Hudi
Hudi 摄取与管理处于 DFS 之上的大型分析数据集并为查询访问提供三个逻辑视图。
- 读优化视图 - 在纯列式存储上提供出色的查询性能,非常像 parquet 表。
- 增量视图 - 在数据集之上提供一个变更流并提供给下游的作业或ETL任务。
- 准实时的表 - 使用基于列存储和行存储(例如 Parquet + Avro)以提供对实时数据的查询
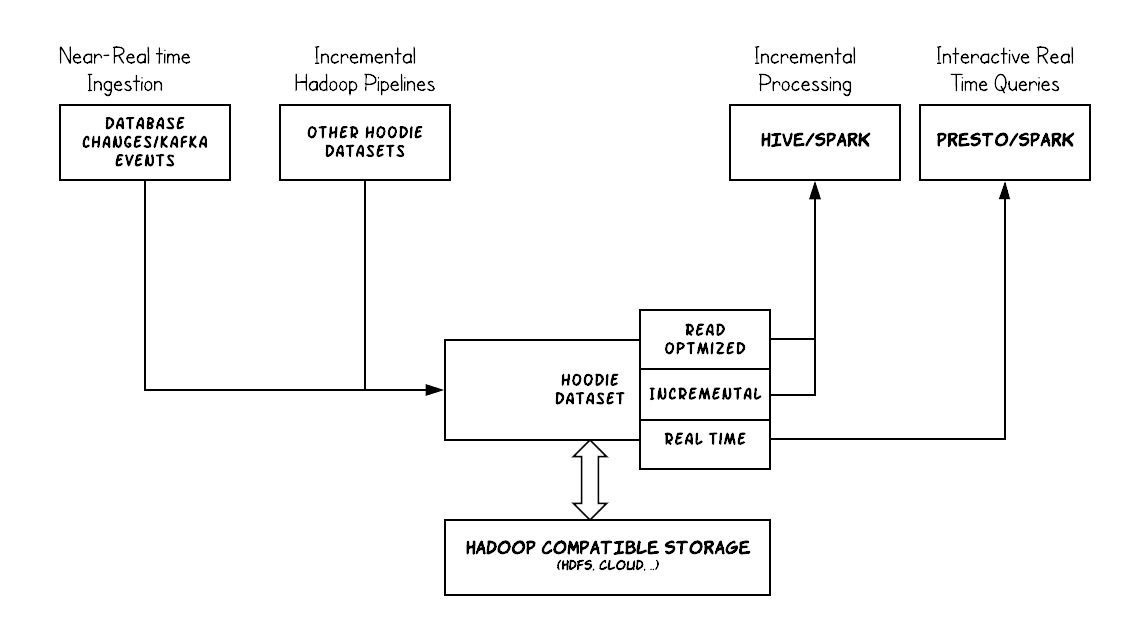
通过仔细地管理数据在存储中的布局和如何将数据暴露给查询,Hudi支持丰富的数据生态系统,在该系统中,外部数据源可被近实时摄取并被用于presto和spark等交互式SQL引擎,同时能够从处理/ETL框架(如hive和 spark中进行增量消费以构建派生(Hudi)数据集。
Hudi 大体上由一个自包含的Spark库组成,它用于构建数据集并与现有的数据访问查询引擎集成。有关演示,请参见快速开始。
Linked Mentions