GPUDirect
GPUDirect Shared Memory
GPUDirect SharedMemory 支持 GPU 与第三方 PCIe 设备通过共享的 host memory 实现共享内存。下图对未使用 GPUDirect 和使用 GPUDirect 后的 GPU 之间通信的数据拷贝进行了对比。
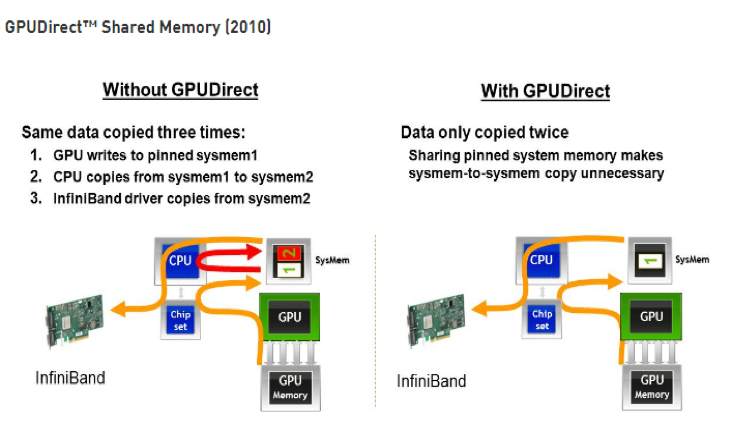
可以看出支持 GPUDirect SharedMemory 后,GPU 之间的通信仅需要两次拷贝:
- 先从 GPU 缓存拷贝到系统内存
- 对端 GPU 缓存从系统内存拷贝数据
相较于未使用 GPUDirect 减少了一次数据拷贝,降低了数据交换的延迟。
GPUDirect P2P
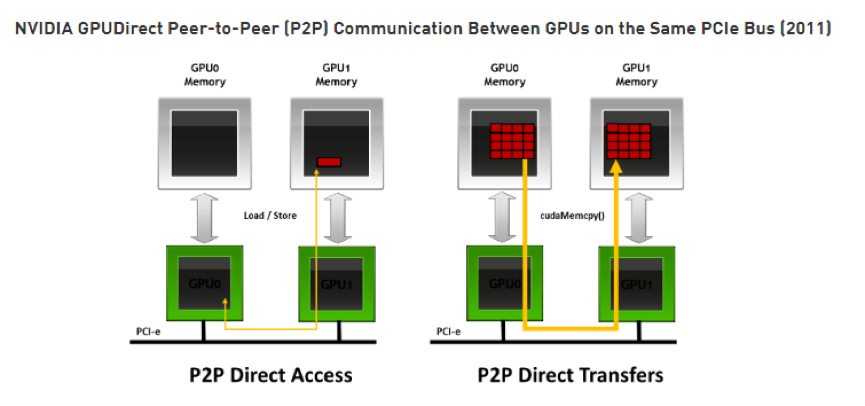
GPUDirect P2P 支持相同 PCIe root complex 下的 GPU 之间的直接互访显存,如上图所示,GPU 之间的通信不需要将数据拷贝到 CPU host memory 作为中转,进一步的降低了数据交换的延迟。
NVLink
GPUDirect P2P 技术中,多个 GPU 通过 PCIe 直接与 CPU 相连,而 PCIe 3.0 x16 的双向带宽不足 32GB/s,当训练数据不断增长时,PCIe 的带宽满足不了需求,会逐渐成为系统瓶颈。为提升多 GPU 之间的通信性能,充分发挥 GPU 的计算性能,NVIDIA 于 2016 年发布了全新架构的 NVLink。
NVLink 1.0 与 P100 GPU 一同发布,一块 P100 上,可集成 4 条 NVLink 连接线,每条 NVLink 具备双路共 40GB/s 的带宽,整个芯片的带宽达到了 160GB/s(4(NVLink 连接线)_40GB/s),相当于 PCIe 3.0_16 的 5 倍。
NVLink 2.0 版本与 Tesla V100 GPU 一同发布,NVLink 2.0 每个方向的信号发送速率从 20GB/s 增加到 25GB/s,每条 NVLink 双信道最大达到 50GB/s。单个 V100 GPU 支持 6 条 NVLink 连接线,总带宽最大可达 300GB/s(6(NVLink 连接线)*2(双向)*25GB/s),是 PCIe 3.0 带宽的将近 10 倍。
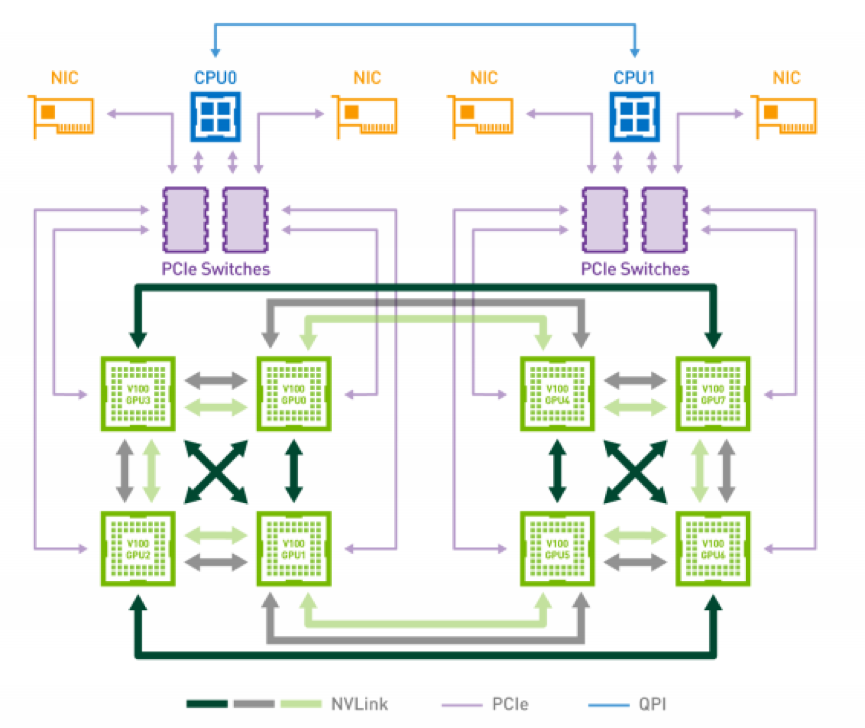
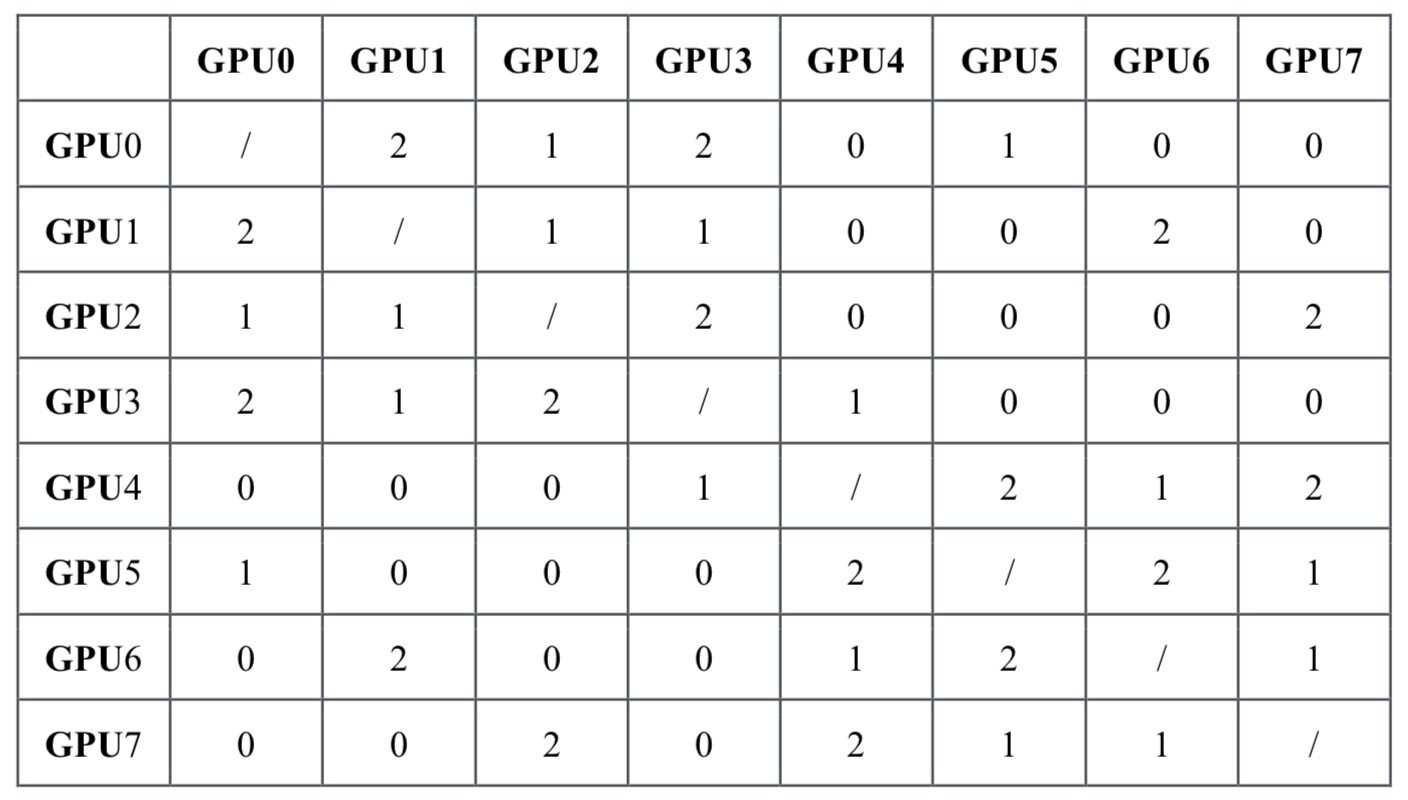
上图是使用 NVLink 连接 8 个 Tesla V100 的混合立体网络拓扑。图中也以看出每个 V100 GPU 有 6 个 NVLink 通道(绿色连接线),8 块 GPU 间无法做到全连接,2 个 GPU 间最多只能有 2 个 NVLink 通道 100GB/s 的双向带宽。有趣的是 GPU 0 和 3,GPU 0 和 4 之间有 2 条 NVLink 相连,GPU0 和 GPU1 之间有一条 NVLink 连接线,GPU 0 和 6 之间没有 NVLink 连接线,也就是说 GPU0 与 GPU6 之间的通信仍然需要通过 PCIe。
NVSwitch
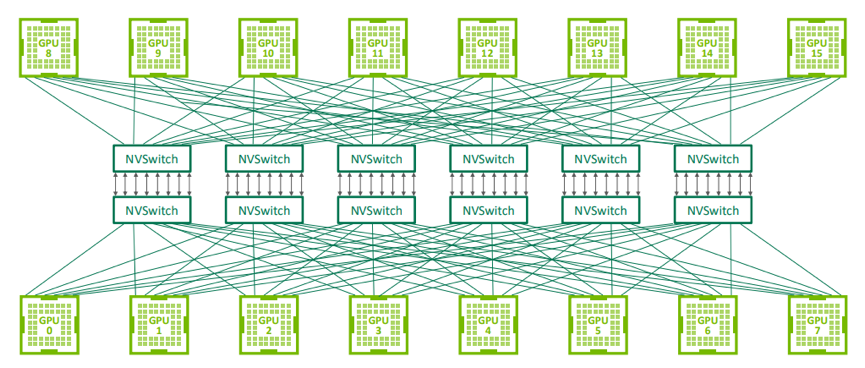
前面也看到,NVLink2.0 技术使得单服务器中 8 个 GPU 无法达到全连接,为解决该问题,NVIDIA 在 2018 年发布了 NVSwitch,实现了 NVLink 的全连接。NVIDIA NVSwitch 是首款节点交换架构,可支持单个服务器节点中 16 个全互联的 GPU,并可使全部 8 个 GPU 对分别达到 300GB/s 的速度同时进行通信。
下图为 16 个 GPU 通过 NVSwitch 全连接拓扑图。
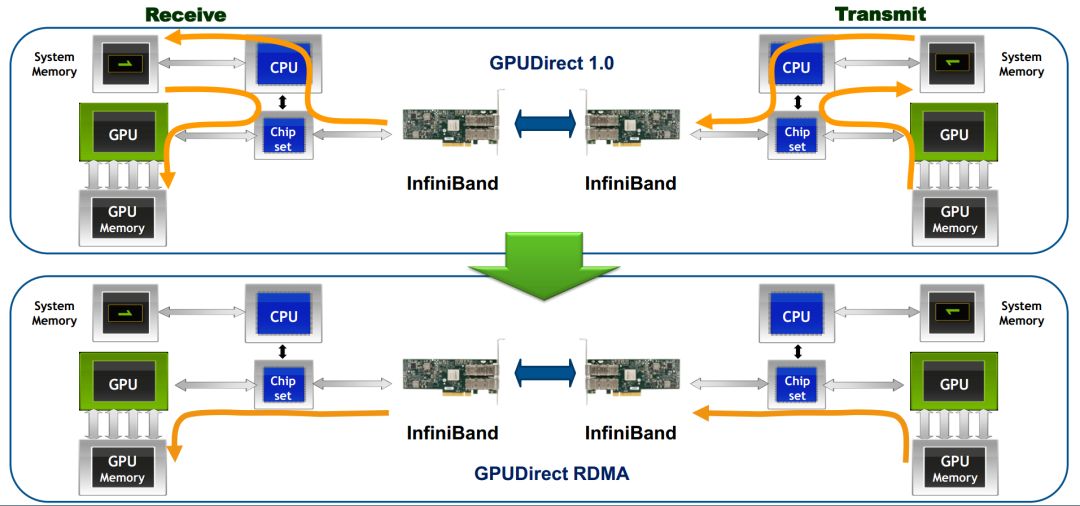
GPUDirect RDMA
GPUDirect RDMA 技术支持 Server1 的 GPU 内存可以通过同一 root complex 下的网卡直接访问对端 Server2 的 GPU 内存,如下图所示。GPU 通信通道中无需 CPU 参与,大幅度降低了 CPU 间通信的延迟。
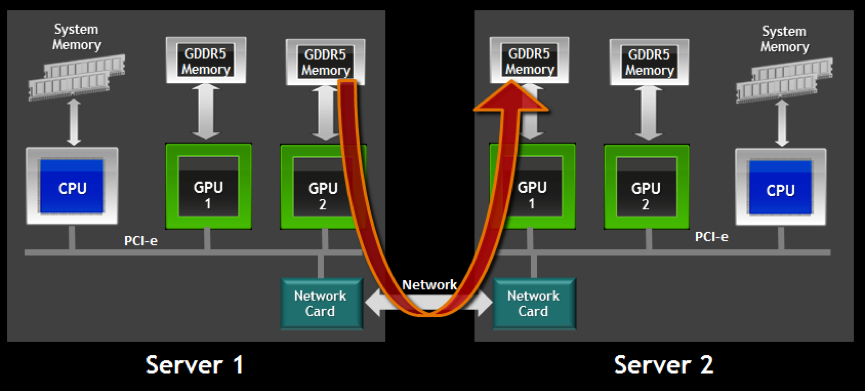
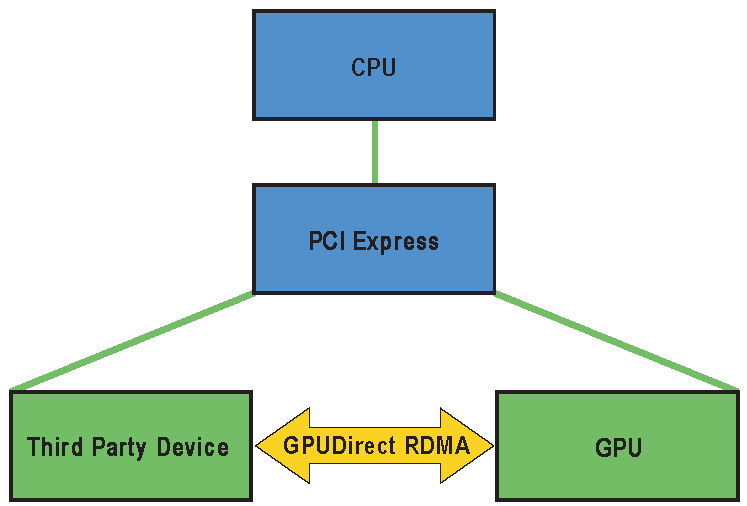
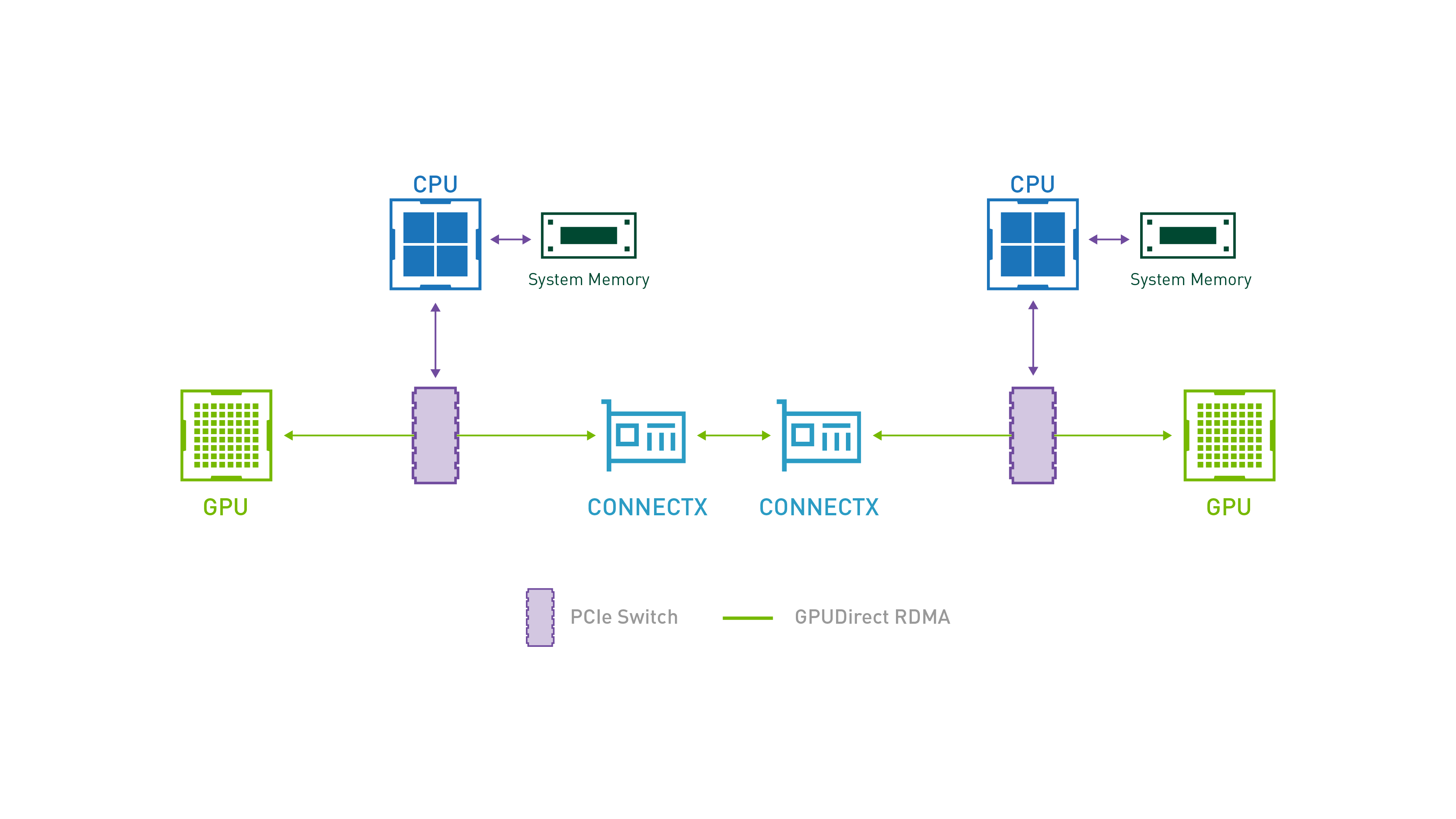
GPUDirect RDMA,就是计算机 1 的 GPU 可以直接访问计算机 2 的 GPU 内存。而在没有这项技术之前,GPU 需要先将数据从 GPU 内存搬移到系统内存,然后再利用 RDMA 传输到计算机 2,计算机 2 的 GPU 还要做一次数据从系统内存到 GPU 内存的搬移动作。GPUDirect RDMA 技术进一步减少了 GPU 通信的数据复制次数,进一步降低了通信延迟。
在 40Gbps 以太网上测试 GPUDirect RDMA 的性能测试结果如下。
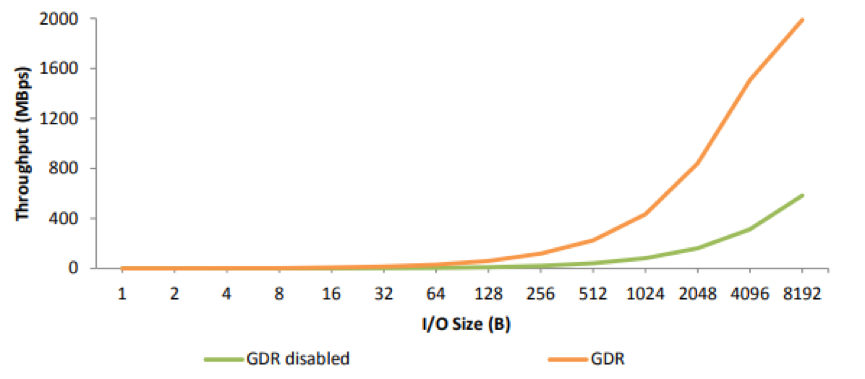
上图比较了不同的 I/O size,使用 GPUDirect RDMA 和不使用的吞吐量数据。结果显示 I/O size 越大,GPUDirect RDMA 的优势越明显,在 I/O size 在 8192 时,GPUDirect RDMA 有 4 倍的性能提升。
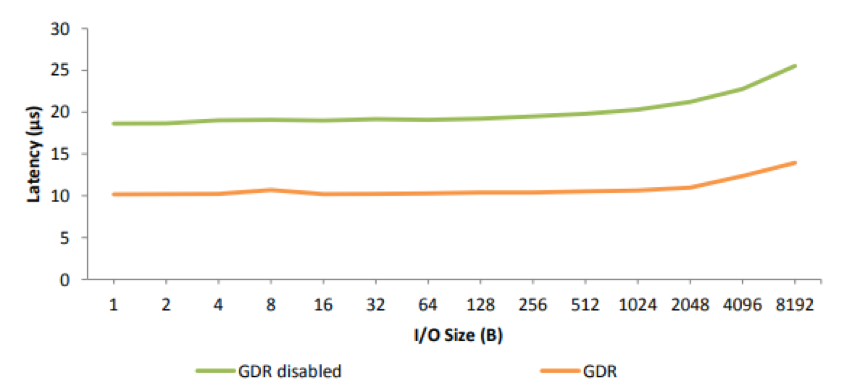
上图为不同的 I/O size 下,使用 GPUDirect RDMA 和不使用时的时延数据。数据显示在使用 GPUDirect RDMA 后,时延显著降低,从接近 20 微妙下降到 10 微妙左右。
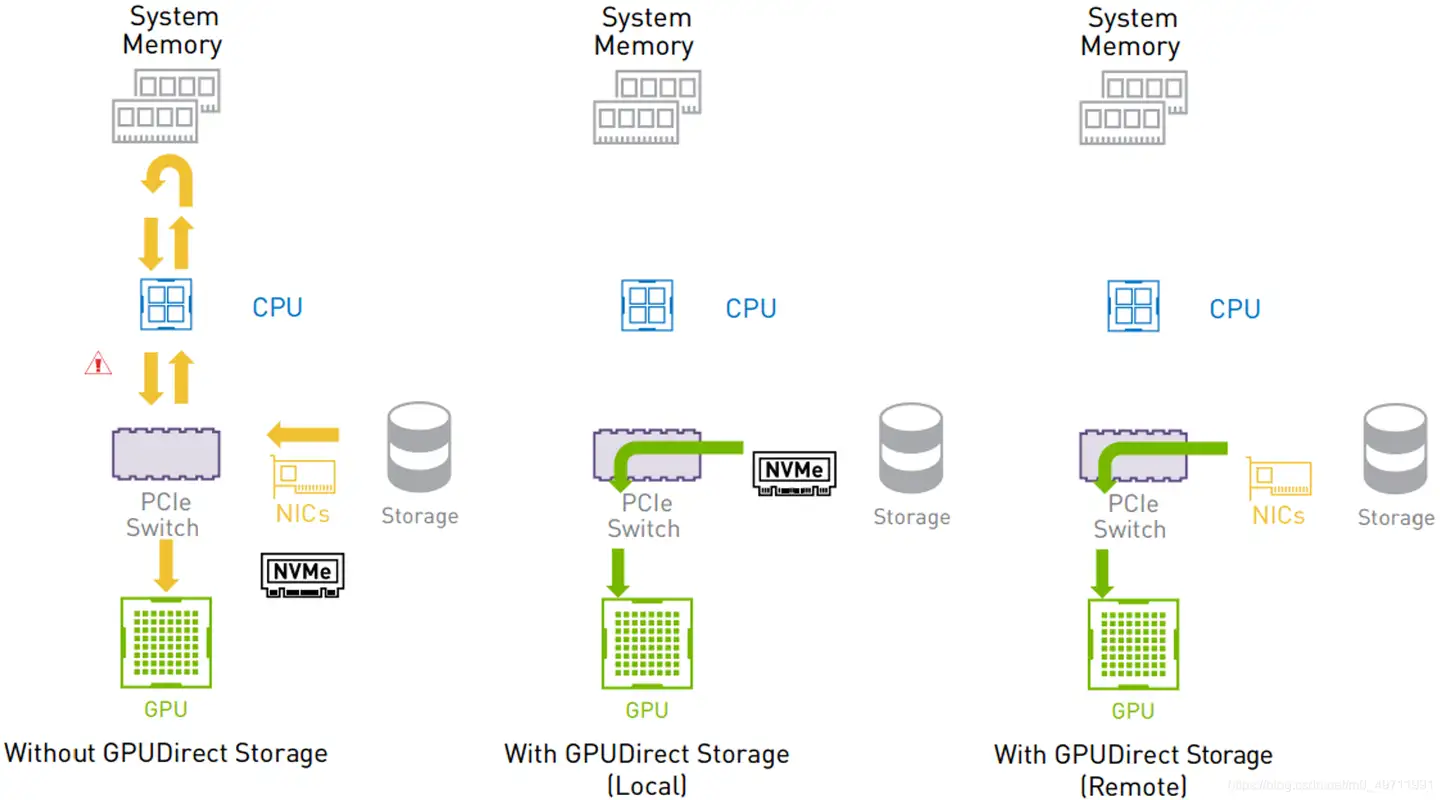
GPUDirect Storage
2019年,GPUDirect Storage,跟上面一系列GPUDirect做法类似,bypass 掉CPU与系统memory,让GPU与存储系统直接通信,节省I/O路径,降低延迟。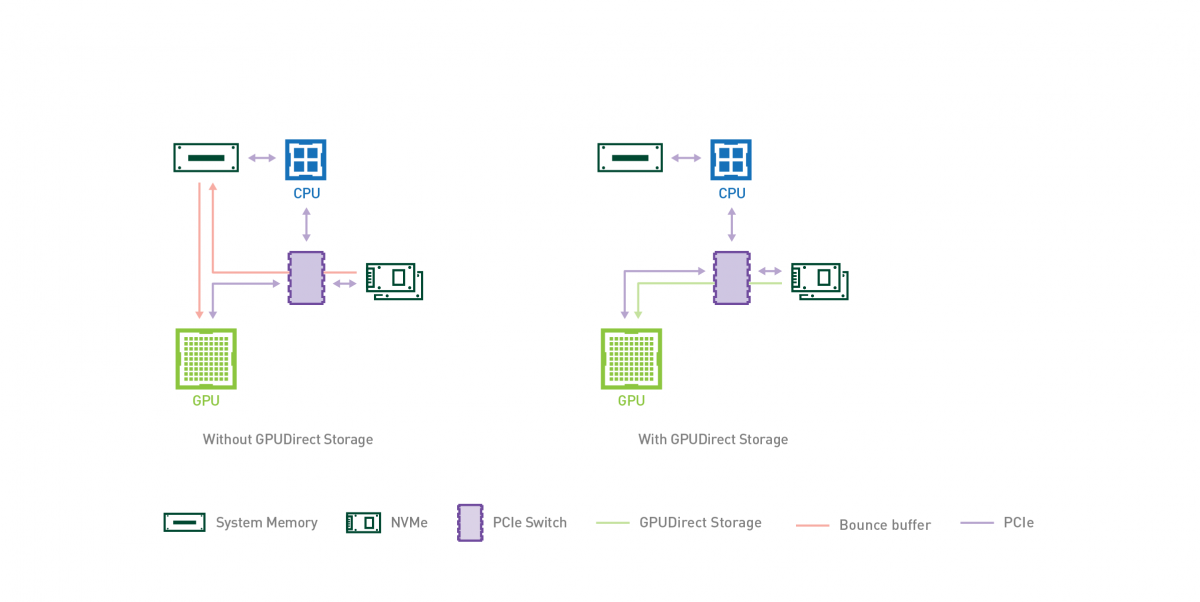
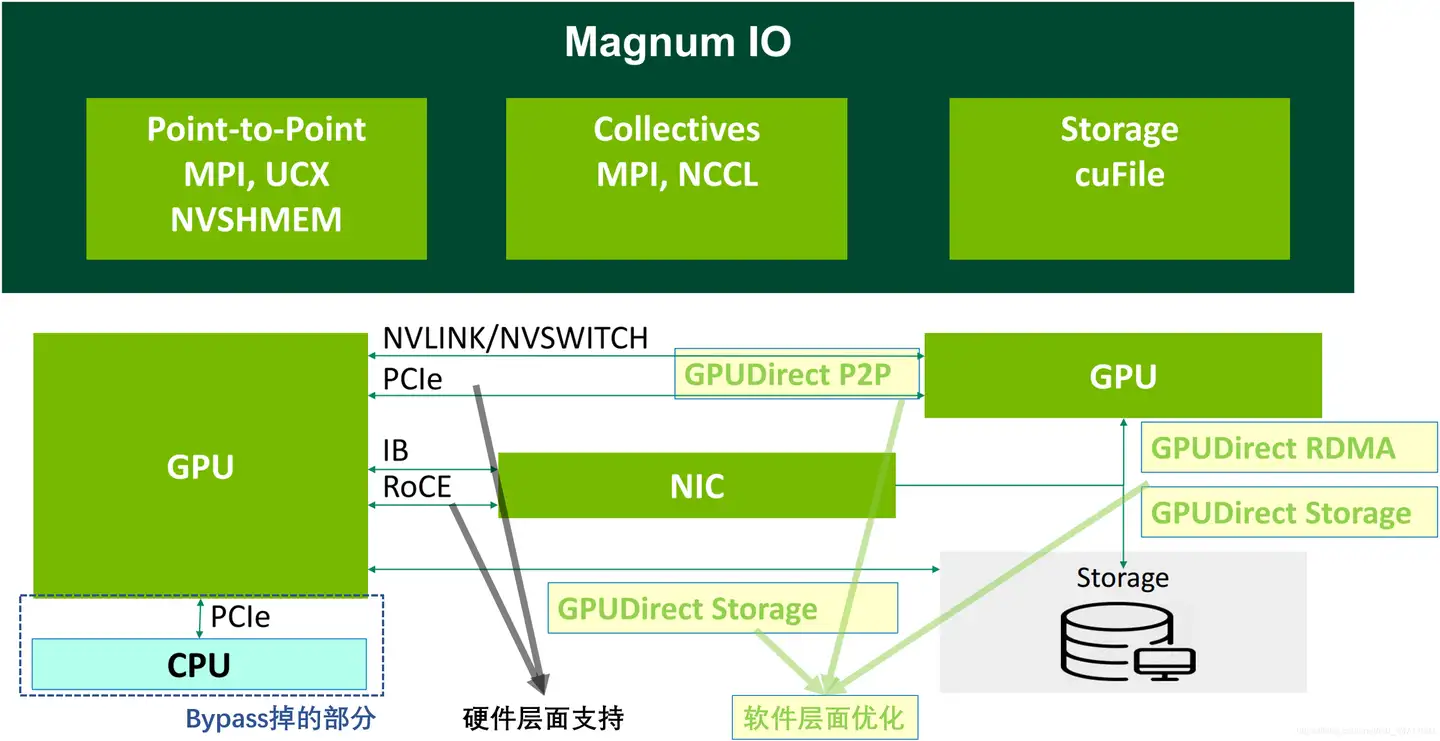
上面我们提到的所有关键技术点可以用下面这个图来做个汇总。
首先,要实现高速通信,需要有硬件层面的支持,包括:单机内部的PCIe、NVlink、NVSwitch;多机之间的RDMA网络(IB或RoCE)。
其次,要有软件堆栈的优化,包括GPUDirect的一系列技术:P2P(Peer-to-Peer)、RDMA、Async、Storage等。
所有这些软件,都集成在NVIDIA Magnum IO中。Magnum IO是专门面向多GPU、多节点网络和存储性能优化的一个软件堆栈,它包括了点对点通信、集合通信、存储通信等经过优化的通信库。Magnum IO基本覆盖了GPU通信的方方面面,可以充分应用各类NVIDIA支持的GPU和网络硬件来实现最优吞吐量和低延迟。
优势体现:
- 优化 IO:绕过 CPU,在 GPU 显存、网络和存储中直接实现 IO。
- 优化系统:减少 CPU 使用率,使 CPU 与 GPU 各司其职,构建更平衡的异构计算加速系统。
- 无缝整合:全面优化包括延迟敏感型、带宽敏感型、混合型通信在内的各种网络通信需求。
Reference
-
No backlinks found.