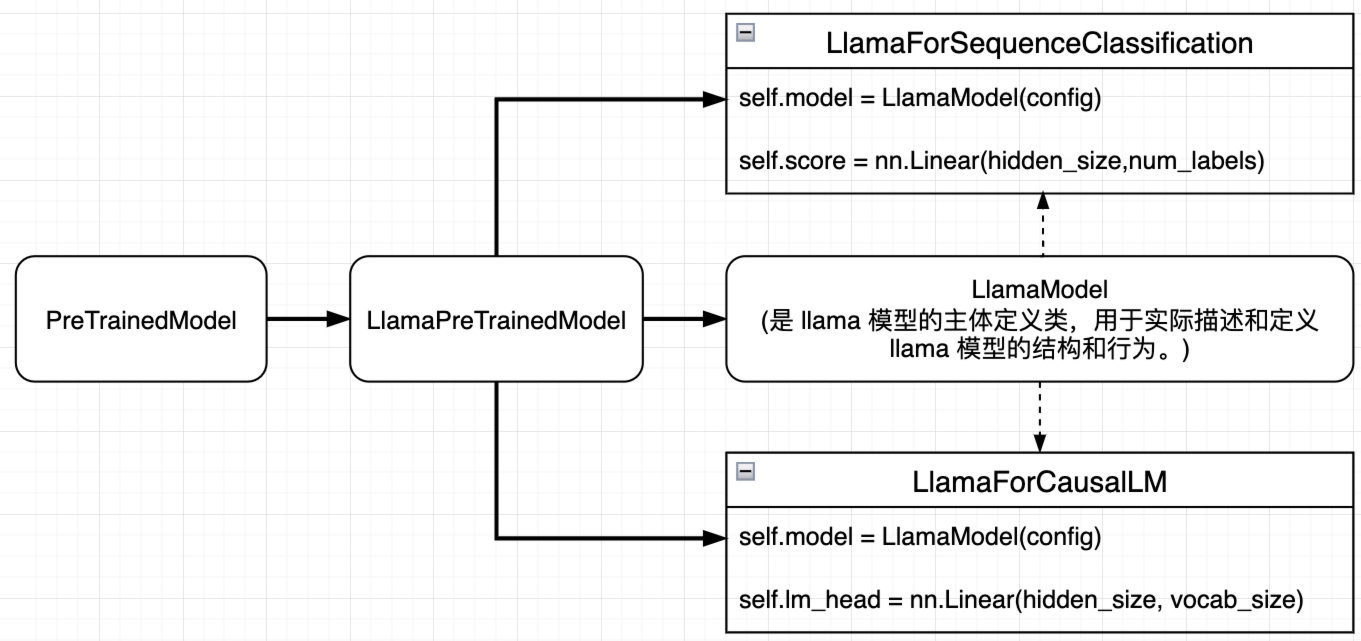
LlamaModel
LlamaModel 是 llama 模型的主体定义类,也就是我们最常见的 pytorch 定义模型的方法、默认的输出格式为 BaseModelOutputWithPast。这里的 LlamaModel 是不带 LMHead 的,输出最后一层的 hidden states。
|
|
LlamaForCausalLM
LlamaForCausalLM 适用于生成式语言模型的 llama 模型,可以看到 backbone 就是 LlamaModel,增加了 lm_head 作为分类器,输出长度为词汇表的大小,用来预测下一个单词。输出格式为 CausalLMOutputWithPast;
|
|
LlamaForSequenceClassification
LlamaForSequenceClassification 适用于序列分类任务的 llama 模型,同样把 LlamaModel 作为 backbone,不过增加了 score 作为分类器,输出长度为 label 的数量,用来预测类别。输出格式为 SequenceClassifierOutputWithPast
|
|
对应的 GenericForSequenceClassification 实现如下:
|
|
LlamaForTokenClassification
|
|
对应的 GenericForTokenClassification 实现如下
|
|
每个子类根据特定的任务或应用场景进行了定制,以满足不同任务的需求。另外可以看到 hf 定义的模型都是由传入的 config 参数定义的,所以不同模型对应不同的配置,这也是为什么我们经常能看到有像 BertConfig,GPTConfig 这些预先定义好的类。例如我们可以很方便地通过指定的字符串或者文件获取和修改不同的参数配置:
|
|
Tokenizer
|
|
Tokenize 编码
tokenize 方法可以将一个自然语言字符串,转换成对应的 tokens
|
|
encode/decode
可以通过 encode() 函数将这两个步骤合并, decode() 函数则对应相反操作。
|
|
Tokenizer 直接处理
一般情况下,会直接通过 tokenizer 处理输入 sequences,如下所示,返回的 output 包括了 input_ids 和 attention_mask 等
|
|
tokenizer 有很多可以控制的参数:
- return_tensors=“pt”,指定返回张量类型,可选"pt"(PyTorch)、“tf”(TensorFlow)、“np”(NumPy),避免手动转换格式
- return_attention_mask: 返回注意力掩码(
1表示有效 Token,0表示[PAD]),默认True,模型靠它忽略填充部分