Go GC
GC 算法
Reference Counting
引用计数的思想:每个单元维护一个域,保存其它单元指向它的引用数量(类似有向图的入度)。当引用数量为 0 时,将其回收。引用计数是渐进式的,能够将内存管理的开销分布到整个程序之中。C++ 的 share_ptr 使用的就是引用计算方法。
引用计数算法实现一般是把所有的单元放在一个单元池里,比如类似 free list。这样所有的单元就被串起来了,就可以进行引用计数了。新分配的单元计数值被设置为 1(注意不是 0,因为申请一般都说 ptr = new object 这种)。每次有一个指针被设为指向该单元时,该单元的计数值加 1;而每次删除某个指向它的指针时,它的计数值减 1。当其引用计数为 0 的时候,该单元会被进行回收。虽然这里说的比较简单,实现的时候还是有很多细节需要考虑,比如删除某个单元的时候,那么它指向的所有单元都需要对引用计数减 1。
优点
- 渐进式。内存管理与用户程序的执行交织在一起,将 GC 的代价分散到整个程序。不像标记-清扫算法需要 STW (Stop The World,GC 的时候挂起用户程序)。
- 算法易于实现。
- 内存单元能够很快被回收。相比于其他垃圾回收算法,堆被耗尽或者达到某个阈值才会进行垃圾回收。
缺点
- 原始的引用计数不能处理循环引用。大概这是被诟病最多的缺点了。不过针对这个问题,也出了很多解决方案,比如强引用等。
- 维护引用计数降低运行效率。内存单元的更新删除等都需要维护相关的内存单元的引用计数,相比于一些追踪式的垃圾回收算法并不需要这些代价。
- 单元池 free list 实现的话不是 cache-friendly 的,这样会导致频繁的 cache miss,降低程序运行效率。
标记-清除(mark & sweep)
标记-清除算法是第一种自动内存管理,基于追踪的垃圾收集算法。算法思想在 70 年代就提出了,是一种非常古老的算法。内存单元并不会在变成垃圾立刻回收,而是保持不可达状态,直到到达某个阈值或者固定时间长度。这个时候系统会挂起用户程序,也就是 STW,转而执行垃圾回收程序。
垃圾回收程序对所有的存活单元进行一次全局遍历确定哪些单元可以回收。算法分两个部分:标记(mark)和清除(sweep)。标记阶段表明所有的存活单元,清除阶段将垃圾单元回收。
标记-清除算法的优点也就是基于追踪的垃圾回收算法具有的优点:避免了引用计数算法的缺点(不能处理循环引用,需要维护指针)。缺点也很明显,需要 STW。
三色标记算法是对标记阶段的改进,原理如下:
- 起初所有对象都是白色。
- 从根出发扫描所有可达对象,标记为灰色,放入待处理队列。
- 从队列取出灰色对象,将其引用对象标记为灰色放入队列,自身标记为黑色。
- 重复 3,直到灰色对象队列为空。此时白色对象即为垃圾,进行回收。
三色法标记主要是第一部分是扫描所有对象进行三色标记,标记为黑色、灰色和白色,标记完成后只有黑色和白色对象,黑色代表使用中对象,白色对象代表垃圾,灰色是白色过渡到黑色的中间临时状态,第二部分是清扫垃圾,即清理白色对象。
第一部分包含了栈扫描、标记和标记结束 3 个阶段。在栈扫描之前有 2 个重要的准备:STW(Stop The World)和开启写屏障(WB,Write Barrier)。
STW 是 Stop The World,指会暂停所有正在执行的用户线程/协程,进行垃圾回收的操作,在这之前会进行一些准备工作,比如开启 Write Barrier,把全局变量,以及每个 goroutine 中的 Root 对象 收集起来,Root 对象是标记扫描的源头,可以从 Root 对象依次索引到使用中的对象,STW 为垃圾对象的扫描和标记提供了必要的条件。
每个 P 都有一个 mcache ,每个 mcache 都有 1 个 Span 用来存放 TinyObject,TinyObject 都是不包含指针的对象,所以这些对象可以直接标记为黑色,然后关闭 STW。
每个 P 都有 1 个进行扫描标记的 goroutine,可以进行并发标记,关闭 STW 后,这些 goroutine 就变成可运行状态,接收 Go Scheduler 的调度,被调度时执行 1 轮标记,它负责第 1 部分任务:栈扫描、标记和标记结束。
栈扫描阶段就是把前面搜集的 Root 对象找出来,标记为黑色,然后把它们引用的对象也找出来,标记为灰色,并且加入到 gcWork 队列,gcWork 队列保存了灰色的对象,每个灰色的对象都是一个 Work。
后面可以进入标记阶段,它是一个循环,不断的从 gcWork 队列中取出 work,所指向的对象标记为黑色,该对象指向的对象标记为灰色,然后加入队列,直到队列为空。 然后进入标记结束阶段,再次开启 STW,不同的版本处理方式是不同的。
在 Go1.7 的版本是 Dijkstra 写屏障,这个写屏障只监控堆上指针数据的变动,由于成本原因,没有监控栈上指针的变动,由于应用 goroutine 和 GC 的标记 goroutine 都在运行,当栈上的指针指向的对象变更为白色对象时,这个白色对象应当标记为黑色,需要再次扫描全局变量和栈,以免释放这类不该释放的对象。
在 Go1.8 及以后的版本引入了混合写屏障,这个写屏障依然不监控栈上指针的变动,但是它的策略,使得无需再次扫描栈和全局变量,但依然需要 STW 然后进行一些检查。
标记结束阶段的最后会关闭写屏障,然后关闭 STW,唤醒熟睡已久的负责清扫垃圾的 goroutine。
清扫 goroutine 是应用启动后立即创建的一个后台 goroutine,它会立刻进入睡眠,等待被唤醒,然后执行垃圾清理:把白色对象挨个清理掉,清扫 goroutine 和应用 goroutine 是并发进行的。清扫完成之后,它再次进入睡眠状态,等待下次被唤醒。
最后执行一些数据统计和状态修改的工作,并且设置好触发下一轮 GC 的阈值,把 GC 状态设置为 Off。
这写基本是 Go 垃圾回收的流程,但是在 go1.12 的源码稍微有一些不同,例如在标记结束后,就开始设置各种状态数据以及把 GC 状态成了 Off,在开启一轮 GC 时,会自动检测当前是否处于 Off,如果不是 Off,则当前 goroutine 会调用清扫函数,帮助清扫 goroutine 一起清扫 span,实际的 Go 垃圾回收流程以源码为准。
这里需要提下 go 的对象大小定义:
- 大对象是大于 32KB 的.
- 小对象 16KB 到 32KB 的.
- Tiny 对象指大小在 1Byte 到 16Byte 之间并且不包含指针的对象.

三色标记的一个明显好处是能够让用户程序和 mark 并发的进行.
节点复制(Copying Garbage Collection)
节点复制也是基于追踪的算法。其将整个堆等分为两个半区(semi-space),一个包含现有数据,另一个包含已被废弃的数据。节点复制式垃圾收集从切换(flip)两个半区的角色开始,然后收集器在老的半区,也就是 Fromspace 中遍历存活的数据结构,在第一次访问某个单元时把它复制到新半区,也就是 Tospace 中去。 在 Fromspace 中所有存活单元都被访问过之后,收集器在 Tospace 中建立一个存活数据结构的副本,用户程序可以重新开始运行了。
- 优点
- 所有存活的数据结构都缩并地排列在 Tospace 的底部,这样就不会存在内存碎片的问题
- 获取新内存可以简单地通过递增自由空间指针来实现。
- 缺点
- 内存得不到充分利用,总有一半的内存空间处于浪费状态。
分代收集(Generational Garbage Collection)
基于追踪的垃圾回收算法(标记-清扫、节点复制)一个主要问题是在生命周期较长的对象上浪费时间(长生命周期的对象是不需要频繁扫描的)。同时,内存分配存在这么一个事实 “most object die young”。基于这两点,分代垃圾回收算法将对象按生命周期长短存放到堆上的两个(或者更多)区域,这些区域就是分代(generation)。对于新生代的区域的垃圾回收频率要明显高于老年代区域。
分配对象的时候从新生代里面分配,如果后面发现对象的生命周期较长,则将其移到老年代,这个过程叫做 promote。随着不断 promote,最后新生代的大小在整个堆的占用比例不会特别大。收集的时候集中主要精力在新生代就会相对来说效率更高,STW 时间也会更短。
- 优点
- 性能更优。
- 缺点
- 实现复杂。
Golang GC
Golang GC 有两种,非增量式垃圾回收和增量式垃圾回收.
- 非增量式垃圾回收需要 STW,在 STW 期间完成所有垃圾对象的标记,STW 结束后慢慢的执行垃圾对象的清理。
- 增量式垃圾回收也需要 STW,在 STW 期间完成部分垃圾对象的标记,然后结束 STW 继续执行用户线程,一段时间后再次执行 STW 再标记部分垃圾对象,这个过程会多次重复执行,直到所有垃圾对象标记完成。
GC 算法有 3 大性能指标:吞吐量、最大暂停时间(最大的 STW 占时)、内存占用率。增量式垃圾回收不能提高吞吐量,但和非增量式垃圾回收相比,每次 STW 的时间更短,能够降低最大暂停时间,就是 Go 每个版本 Release Note 中提到的 GC 延迟、GC 暂停时间。
然而 Golang GC STW 的时候减少最大暂停时间还有一种思路:并发垃圾回收,注意不是并行垃圾回收。
并行垃圾回收是每个核上都跑垃圾回收的线程,同时进行垃圾回收,这期间为 STW,会暂停用户线程的执行。
并发垃圾回收是先 STW 找到所有的 Root 对象,然后结束 STW,让垃圾标记线程和用户线程并发执行,垃圾标记完成后,再次开启 STW,再次扫描和标记,以免释放使用中的内存。
并发垃圾回收和并行垃圾回收的重要区别就是不会持续暂停用户线程,并发垃圾回收也降低了 STW 的时间,达到了减少最大暂停时间的目的。
- 但是什么时候会触发 GC?
在堆上分配大于 32K byte 对象的时候进行检测此时是否满足垃圾回收条件,如果满足则进行垃圾回收。
|
|
上面是自动垃圾回收,还有一种是主动垃圾回收,通过调用 runtime.GC(),这是阻塞式的。
|
|
- GC 触发条件
GC 有 3 种触发方式:
- 辅助 GC
在分配内存时,会判断当前的 Heap 内存分配量是否达到了触发一轮 GC 的阈值(每轮 GC 完成后,该阈值会被动态设置),如果超过阈值,则启动一轮 GC。
-
调用 runtime.GC()强制启动一轮 GC。
-
sysmon 是运行时的守护进程,当超过 forcegcperiod (2 分钟)没有运行 GC 会启动一轮 GC。
forceTrigger 是 forceGC 的标志,后面意思是当前堆上的活跃对象大于我们初始化时候设置的 GC 触发阈值。在 malloc 以及 free 的时候 heap_live 会一直进行更新,这里就不再展开了。
|
|
- forcegc
自动检测和用户主动调用, 除此之外 Golang 本身还会对运行状态进行监控,如果超过两分钟没有 GC,则触发 GC。监控函数是 sysmon(),在主 goroutine 中启动。
|
|
- 垃圾回收的主要流程
为什么需要三色标记?
三色标记的目的,主要是利用 Tracing GC(Tracing GC 是垃圾回收的一个大类,另外一个大类是引用计数)做增量式垃圾回收,降低最大暂停时间。原生 Tracing GC 只有黑色和白色,没有中间的状态,这就要求 GC 扫描过程必须一次性完成,得到最后的黑色和白色对象。在前面增量式 GC 中介绍到了,这种方式会存在较大的暂停时间。
三色标记增加了中间状态灰色,增量式 GC 运行过程中,应用线程的运行可能改变了对象引用树,只要让黑色对象直接引用白色对象,GC 就可以增量式的运行,减少停顿时间。
什么是三色标记?
三色标记,通过字面意思我们就可以知道它由 3 种颜色组成:
-
黑色 Black:表示对象是可达的,即使用中的对象,黑色是已经被扫描的对象。
-
灰色 Gary:表示被黑色对象直接引用的对象,但还没对它进行扫描。
-
白色 White:白色是对象的初始颜色,如果扫描完成后,对象依然还是白色的,说明此对象是垃圾对象。
三色标记规则:黑色不能指向白色对象。即黑色可以指向灰色,灰色可以指向白色。
三色标记法,主要流程如下:
-
初始所有对象被标记为白色。
-
从 root 开始找到所有可达对象,标记为灰色,放入待处理队列。
-
遍历灰色对象队列,将其引用对象标记为灰色放入待处理队列,自身标记为黑色。
-
处理完灰色对象队列,直到没有灰色对象。
-
剩余白色对象为垃圾对象,执行清扫工作。
详细的过程如下图所示:

这里需要解释下:
-
首先从 root 开始遍历,root 包括全局指针和 goroutine 栈上的指针。
-
mark 有两个过程。第一是从 root 开始遍历,标记为灰色。遍历灰色队列。第二 re-scan 全局指针和栈。因为 mark 和用户程序是并行的,所以在过程 1 的时候可能会有新的对象分配,这个时候就需要通过写屏障(write barrier)记录下来。re-scan 再完成检查一下。
-
Stop The World 有两个过程。第一个是 GC 将要开始的时候,这个时候主要是一些准备工作,比如 enable write barrier。第二个过程就是上面提到的 re-scan 过程。如果这个时候没有 stw,那么 mark 将无休止。
另外针对上图各个阶段对应 GCPhase 如下:
- Off: _GCoff
- Stack scan - Mark: _GCmark
- Mark termination: _GCmarktermination
写屏障 (write barrier)
垃圾回收中的 write barrier 可以理解为编译器在写操作时特意插入的一段代码,对应的还有 read barrier。
为什么需要 write barrier,很简单,对于和用户程序并发运行的垃圾回收算法,用户程序会一直修改内存,所以需要记录下来。
Golang 1.7 之前的 write barrier 使用的经典的 Dijkstra-style insertion write barrier [Dijkstra ‘78], STW 的主要耗时就在 stack re-scan 的过程。自 1.8 之后采用一种混合的 write barrier 方式 (Yuasa-style deletion write barrier [Yuasa ‘90] 和 Dijkstra-style insertion write barrier [Dijkstra ‘78])来避免 re-scan。
标记
垃圾回收的代码主要集中在函数 gcStart() 中。
|
|
- STW phase 1
在 GC 开始之前的准备工作。
|
|
- Mark
Mark 阶段是并行的运行,通过在后台一直运行 mark worker 来实现。
|
|
Mark 阶段的标记代码主要在函数 gcDrain() 中实现。
|
|
- Mark termination (STW phase 2)
mark termination 阶段会 stop the world。函数实现在 gcMarkTermination()。
|
|
清扫
|
|
并行式清扫,在 GC 初始化的时候就会启动 bgsweep(),然后在后台一直循环
|
|
不管是阻塞式还是并行式,都是通过 sweepone()函数来做清扫工作的.内存管理都是基于 span 的,mheap* 是一个全局的变量,所有分配的对象都会记录在 mheap* 中。在标记的时候,我们只要找到对对象对应的 span 进行标记,清扫的时候扫描 span,没有标记的 span 就可以回收了。
|
|
GC 调节参数
Go 垃圾回收为了保证使用的简洁性,只提供了一个参数 GOGC。GOGC 代表了占用中的内存增长比率,达到该比率时应当触发 1 次 GC,该参数可以通过环境变量设置。
GOGC 参数取值范围为 0~100,默认值是 100,单位是百分比。
假如当前 heap 占用内存为 4MB,GOGC = 75,
|
|
等 heap 占用内存大小达到 7MB 时会触发 1 轮 GC。
GOGC 还有 2 个特殊值:
-
“off” : 代表关闭 GC
-
0 : 代表持续进行垃圾回收,只用于调试
其他
- gcWork
每个 P 上都有一个 gcw 用来管理灰色对象(get 和 put),gcw 的结构就是 gcWork。gcWork 中的核心是 wbuf1 和 wbuf2,里面存储就是灰色对象,或者说是 work(下面就全部统一叫做 work)。
|
|
既然每个 P 上有一个 work buffer,那么是不是还有一个全局的 work list 呢?是的。通过在每个 P 上绑定一个 work buffer 的好处和 cache 一样,不需要加锁。
|
|
那么为什么使用两个 work buffer (wbuf1 和 wbuf2)呢?例如我现在要 get 一个 work 出来,先从 wbuf1 中取,wbuf1 为空的话则与 wbuf2 swap 再 get。在其他时间将 work buffer 中的 full 或者 empty buffer 移到 global 的 work 中。 这样的好处在于,在 get 的时候去全局的 work 里面取(多个 goroutine 去取会有竞争)。这里有趣的是 global 的 work list 是 lock-free 的,通过原子操作 cas 等实现。下面列举几个函数看一下 gcWrok。
- 初始化
|
|
- put
|
|
- get
|
|
参考资料
- Tracing Garbage Collection - wikipedia
- On-the-fly Garbage Collection: an exercise in cooperation.
- Garbage Collection
- Tracing Garbage Collection
- Copying Garbage Collection
- Generational Garbage Collection
- Golang Gc Talk
- Eliminate Rescan
我们在上一节中详细介绍了 Go 语言内存分配器的设计与实现原理,分析了运行时内存管理组件之间的关系以及不同类型对象的分配原理,然而编程语言的内存管理系统除了负责堆内存的分配之外,它还需要负责回收不再使用的对象和内存空间,这部分职责就是由本节即将介绍的垃圾收集器完成的。
在几乎所有的现代编程语言中,垃圾收集器都是一个复杂的系统,为了在不影响用户程序的情况下回收废弃的内存需要付出非常多的努力,Java 的垃圾收集机制是一个很好的例子,Java 8 中包含线性、并发、并行标记清除和 G1 四个垃圾收集器1,想要理解它们的工作原理和实现细节需要花费很多的精力。
本节会详细介绍 Go 语言运行时系统中垃圾收集器的设计与实现原理,我们不仅会讨论常见的垃圾收集机制、从 Go 语言的 v1.0 版本开始分析其演进过程,还会深入源代码分析垃圾收集器的工作原理;接下来,我们进入 Go 语言内存管理的另一个重要组成部分 — 垃圾收集。
设计原理
今天的编程语言通常会使用手动和自动两种方式管理内存,C、C++ 以及 Rust 等编程语言使用手动的方式管理内存2,工程师需要主动申请或者释放内存;而 Python、Ruby、Java 和 Go 等语言使用自动的内存管理系统,一般都是垃圾收集机制,不过 Objective-C 却选择了自动引用计数3,虽然引用计数也是自动的内存管理机制,但是我们在这里不会详细介绍它,本节的重点还是垃圾收集。
相信很多人对垃圾收集器的印象都是暂停程序(Stop the world,STW),随着用户程序申请越来越多的内存,系统中的垃圾也逐渐增多;当程序的内存占用达到一定阈值时,整个应用程序就会全部暂停,垃圾收集器会扫描已经分配的所有对象并回收不再使用的内存空间,当这个过程结束后,用户程序才可以继续执行,Go 语言在早期也使用这种策略实现垃圾收集,但是今天的实现已经复杂了很多。
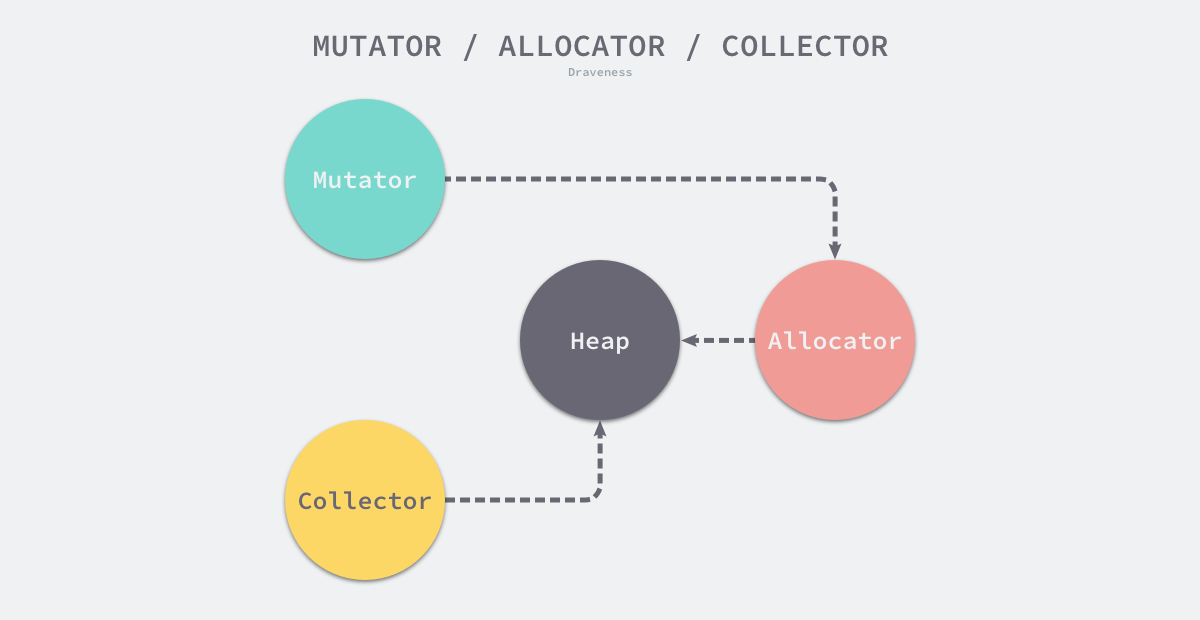
在上图中,用户程序(Mutator)会通过内存分配器(Allocator)在堆上申请内存,而垃圾收集器(Collector)负责回收堆上的内存空间,内存分配器和垃圾收集器共同管理着程序中的堆内存空间。我们在这一节中将详细介绍 Go 语言垃圾收集中涉及的关键理论,帮助我们更好地理解本节剩下的内容。
标记清除
标记清除(Mark-Sweep)算法是最常见的垃圾收集算法,标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表;
如下图所示,内存空间中包含多个对象,我们从根对象出发依次遍历对象的子对象并将从根节点可达的对象都标记成存活状态,即 A、C 和 D 三个对象,剩余的 B、E 和 F 三个对象因为从根节点不可达,所以会被当做垃圾:
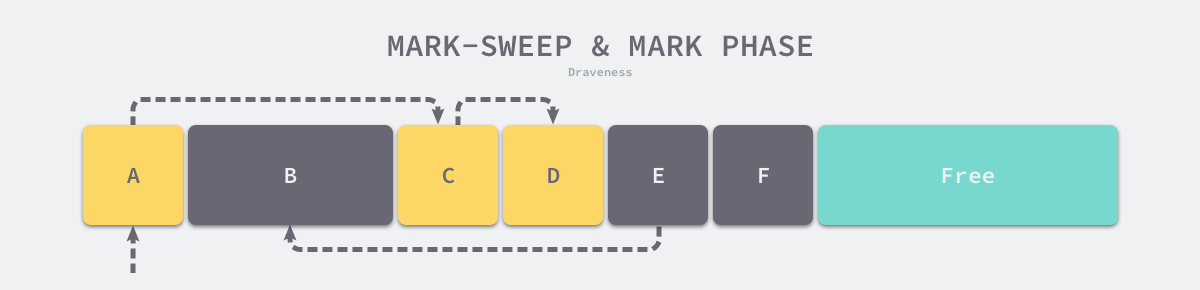
图 7-22 标记清除的标记阶段
标记阶段结束后会进入清除阶段,在该阶段中收集器会依次遍历堆中的所有对象,释放其中没有被标记的 B、E 和 F 三个对象并将新的空闲内存空间以链表的结构串联起来,方便内存分配器的使用。
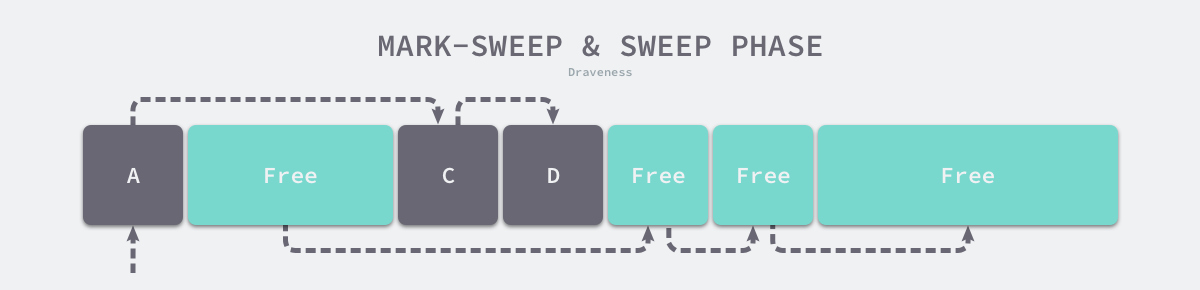
图 7-23 标记清除的清除阶段
这里介绍的是最传统的标记清除算法,垃圾收集器从垃圾收集的根对象出发,递归遍历这些对象指向的子对象并将所有可达的对象标记成存活;标记阶段结束后,垃圾收集器会依次遍历堆中的对象并清除其中的垃圾,整个过程需要标记对象的存活状态,用户程序在垃圾收集的过程中也不能执行,我们需要用到更复杂的机制来解决 STW 的问题。
三色抽象
为了解决原始标记清除算法带来的长时间 STW,多数现代的追踪式垃圾收集器都会实现三色标记算法的变种以缩短 STW 的时间。三色标记算法将程序中的对象分成白色、黑色和灰色三类4:
- 白色对象 — 潜在的垃圾,其内存可能会被垃圾收集器回收;
- 黑色对象 — 活跃的对象,包括不存在任何引用外部指针的对象以及从根对象可达的对象;
- 灰色对象 — 活跃的对象,因为存在指向白色对象的外部指针,垃圾收集器会扫描这些对象的子对象;
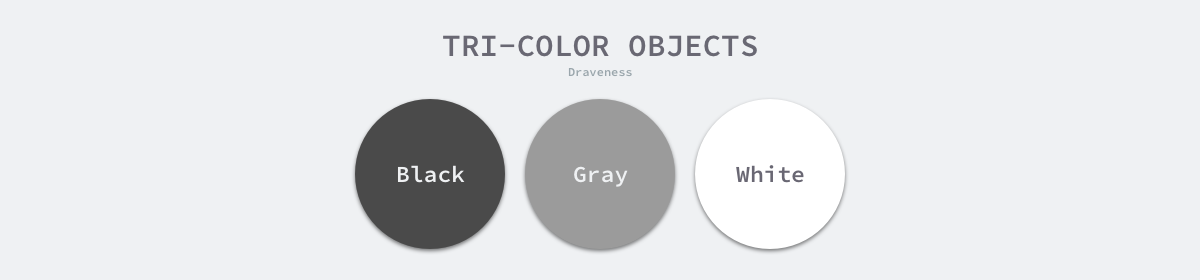
图 7-24 三色的对象
在垃圾收集器开始工作时,程序中不存在任何的黑色对象,垃圾收集的根对象会被标记成灰色,垃圾收集器只会从灰色对象集合中取出对象开始扫描,当灰色集合中不存在任何对象时,标记阶段就会结束。
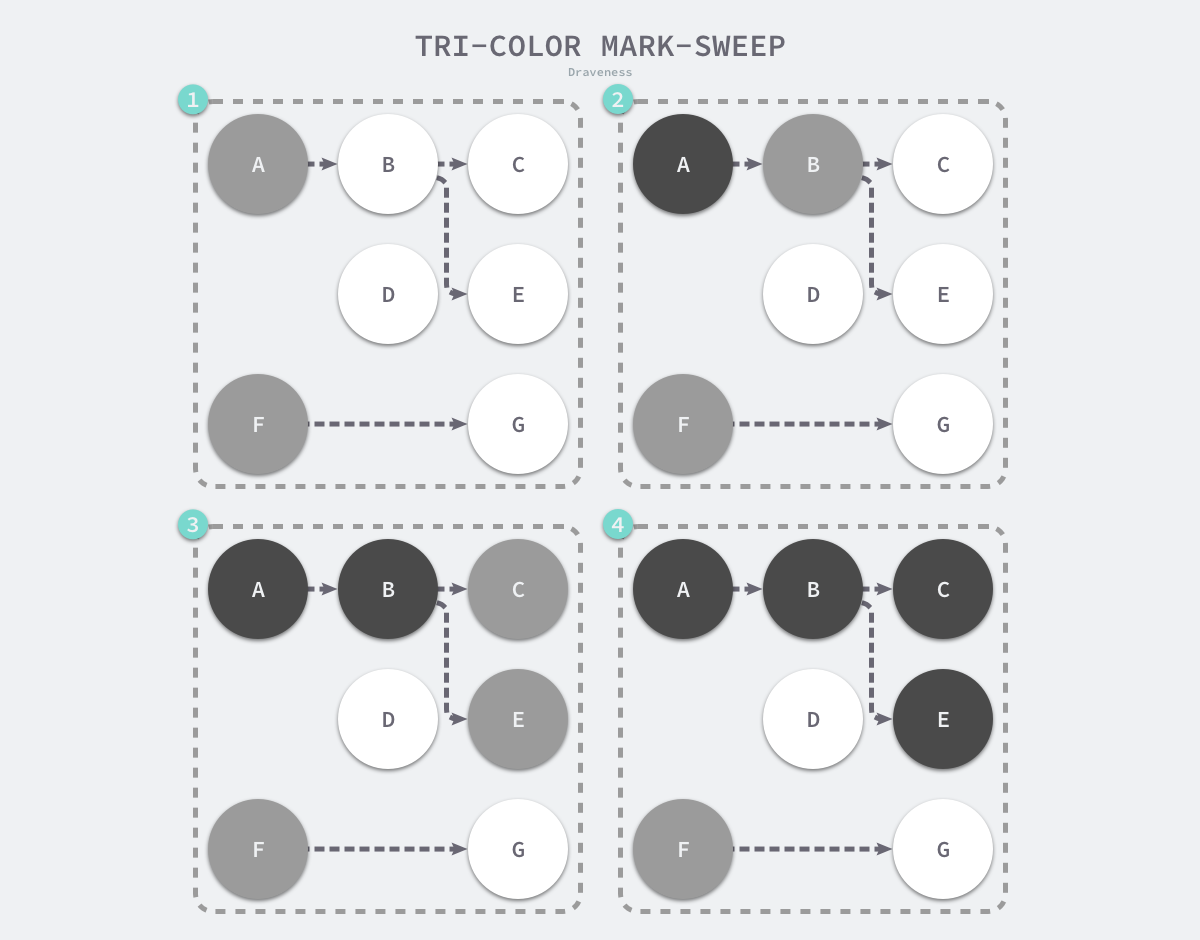
图 7-25 三色标记垃圾收集器的执行过程
三色标记垃圾收集器的工作原理很简单,我们可以将其归纳成以下几个步骤:
- 从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
- 将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
- 重复上述两个步骤直到对象图中不存在灰色对象;
当三色的标记清除的标记阶段结束之后,应用程序的堆中就不存在任何的灰色对象,我们只能看到黑色的存活对象以及白色的垃圾对象,垃圾收集器可以回收这些白色的垃圾,下面是使用三色标记垃圾收集器执行标记后的堆内存,堆中只有对象 D 为待回收的垃圾:
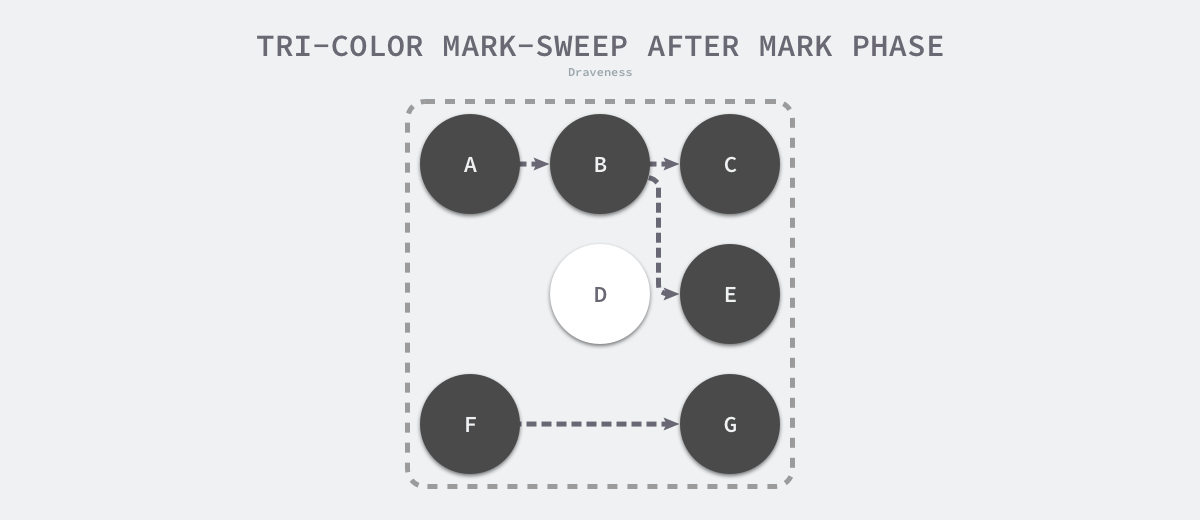
图 7-26 三色标记后的堆
因为用户程序可能在标记执行的过程中修改对象的指针,所以三色标记清除算法本身是不可以并发或者增量执行的,它仍然需要 STW,在如下所示的三色标记过程中,用户程序建立了从 A 对象到 D 对象的引用,但是因为程序中已经不存在灰色对象了,所以 D 对象会被垃圾收集器错误地回收。
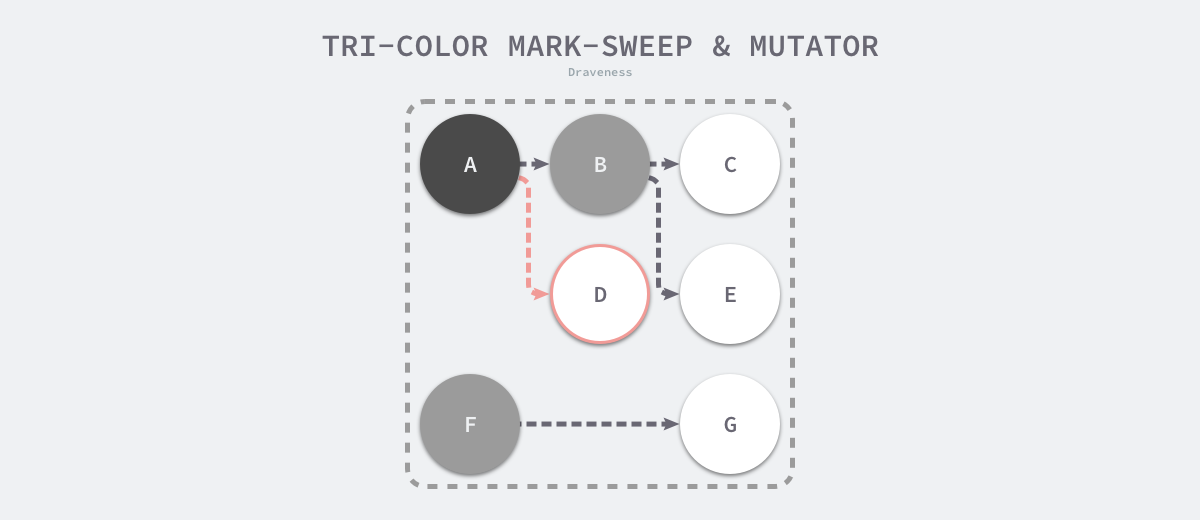
图 7-27 三色标记与用户程序
本来不应该被回收的对象却被回收了,这在内存管理中是非常严重的错误,我们将这种错误称为悬挂指针,即指针没有指向特定类型的合法对象,影响了内存的安全性5,想要并发或者增量地标记对象还是需要使用屏障技术。
屏障技术
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前的多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证代码对内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作6。
想要在并发或者增量的标记算法中保证正确性,我们需要达成以下两种三色不变性(Tri-color invariant)中的任意一种:
- 强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径7;
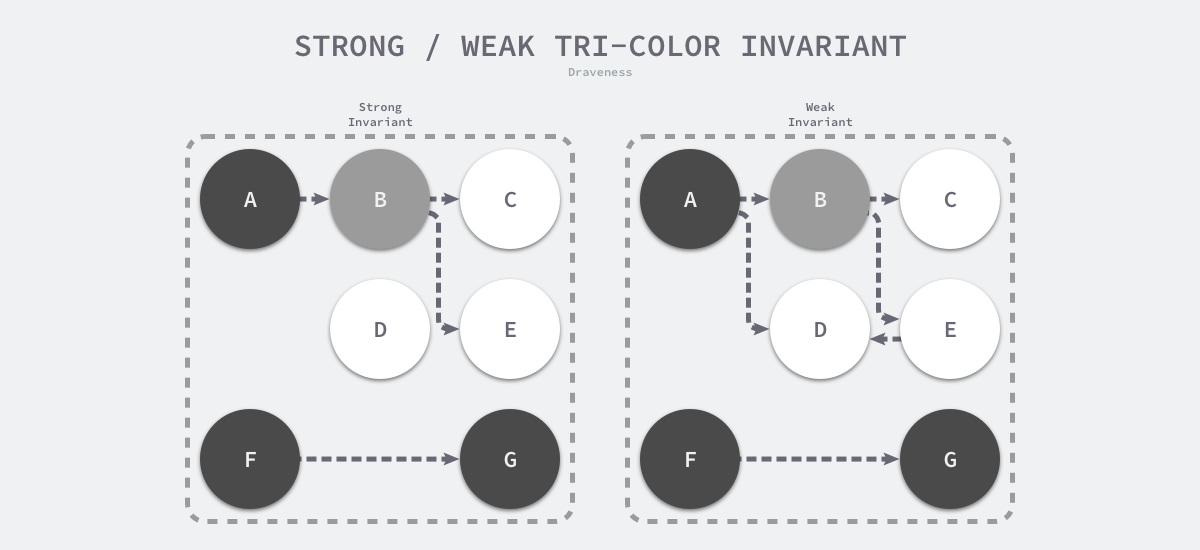
图 7-28 三色不变性
上图分别展示了遵循强三色不变性和弱三色不变性的堆内存,遵循上述两个不变性中的任意一个,我们都能保证垃圾收集算法的正确性,而屏障技术就是在并发或者增量标记过程中保证三色不变性的重要技术。
垃圾收集中的屏障技术更像是一个钩子方法,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,根据操作类型的不同,我们可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。
我们在这里想要介绍的是 Go 语言中使用的两种写屏障技术,分别是 Dijkstra 提出的插入写屏障8和 Yuasa 提出的删除写屏障9,这里会分析它们如何保证三色不变性和垃圾收集器的正确性。
插入写屏障
Dijkstra 在 1978 年提出了插入写屏障,通过如下所示的写屏障,用户程序和垃圾收集器可以在交替工作的情况下保证程序执行的正确性:
|
|
上述插入写屏障的伪代码非常好理解,每当我们执行类似 *slot = ptr 的表达式时,我们会执行上述写屏障通过 shade 函数尝试改变指针的颜色。如果 ptr 指针是白色的,那么该函数会将该对象设置成灰色,其他情况则保持不变。
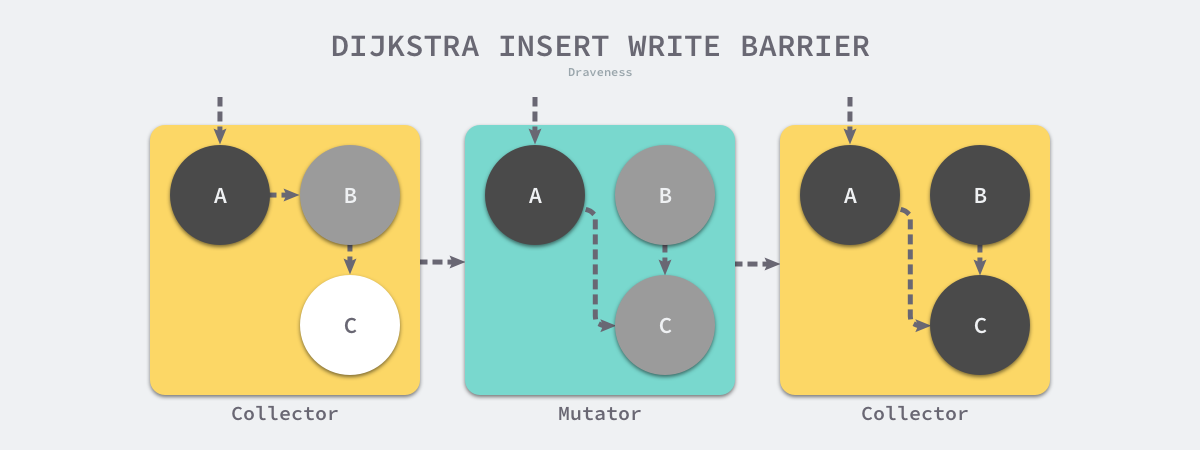
图 7-29 Dijkstra 插入写屏障
假设我们在应用程序中使用 Dijkstra 提出的插入写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序修改 A 对象的指针,将原本指向 B 对象的指针指向 C 对象,这时触发写屏障将 C 对象标记成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
Dijkstra 的插入写屏障是一种相对保守的屏障技术,它会将有存活可能的对象都标记成灰色以满足强三色不变性。在如上所示的垃圾收集过程中,实际上不再存活的 B 对象最后没有被回收;而如果我们在第二和第三步之间将指向 C 对象的指针改回指向 B,垃圾收集器仍然认为 C 对象是存活的,这些被错误标记的垃圾对象只有在下一个循环才会被回收。
插入式的 Dijkstra 写屏障虽然实现非常简单并且也能保证强三色不变性,但是它也有很明显的缺点。因为栈上的对象在垃圾收集中也会被认为是根对象,所以为了保证内存的安全,Dijkstra 必须为栈上的对象增加写屏障或者在标记阶段完成重新对栈上的对象进行扫描,这两种方法各有各的缺点,前者会大幅度增加写入指针的额外开销,后者重新扫描栈对象时需要暂停程序,垃圾收集算法的设计者需要在这两者之前做出权衡。
删除写屏障
Yuasa 在 1990 年的论文 Real-time garbage collection on general-purpose machines 中提出了删除写屏障,因为一旦该写屏障开始工作,它就会保证开启写屏障时堆上所有对象的可达,所以也被称作快照垃圾收集(Snapshot GC)10:
This guarantees that no objects will become unreachable to the garbage collector traversal all objects which are live at the beginning of garbage collection will be reached even if the pointers to them are overwritten.
该算法会使用如下所示的写屏障保证增量或者并发执行垃圾收集时程序的正确性:
|
|
上述代码会在老对象的引用被删除时,将白色的老对象涂成灰色,这样删除写屏障就可以保证弱三色不变性,老对象引用的下游对象一定可以被灰色对象引用。
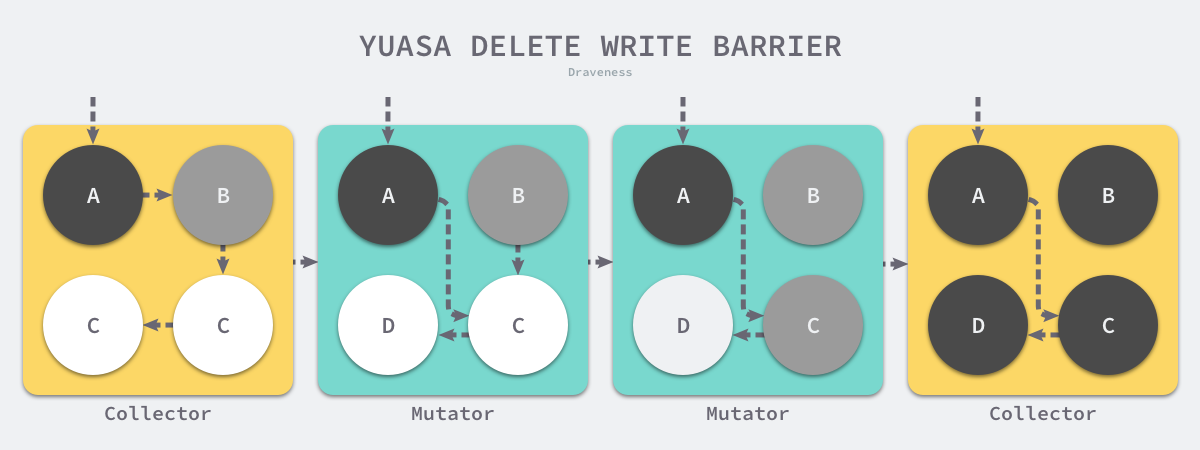
图 7-29 Yuasa 删除写屏障
假设我们在应用程序中使用 Yuasa 提出的删除写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序将 A 对象原本指向 B 的指针指向 C,触发删除写屏障,但是因为 B 对象已经是灰色的,所以不做改变;
- 用户程序将 B 对象原本指向 C 的指针删除,触发删除写屏障,白色的 C 对象被涂成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
上述过程中的第三步触发了 Yuasa 删除写屏障的着色,因为用户程序删除了 B 指向 C 对象的指针,所以 C 和 D 两个对象会分别违反强三色不变性和弱三色不变性:
- 强三色不变性 — 黑色的 A 对象直接指向白色的 C 对象;
- 弱三色不变性 — 垃圾收集器无法从某个灰色对象出发,经过几个连续的白色对象访问白色的 C 和 D 两个对象;
Yuasa 删除写屏障通过对 C 对象的着色,保证了 C 对象和下游的 D 对象能够在这一次垃圾收集的循环中存活,避免发生悬挂指针以保证用户程序的正确性。
增量和并发
传统的垃圾收集算法会在垃圾收集的执行期间暂停应用程序,一旦触发垃圾收集,垃圾收集器就会抢占 CPU 的使用权占据大量的计算资源以完成标记和清除工作,然而很多追求实时的应用程序无法接受长时间的 STW。
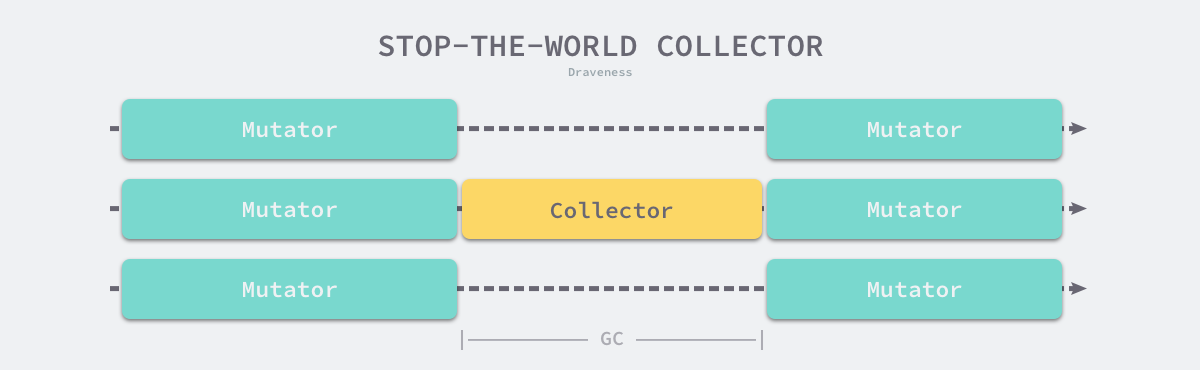
图 7-30 垃圾收集与暂停程序
远古时代的计算资源还没有今天这么丰富,今天的计算机往往都是多核的处理器,垃圾收集器一旦开始执行就会浪费大量的计算资源,为了减少应用程序暂停的最长时间和垃圾收集的总暂停时间,我们会使用下面的策略优化现代的垃圾收集器:
- 增量垃圾收集 — 增量地标记和清除垃圾,降低应用程序暂停的最长时间;
- 并发垃圾收集 — 利用多核的计算资源,在用户程序执行时并发标记和清除垃圾;
因为增量和并发两种方式都可以与用户程序交替运行,所以我们需要使用屏障技术保证垃圾收集的正确性;与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别,增量和并发的垃圾收集需要提前触发并在内存不足前完成整个循环,避免程序的长时间暂停。
增量收集器
增量式(Incremental)的垃圾收集是减少程序最长暂停时间的一种方案,它可以将原本时间较长的暂停时间切分成多个更小的 GC 时间片,虽然从垃圾收集开始到结束的时间更长了,但是这也减少了应用程序暂停的最大时间:

图 7-31 增量垃圾收集器
需要注意的是,增量式的垃圾收集需要与三色标记法一起使用,为了保证垃圾收集的正确性,我们需要在垃圾收集开始前打开写屏障,这样用户程序对内存的修改都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。虽然增量式的垃圾收集能够减少最大的程序暂停时间,但是增量式收集也会增加一次 GC 循环的总时间,在垃圾收集期间,因为写屏障的影响用户程序也需要承担额外的计算开销,所以增量式的垃圾收集也不是只有优点的。
并发收集器
并发(Concurrent)的垃圾收集不仅能够减少程序的最长暂停时间,还能减少整个垃圾收集阶段的时间,通过开启读写屏障、利用多核优势与用户程序并行执行,并发垃圾收集器确实能够减少垃圾收集对应用程序的影响:
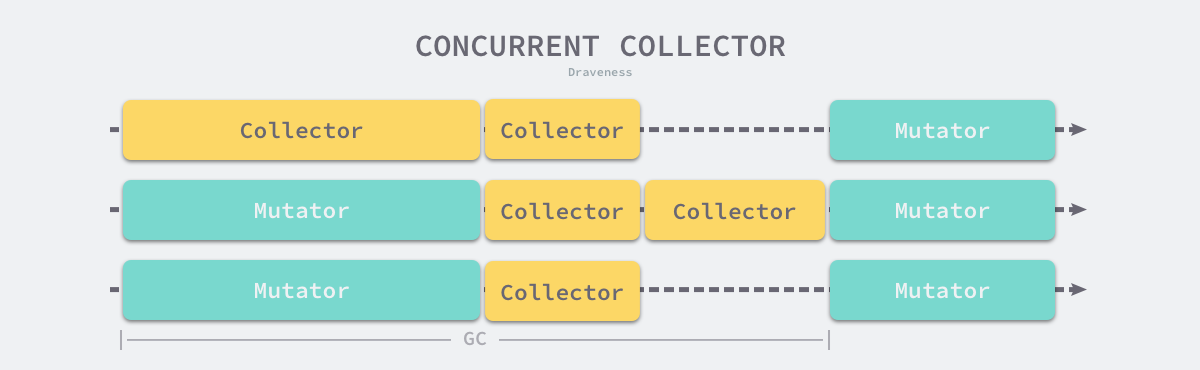
图 7-31 并发垃圾收集器
虽然并发收集器能够与用户程序一起运行,但是并不是所有阶段都可以与用户程序一起运行,部分阶段还是需要暂停用户程序的,不过与传统的算法相比,并发的垃圾收集可以将能够并发执行的工作尽量并发执行;当然,因为读写屏障的引入,并发的垃圾收集器也一定会带来额外开销,不仅会增加垃圾收集的总时间,还会影响用户程序,这是我们在设计垃圾收集策略时必须要注意的。
演进过程
Go 语言的垃圾收集器从诞生的第一天起就一直在演进,除了少数几个版本没有大更新之外,几乎每次发布的小版本都会提升垃圾收集的性能,而与性能一同提升的还有垃圾收集器代码的复杂度,本节将从 Go 语言 v1.0 版本开始分析垃圾收集器的演进过程。
-
v1.0 — 完全串行的标记和清除过程,需要暂停整个程序;
-
v1.3
— 运行时基于
只有指针类型的值包含指针
的假设增加了对栈内存的精确扫描支持,实现了真正精确的垃圾收集
;
- 将
unsafe.Pointer类型转换成整数类型的值认定为不合法的,可能会造成悬挂指针等严重问题;
- 将
-
v1.5
— 实现了基于
三色标记清扫的并发
垃圾收集器
;
- 大幅度降低垃圾收集的延迟从几百 ms 降低至 10ms 以下;
- 计算垃圾收集启动的合适时间并通过并发加速垃圾收集的过程;
-
v1.6
— 实现了
去中心化
的垃圾收集协调器;
- 基于显式的状态机使得任意 Goroutine 都能触发垃圾收集的状态迁移;
- 使用密集的位图替代空闲链表表示的堆内存,降低清除阶段的 CPU 占用14;
我们从 Go 语言垃圾收集器的演进能够看到该组件的的实现和算法变得越来越复杂,最开始的垃圾收集器还是不精确的单线程 STW 收集器,但是最新版本的垃圾收集器却支持并发垃圾收集、去中心化协调等特性,我们在这里将介绍与最新版垃圾收集器相关的组件和特性。
并发垃圾收集
Go 语言在 v1.5 中引入了并发的垃圾收集器,该垃圾收集器使用了我们上面提到的三色抽象和写屏障技术保证垃圾收集器执行的正确性,如何实现并发的垃圾收集器在这里就不展开介绍了,我们来了解一些并发垃圾收集器的工作流程。
首先,并发垃圾收集器必须在合适的时间点触发垃圾收集循环,假设我们的 Go 语言程序运行在一台 4 核的物理机上,那么在垃圾收集开始后,收集器会占用 25% 计算资源在后台来扫描并标记内存中的对象:

Go 语言的并发垃圾收集器会在扫描对象之前暂停程序做一些标记对象的准备工作,其中包括启动后台标记的垃圾收集器以及开启写屏障,如果在后台执行的垃圾收集器不够快,应用程序申请内存的速度超过预期,运行时就会让申请内存的应用程序辅助完成垃圾收集的扫描阶段,在标记和标记终止阶段结束之后就会进入异步的清理阶段,将不用的内存增量回收。
v1.5 版本实现的并发垃圾收集策略由专门的 Goroutine 负责在处理器之间同步和协调垃圾收集的状态。当其他的 Goroutine 发现需要触发垃圾收集时,它们需要将该信息通知给负责修改状态的主 Goroutine,然而这个通知的过程会带来一定的延迟,这个延迟的时间窗口很可能是不可控的,用户程序会在这段时间分配界面很多内存空间。
v1.6 引入了去中心化的垃圾收集协调机制22,将垃圾收集器变成一个显式的状态机,任意的 Goroutine 都可以调用方法触发状态的迁移,常见的状态迁移方法包括以下几个
runtime.gcStart— 从_GCoff转换至_GCmark阶段,进入并发标记阶段并打开写屏障;runtime.gcMarkDone— 如果所有可达对象都已经完成扫描,调用runtime.gcMarkTermination;runtime.gcMarkTermination— 从_GCmark转换_GCmarktermination阶段,进入标记终止阶段并在完成后进入_GCoff;
上述的三个方法就是在 runtime: replace GC coordinator with state machine 问题相关的提交中引入的,它们移除了过去中心化的状态迁移过程。
回收堆目标
STW 的垃圾收集器虽然需要暂停程序,但是它能够有效地控制堆内存的大小,Go 语言运行时的默认配置会在堆内存达到上一次垃圾收集的 2 倍时,触发新一轮的垃圾收集,这个行为可以通过环境变量 GOGC 调整,在默认情况下它的值为 100,即增长 100% 的堆内存才会触发 GC。

图 7-33 STW 垃圾收集器的垃圾收集时间
因为并发垃圾收集器会与程序一起运行,所以它无法准确的控制堆内存的大小,并发收集器需要在达到目标前触发垃圾收集,这样才能够保证内存大小的可控,并发收集器需要尽可能保证垃圾收集结束时的堆内存与用户配置的 GOGC 一致。

图 7-34 并发收集器的堆内存
Go 语言 v1.5 引入并发垃圾收集器的同时使用垃圾收集调步(Pacing)算法计算触发的垃圾收集的最佳时间,确保触发的时间既不会浪费计算资源,也不会超出预期的堆大小。如上图所示,其中黑色的部分是上一次垃圾收集后标记的堆大小,绿色部分是上次垃圾收集结束后新分配的内存,因为我们使用并发垃圾收集,所以黄色的部分就是在垃圾收集期间分配的内存,最后的红色部分是垃圾收集结束时与目标的差值,我们希望尽可能减少红色部分内存,降低垃圾收集带来的额外开销以及程序的暂停时间。
垃圾收集调步算法是跟随 v1.5 一同引入的,该算法的目标是优化堆的增长速度和垃圾收集器的 CPU 利用率23,而在 v1.10 版本中又对该算法进行了优化,将原有的目的堆大小拆分成了软硬两个目标24,因为调整垃圾收集的执行频率涉及较为复杂的公式,对理解垃圾收集原理帮助较为有限,本节就不展开介绍了,感兴趣的读者可以自行阅读。
混合写屏障
在 Go 语言 v1.7 版本之前,运行时会使用 Dijkstra 插入写屏障保证强三色不变性,但是运行时并没有在所有的垃圾收集根对象上开启插入写屏障。因为 Go 语言的应用程序可能包含成百上千的 Goroutine,而垃圾收集的根对象一般包括全局变量和栈对象,如果运行时需要在几百个 Goroutine 的栈上都开启写屏障,会带来巨大的额外开销,所以 Go 团队在实现上选择了在标记阶段完成时暂停程序、将所有栈对象标记为灰色并重新扫描,在活跃 Goroutine 非常多的程序中,重新扫描的过程需要占用 10 ~ 100ms 的时间。
Go 语言在 v1.8 组合 Dijkstra 插入写屏障和 Yuasa 删除写屏障构成了如下所示的混合写屏障,该写屏障会将被覆盖的对象标记成灰色并在当前栈没有扫描时将新对象也标记成灰色:
|
|
为了移除栈的重扫描过程,除了引入混合写屏障之外,在垃圾收集的标记阶段,我们还需要将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收,因为栈内存在标记阶段最终都会变为黑色,所以不再需要重新扫描栈空间。
实现原理
在介绍垃圾收集器的演进过程之前,我们需要对最新垃圾收集器的执行周期有一些初步的了解,这对我们了解其全局的设计会有比较大的帮助。Go 语言的垃圾收集可以分成清除终止、标记、标记终止和清除四个不同阶段,它们分别完成了不同的工作25:
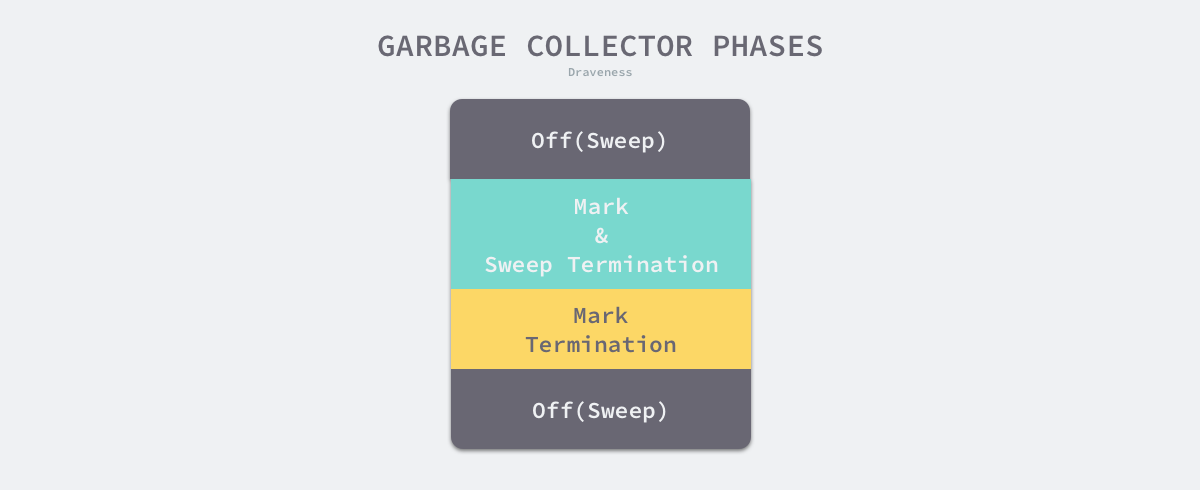
图 7-35 垃圾收集的多个阶段
- 清理终止阶段;
- 暂停程序,所有的处理器在这时会进入安全点(Safe point);
- 如果当前垃圾收集循环是强制触发的,我们还需要处理还未被清理的内存管理单元;
- 标记阶段;
- 将状态切换至
_GCmark、开启写屏障、用户程序协助(Mutator Assiste)并将根对象入队; - 恢复执行程序,标记进程和用于协助的用户程序会开始并发标记内存中的对象,写屏障会将被覆盖的指针和新指针都标记成灰色,而所有新创建的对象都会被直接标记成黑色;
- 开始扫描根对象,包括所有 Goroutine 的栈、全局对象以及不在堆中的运行时数据结构,扫描 Goroutine 栈期间会暂停当前处理器;
- 依次处理灰色队列中的对象,将对象标记成黑色并将它们指向的对象标记成灰色;
- 使用分布式的终止算法检查剩余的工作,发现标记阶段完成后进入标记终止阶段;
- 将状态切换至
- 标记终止阶段;
- 暂停程序、将状态切换至
_GCmarktermination并关闭辅助标记的用户程序; - 清理处理器上的线程缓存;
- 暂停程序、将状态切换至
- 清理阶段;
- 将状态切换至
_GCoff开始清理阶段,初始化清理状态并关闭写屏障; - 恢复用户程序,所有新创建的对象会标记成白色;
- 后台并发清理所有的内存管理单元,当 Goroutine 申请新的内存管理单元时就会触发清理;
- 将状态切换至
运行时虽然只会使用 _GCoff、_GCmark 和 _GCmarktermination 三个状态表示垃圾收集的全部阶段,但是在实现上却复杂很多,本节将按照垃圾收集的不同阶段详细分析其实现原理。
全局变量
在垃圾收集中有一些比较重要的全局变量,在分析其过程之前,我们会先逐一介绍这些重要的变量,这些变量在垃圾收集的各个阶段中会反复出现,所以理解他们的功能是非常重要的,我们先介绍一些比较简单的变量:
runtime.gcphase是垃圾收集器当前处于的阶段,可能处于_GCoff、_GCmark和_GCmarktermination,Goroutine 在读取或者修改该阶段时需要保证原子性;runtime.gcBlackenEnabled是一个布尔值,当垃圾收集处于标记阶段时,该变量会被置为 1,在这里辅助垃圾收集的用户程序和后台标记的任务可以将对象涂黑;runtime.gcController实现了垃圾收集的调步算法,它能够决定触发并行垃圾收集的时间和待处理的工作;runtime.gcpercent是触发垃圾收集的内存增长百分比,默认情况下为 100,即堆内存相比上次垃圾收集增长 100% 时应该触发 GC,并行的垃圾收集器会在到达该目标前完成垃圾收集;runtime.writeBarrier是一个包含写屏障状态的结构体,其中的enabled字段表示写屏障的开启与关闭;runtime.worldsema是全局的信号量,获取该信号量的线程有权利暂停当前应用程序;
除了上述全局的变量之外,我们在这里还需要简单了解一下 runtime.work 变量:
|
|
该结构体中包含大量垃圾收集的相关字段,例如:表示完成的垃圾收集循环的次数、当前循环时间和 CPU 的利用率、垃圾收集的模式等等,我们会在后面的小节中见到该结构体中的更多的字段。
触发时机
运行时会通过如下所示的 runtime.gcTrigger.test 方法决定是否需要触发垃圾收集,当满足触发垃圾收集的基本条件时 — 允许垃圾收集、程序没有崩溃并且没有处于垃圾收集循环,该方法会根据三种不同的方式触发进行不同的检查:
|
|
gcTriggerHeap— 堆内存的分配达到达控制器计算的触发堆大小;gcTriggerTime— 如果一定时间内没有触发,就会触发新的循环,该出发条件由runtime.forcegcperiod变量控制,默认为 2 分钟;gcTriggerCycle— 如果当前没有开启垃圾收集,则触发新的循环;
用于开启垃圾收集的方法 runtime.gcStart 会接收一个 runtime.gcTrigger 类型的谓词,我们可以根据这个触发 _GCoff 退出的结构体找到所有触发的垃圾收集的代码:
runtime.sysmon和runtime.forcegchelper— 后台运行定时检查和垃圾收集;runtime.GC— 用户程序手动触发垃圾收集;runtime.mallocgc— 申请内存时根据堆大小触发垃圾收集;
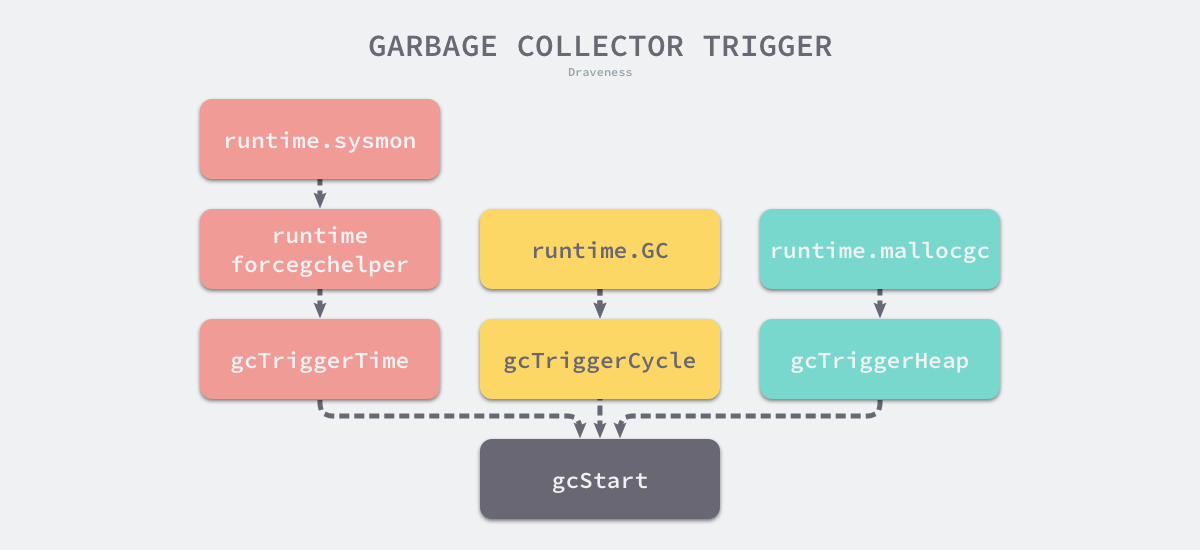
图 7-36 垃圾收集的触发
除了使用后台运行的系统监控器和强制垃圾收集助手触发垃圾收集之外,另外两个方法会从任意处理器上触发垃圾收集,这种不需要中心组件协调的方式就是在 v1.6 版本中引入的,接下来我们将展开介绍这三种不同的触发时机。
后台触发
运行时会在应用程序启动时在后台开启一个用于强制触发垃圾收集的 Goroutine,该 Goroutine 的职责非常简单 — 调用 runtime.gcStart 方法尝试启动新一轮的垃圾收集:
|
|
为了减少对计算资源的占用,该 Goroutine 会在循环中调用 runtime.goparkunlock 主动陷入休眠等待其他 Goroutine 的唤醒,runtime.forcegchelper 在大多数时间都是陷入休眠的,但是它会被系统监控器 runtime.sysmon 在满足垃圾收集条件时唤醒:
|
|
系统监控在每个循环中都会主动构建一个 runtime.gcTrigger 并检查垃圾收集的触发条件是否满足,如果满足条件,系统监控会将 runtime.forcegc 状态中持有的 Goroutine 加入全局队列等待调度器的调度。
手动触发
用户程序会通过 runtime.GC 函数在程序运行期间主动通知运行时执行,该方法在调用时会阻塞调用方知道当前垃圾收集循环完成,在垃圾收集期间也可能会通过 STW 暂停整个程序:
|
|
- 在正式开始垃圾收集前,运行时需要通过
runtime.gcWaitOnMark函数等待上一个循环的标记终止、标记和标记终止阶段完成; - 调用
runtime.gcStart触发新一轮的垃圾收集并通过runtime.gcWaitOnMark等待该轮垃圾收集的标记终止阶段正常结束; - 持续调用
runtime.sweepone清理全部待处理的内存管理单元并等待所有的清理工作完成,等待期间会调用runtime.Gosched让出处理器; - 完成本轮垃圾收集的清理工作后,通过
runtime.mProf_PostSweep将该阶段的堆内存状态快照发布出来,我们可以获取这时的内存状态;
手动触发垃圾收集的过程不是特别常见,一般只会在运行时的测试代码中才会出现,不过如果我们认为触发主动垃圾收集是有必要的,我们也可以直接调用该方法,但是作者并不认为这是一种推荐的做法。
申请内存
最后一个可能会触发垃圾收集的就是 runtime.mallocgc 函数了,我们在上一节内存分配器中曾经介绍过运行时会将堆上的对象按大小分成微对象、小对象和大对象三类,这三类对象的创建都可能会触发新的垃圾收集循环:
|
|
- 当前线程的内存管理单元中不存在空闲空间时,创建微对象和小对象需要调用
runtime.mcache.nextFree方法从中心缓存或者页堆中获取新的管理单元,在这时就可能触发垃圾收集; - 当用户程序申请分配 32KB 以上的大对象时,一定会构建
runtime.gcTrigger结构体尝试触发 垃圾收集;
通过堆内存触发垃圾收集需要比较 runtime.mstats 中的两个字段 — 表示垃圾收集中存活对象字节数的 heap_live 和表示触发标记的堆内存大小的 gc_trigger;当内存中存活的对象字节数大于触发垃圾收集的堆大小时,新一轮的垃圾收集就会开始。在这里,我们将分别介绍这两个值的计算过程:
heap_live— 为了减少锁竞争,运行时只会在中心缓存分配或者释放内存管理单元以及在堆上分配大对象时才会更新;gc_trigger— 在标记终止阶段调用runtime.gcSetTriggerRatio更新触发下一次垃圾收集的堆大小;
runtime.gcController 会在每个循环结束后计算触发比例并通过 runtime.gcSetTriggerRatio 设置 gc_trigger,它能够决定触发垃圾收集的时间以及用户程序和后台处理的标记任务的多少,利用反馈控制的算法根据堆的增长情况和垃圾收集 CPU 利用率确定触发垃圾收集的时机。
你可以在 runtime.gcControllerState.endCycle 方法中找到 v1.5 提出的垃圾收集调步算法26,并在 runtime.gcControllerState.revise 方法中找到 v1.10 引入的软硬堆目标分离算法27。
垃圾收集启动
垃圾收集在启动过程一定会调用 runtime.gcStart 函数,虽然该函数的实现比较复杂,但是它的主要职责就是修改全局的垃圾收集状态到 _GCmark 并做一些准备工作,我们会分以下几个阶段介绍该函数的实现:
- 两次调用
runtime.gcTrigger.test方法检查是否满足垃圾收集条件; - 暂停程序、在后台启动用于处理标记任务的工作 Goroutine、确定所有内存管理单元都被清理以及其他标记阶段开始前的准备工作;
- 进入标记阶段、准备后台的标记工作、根对象的标记工作以及微对象、恢复用户程序,进入并发扫描和标记阶段;
验证垃圾收集条件的同时,该方法还会在循环中不断调用 runtime.sweepone 清理已经被标记的内存单元,完成上一个垃圾收集循环的收尾工作:
|
|
在验证了垃圾收集的条件并完成了收尾工作后,该方法会通过 semacquire 获取全局的 worldsema 信号量、调用 runtime.gcBgMarkStartWorkers 启动后台标记任务、在系统栈中调用 runtime.stopTheWorldWithSema 暂停程序并调用 runtime.finishsweep_m 保证上一个内存单元的正常回收:
|
|
除此之外,上述过程还会修改全局变量 runtime.work 持有的状态,包括垃圾收集需要的 Goroutine 数量以及已完成的循环数。
在完成全部的准备工作后,盖该方法就进入了执行的最后阶段。在该阶段中,我们会修改全局的垃圾收集状态到 _GCmark 并依次执行下面的步骤:
- 调用
runtime.gcBgMarkPrepare函数初始化后台扫描需要的状态; - 调用
runtime.gcMarkRootPrepare函数扫描栈上、全局变量等根对象并将它们加入队列; - 设置全局变量
runtime.gcBlackenEnabled,用户程序和标记任务可以将对象涂黑; - 调用
runtime.startTheWorldWithSema启动程序,后台任务也会开始标记堆中的对象;
|
|
在分析垃圾收集的启动过程中,我们省略了几个关键的过程,其中包括暂停和恢复应用程序和后台任务的启动,下面将详细分析这几个过程的实现原理。
暂停与恢复程序
runtime.stopTheWorldWithSema 和 runtime.startTheWorldWithSema 是一对用于暂停和恢复程序的核心函数,它们有着完全相反的功能,但是程序的暂停会比恢复要复杂一些,我们来看一下前者的实现原理:
|
|
暂停程序主要使用了 runtime.preemptall 函数,该函数会调用我们在前面介绍过的 runtime.preemptone,因为程序中活跃的最大处理数为 gomaxprocs,所以 runtime.stopTheWorldWithSema 在每次发现停止的处理器时都会对该变量减一,直到所有的处理器都停止运行。该函数会依次停止当前处理器、等待处于系统调用的处理器以及获取并抢占空闲的处理器,处理器的状态在该函数返回时都会被更新至 _Pgcstop,等待垃圾收集器的重新唤醒。
程序恢复过程会使用 runtime.startTheWorldWithSema,该函数的实现也相对比较简单:
- 调用
runtime.netpoll从网络轮询器中获取待处理的任务并加入全局队列; - 调用
runtime.procresize扩容或者缩容全局的处理器; - 调用
runtime.notewakeup或者runtime.newm依次唤醒处理器或者为处理器创建新的线程; - 如果当前待处理的 Goroutine 数量过多,创建额外的处理器辅助完成任务;
|
|
程序的暂停和启动过程都比较简单,暂停程序会使用 runtime.preemptall 抢占所有的处理器,恢复程序时会使用 runtime.notewakeup 或者 runtime.newm 唤醒程序中的处理器。
后台标记模式
在垃圾收集启动期间,运行时会调用 runtime.gcBgMarkStartWorkers 为全局每个处理器创建用于执行后台标记任务的 Goroutine,每一个 Goroutine 都会运行 runtime.gcBgMarkWorker,所有运行 runtime.gcBgMarkWorker 的 Goroutine 在启动后都会陷入休眠等待调度器的唤醒:
|
|
这些 Goroutine 与处理器是一一对应的关系,当垃圾收集处于标记阶段并且当前处理器不需要做任何任务时,runtime.findrunnable 函数会在当前处理器上执行该 Goroutine 辅助并发的对象标记:

图 7-37 处理器与后台标记任务
调度器在调度循环 runtime.schedule 中还可以通过垃圾收集控制器的 runtime.gcControllerState.findRunnabledGCWorker 方法获取并执行用于后台标记的任务。
用于并发扫描对象的工作协程 Goroutine 总共有三种不同的模式 runtime.gcMarkWorkerMode,这三种不同模式的 Goroutine 在标记对象时使用完全不同的策略,垃圾收集控制器会按照需要执行不同类型的工作协程:
gcMarkWorkerDedicatedMode— 处理器专门负责标记对象,不会被调度器抢占;gcMarkWorkerFractionalMode— 当垃圾收集的后台 CPU 使用率达不到预期时(默认为 25%),启动该类型的工作协程帮助垃圾收集达到利用率的目标,因为它只占用同一个 CPU 的部分资源,所以可以被调度;gcMarkWorkerIdleMode— 当处理器没有可以执行的 Goroutine 时,它会运行垃圾收集的标记任务直到被抢占;
runtime.gcControllerState.startCycle 会根据全局处理器的个数以及垃圾收集的 CPU 利用率计算出上述的 dedicatedMarkWorkersNeeded 和 fractionalUtilizationGoal 以决定不同模式的工作协程的数量。
因为后台标记任务的 CPU 利用率为 25%,如果主机是 4 核或者 8 核,那么垃圾收集需要 1 个或者 2 个专门处理相关任务的 Goroutine;不过如果主机是 3 核或者 6 核,因为无法被 4 整除,所以这时需要 0 个或者 1 个专门处理垃圾收集的 Goroutine,运行时需要占用某个 CPU 的部分时间,使用 gcMarkWorkerFractionalMode 模式的协程保证 CPU 的利用率。

图 7-38 主机核数与垃圾收集任务模式
垃圾收集控制器会在 runtime.gcControllerState.findRunnabledGCWorker 方法中设置处理器的 gcMarkWorkerMode:
|
|
上述方法的实现比较清晰,控制器通过 dedicatedMarkWorkersNeeded 决定专门执行标记任务的 Goroutine 数量并根据执行标记任务的时间和总时间决定是否启动 gcMarkWorkerFractionalMode 模式的 Goroutine;除了这两种控制器要求的工作协程之外,调度器还会在 runtime.findrunnable 函数中利用空闲的处理器执行垃圾收集以加速该过程:
|
|
三种不同模式的工作协程会相互协同保证垃圾收集的 CPU 利用率达到期望的阈值,在到达目标堆大小前完成标记任务。
并发扫描与标记辅助
runtime.gcBgMarkWorker 是后台的标记任务执行的函数,该函数的循环中执行了对内存中对象图的扫描和标记,我们分三个部分介绍该函数的实现原理:
- 获取当前处理器以及 Goroutine 打包成
parkInfo类型的结构体并主动陷入休眠等待唤醒; - 根据处理器上的
gcMarkWorkerMode模式决定扫描任务的策略; - 所有标记任务都完成后,调用
runtime.gcMarkDone方法完成标记阶段;
首先我们来看后台标记任务的准备工作,运行时在这里创建了一个 parkInfo 结构体,该结构体会预先存储处理器和当前 Goroutine,当我们调用 runtime.gopark 触发休眠时,运行时会在系统栈中安全地建立处理器和后台标记任务的绑定关系:
|
|
通过 runtime.gopark 陷入休眠的 Goroutine 不会进入运行队列,它只会等待垃圾收集控制器或者调度器的直接唤醒;在唤醒后,我们会根据处理器 gcMarkWorkerMode 选择不同的标记执行策略,不同的执行策略都会调用 runtime.gcDrain 扫描工作缓冲区 runtime.gcWork:
|
|
需要注意的是,gcMarkWorkerDedicatedMode 模式的任务是不能被抢占的,为了减少额外开销,第一次调用 runtime.gcDrain 方法时是允许抢占的,但是一旦处理器被抢占,当前 Goroutine会将处理器上的所有可运行的 Goroutine 转移至全局队列中,保证垃圾收集占用的 CPU 资源。当所有的后台工作任务都陷入等待并且没有剩余工作时,我们就认为该轮垃圾收集的标记阶段结束了,这时我们会调用 runtime.gcMarkDone 函数:
|
|
runtime.gcDrain 是用于扫描和标记堆内存中对象的核心方法,除了该方法之外,我们还会介绍工作池、写屏障以及标记辅助的实现原理。
工作池
在调用 runtime.gcDrain 函数时,运行时会传入处理器上的 runtime.gcWork,这个结构体是垃圾收集器中工作池的抽象,它实现了一个生产者和消费者的模型,我们可以以该结构体为起点从整体理解标记工作:
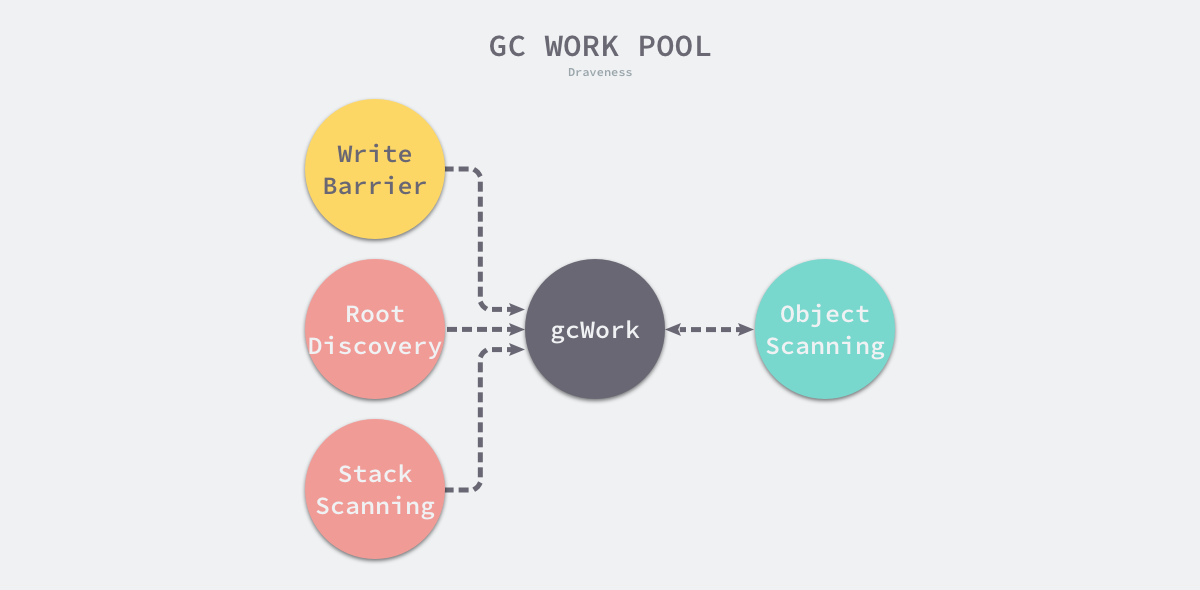
图 7-39 垃圾收集器工作池
写屏障、根对象扫描和栈扫描都会向工作池中增加额外的灰色对象等待处理,而对象的扫描过程会将灰色对象标记成黑色,同时也可能发现新的灰色对象,当工作队列中不包含灰色对象时,整个扫描过程就会结束。
为了减少锁竞争,运行时在每个处理器上会保存独立的待扫描工作,然而这会遇到与调度器一样的问题 — 不同处理器的资源不平均,导致部分处理器无事可做,调度器引入了工作窃取来解决这个问题,垃圾收集器也使用了差不多的机制平衡不同处理器上的待处理任务。
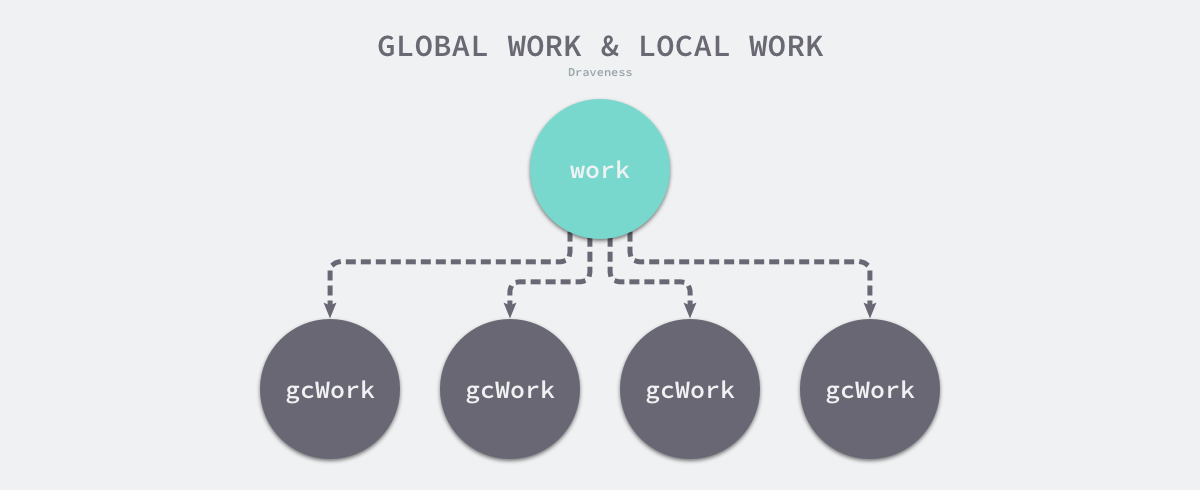
图 7-40 全局任务与本地任务
runtime.gcWork.balance 方法会将处理器本地一部分工作放回全局队列中,让其他的处理器处理,保证不同处理器负载的平衡。
runtime.gcWork 为垃圾收集器提供了生产和消费任务的抽象,该结构体持有了两个重要的工作缓冲区 wbuf1 和 wbuf2,这两个缓冲区分别是主缓冲区和备缓冲区:
|
|
当我们向该结构体中增加或者删除对象时,它总会先操作主缓冲区,一旦主缓冲区空间不足或者没有对象,就会触发主备缓冲区的切换;而当两个缓冲区空间都不足或者都为空时,会从全局的工作缓冲区中插入或者获取对象,该结构体相关方法的实现都非常简单,这里就不展开分析了。
扫描对象
运行时会使用 runtime.gcDrain 函数扫描工作缓冲区中的灰色对象,它会根据传入 gcDrainFlags 的不同选择不同的策略:
|
|
gcDrainUntilPreempt— 当 Goroutine 的preempt字段被设置成 true 时返回;gcDrainIdle— 调用runtime.pollWork函数,当处理器上包含其他待执行 Goroutine 时返回;gcDrainFractional— 调用runtime.pollFractionalWorkerExit函数,当 CPU 的占用率超过fractionalUtilizationGoal的 20% 时返回;gcDrainFlushBgCredit— 调用runtime.gcFlushBgCredit计算后台完成的标记任务量以减少并发标记期间的辅助垃圾收集的用户程序的工作量;
运行时会使用本地变量中的 check 函数检查当前是否应该退出标记任务并让出该处理器。当我们做完准备工作后,就可以开始扫描全局变量中的根对象了,这也是标记阶段中需要最先被执行的任务:
|
|
扫描根对象需要使用 runtime.markroot 函数,该函数会扫描缓存、数据段、存放全局变量和静态变量的 BSS 段以及 Goroutine 的栈内存;一旦完成了对根对象的扫描,当前 Goroutine 会开始从本地和全局的工作缓存池中获取待执行的任务:
|
|
扫描对象会使用 runtime.scanobject,该函数会从传入的位置开始扫描,扫描期间会调用 runtime.greyobject 为找到的活跃对象上色。
|
|
当本轮的扫描因为外部条件变化而中断时,该函数会通过 runtime.gcFlushBgCredit 记录这次扫描的内存字节数用于减少辅助标记的工作量。
内存中对象的扫描和标记过程涉及很多位操作和指针操作,相关代码实现比较复杂,我们在这里就不展开介绍相关的内容了,感兴趣的读者可以将 runtime.gcDrain 作为入口研究三色标记的具体过程。
写屏障
写屏障是保证 Go 语言并发标记安全不可获取的技术,我们需要使用混合写屏障维护对象图的弱三色不变性,然而写屏障的实现需要编译器和运行时的共同协作。在 SSA 中间代码生成阶段,编译器会使用 cmd/compile/internal/ssa.writebarrier 函数在 Store、Move 和 Zero 操作中加入写屏障,生成如下所示的代码:
|
|
当 Go 语言进入垃圾收集阶段时,全局变量 runtime.writeBarrier 中的 enabled 字段会被置成开启,所有的写操作都会调用 runtime.gcWriteBarrier:
|
|
在上述汇编函数中,DI 寄存器是写操作的目的地址,AX 寄存器中存储了被覆盖的值,该函数会覆盖原来的值并通过 runtime.wbBufFlush 通知垃圾收集器将原值和新值加入当前处理器的工作队列,因为该写屏障的实现比较复杂,所以写屏障对程序的性能还是有比较大的影响,之前只需要一条指令完成的工作,现在需要几十条指令。
我们在上面提到过 Dijkstra 和 Yuasa 写屏障组成的混合写屏障在开启后,所有新创建的对象都需要被直接涂成黑色,这里的标记过程是由 runtime.gcmarknewobject 完成的:
|
|
runtime.mallocgc 会在垃圾收集开始后调用该函数,获取对象对应的内存单元以及标记位 runtime.markBits 并调用 runtime.markBits.setMarked 直接将新的对象涂成黑色。
标记辅助
为了保证用户程序分配内存的速度不会超出后台任务的标记速度,运行时还引入了标记辅助技术,它遵循一条非常简单并且朴实的原则,分配多少内存就需要完成多少标记任务。每一个 Goroutine 都持有 gcAssistBytes 字段,这个字段存储了当前 Goroutine 辅助标记的对象字节数。在并发标记阶段期间,当 Goroutine 调用 runtime.mallocgc 分配新的对象时,该函数会检查申请内存的 Goroutine 是否处于入不敷出的状态:
|
|
申请内存时调用的 runtime.gcAssistAlloc 和扫描内存时调用的 runtime.gcFlushBgCredit 分别负责『借债』和『还债』,通过这套债务管理系统,我们能够保证 Goroutine 在正常运行的同时不会为垃圾收集造成太多的压力,保证在达到堆大小目标时完成标记阶段。
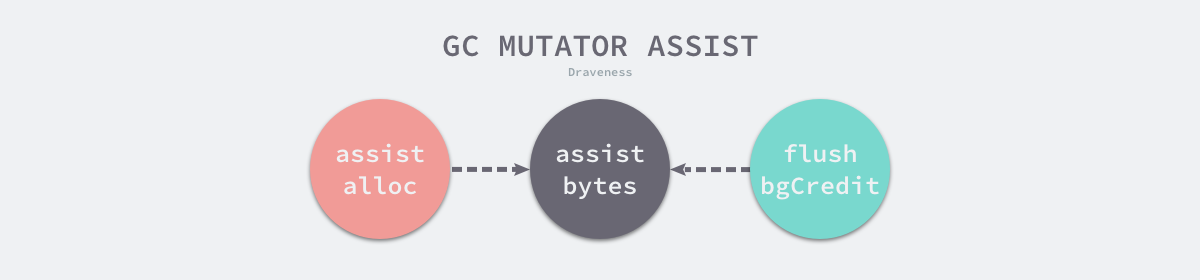
图 7-41 辅助标记的动态平衡
每个 Goroutine 持有的 gcAssistBytes 表示当前协程辅助标记的字节数,全局垃圾收集控制器持有的 bgScanCredit 表示后台协程辅助标记的字节数,当本地 Goroutine 分配了较多的对象时,可以使用公用的信用 bgScanCredit 偿还。我们先来分析 runtime.gcAssistAlloc 函数的实现:
|
|
该函数会先根据 Goroutine 的 gcAssistBytes 和垃圾收集控制器的配置计算需要完成的标记任务数量,如果全局信用 bgScanCredit 中有可用的点数,那么就会减去该点数,因为并发执行没有加锁,所以全局信用可能会被更新成负值,然而在长期来看这不是一个比较重要的问题。
如果全局信用不足以覆盖本地的债务,运行时会在系统栈中调用 runtime.gcAssistAlloc1 执行标记任务,该函数会直接调用 runtime.gcDrainN 完成指定数量的标记任务并返回:
|
|
如果在完成标记辅助任务后,当前 Goroutine 仍然入不敷出并且 Goroutine 没有被抢占,那么运行时会执行 runtime.gcParkAssist;在该函数中,如果全局信用依然不足,runtime.gcParkAssist 会将当前 Goroutine 陷入休眠、加入全局的辅助标记队列并等待后台标记任务的唤醒。
用于还债的 runtime.gcFlushBgCredit 实现比较简单,如果辅助队列中不存在等待的 Goroutine,那么当前的信用会直接加到全局信用 bgScanCredit 中:
|
|
如果辅助队列不为空,上述函数会根据每个 Goroutine 的债务数量和已完成的工作决定是否唤醒这些陷入休眠的 Goroutine;如果唤醒所有的 Goroutine 后,标记任务量仍然有剩余,这些标记任务都会加入全局信用中。
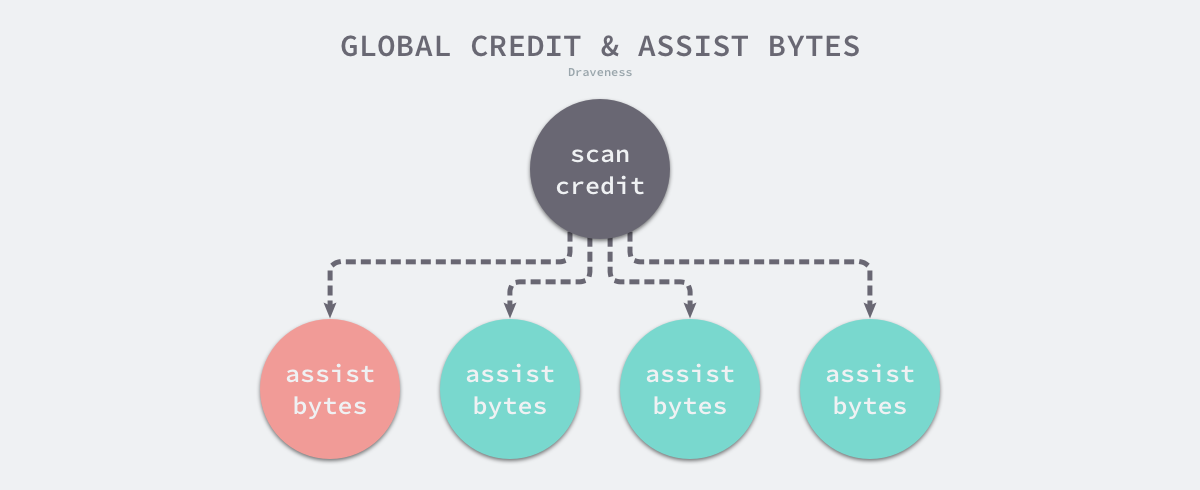
图 7-42 全局信用与本地信用
用户程序辅助标记的核心目的就是避免用户程序分配内存影响垃圾收集器完成标记工作的期望时间,它通过维护账户体系保证用户程序不会对垃圾收集造成过多的负担,一旦用户程序分配了大量的内存,该用户程序就会通过辅助标记的方式平衡账本,这个过程会在最后达到相对平衡,保证标记任务在到达期望堆大小时完成。
标记终止
当所有处理器的本地任务都完成并且不存在剩余的工作 Goroutine 时,后台并发任务或者辅助标记的用户程序会调用 runtime.gcMarkDone 通知垃圾收集器。当所有可达对象都被标记后,该函数会将垃圾收集的状态切换至 _GCmarktermination;如果本地队列中仍然存在待处理的任务,当前方法会将所有的任务加入全局队列并等待其他 Goroutine 完成处理:
|
|
如果运行时中不包含全局任务、处理器中也不存在本地任务,那么当前垃圾收集循环中的灰色对象也就都标记成了黑色,我们就可以开始触发垃圾收集的阶段迁移了:
|
|
上述函数在最后会关闭混合写屏障、唤醒所有协助垃圾收集的用户程序、恢复用户 Goroutine 的调度并调用 runtime.gcMarkTermination 进入标记终止阶段:
|
|
我们省略了撒行数函数中很多数据统计的代码,包括正在使用的内存大小、本轮垃圾收集的暂停时间、CPU 的利用率等数据,这些数据能够帮助控制器决定下一轮触发垃圾收集的堆大小,除了数据统计之外,该函数还会调用 runtime.gcSweep 重置清理阶段的相关状态并在需要时阻塞清理所有的内存管理单元;_GCmarktermination 状态在垃圾收集中并不会持续太久,它会迅速转换至 _GCoff 并恢复应用程序,到这里垃圾收集的全过程基本上就结束了,用户程序在申请内存时才会惰性回收内存。
内存清理
垃圾收集的清理中包含对象回收器(Reclaimer)和内存单元回收器,这两种回收器使用不同的算法清理堆内存:
- 对象回收器在内存管理单元中查找并释放未被标记的对象,但是如果
runtime.mspan中的所有对象都没有被标记,整个单元就会被直接回收,该过程会被runtime.mcentral.cacheSpan或者runtime.sweepone异步触发; - 内存单元回收器会在内存中查找所有的对象都未被标记的
runtime.mspan,该过程会被runtime.mheap.reclaim触发;
runtime.sweepone 是我们在垃圾收集过程中经常会见到的函数,该函数会在堆内存中查找待清理的内存管理单元:
|
|
查找内存管理单元时会通过 state 和 sweepgen 两个字段判断当前单元是否需要处理。如果内存单元的 sweepgen 等于 mheap.sweepgen - 2,那么就意味着当前单元需要被清理,如果等于 mheap.sweepgen - 1,那么当前管理单元就正在被清理。
所有的回收工作最终都是靠 runtime.mspan.sweep 完成的,该函数会根据并发标记阶段回收内存单元中的垃圾并清除标记以免影响下一轮垃圾收集。
小结
Go 语言垃圾收集器的实现非常复杂,作者认为这是编程语言中最复杂的一个模块,调度器的复杂度与垃圾收集器完全不是一个级别,我们在分析垃圾收集器的过程中不得不省略很多的实现细节,其中包括并发标记对象的过程、清扫垃圾的具体实现,这些过程设计大量底层的位操作和指针操作,本节中包含所有的相关代码的链接,感兴趣的读者可以自行探索。
垃圾收集是一门非常古老的技术,它的执行速度和利用率很大程度上决定了程序的运行速度,Go 语言为了实现高性能的并发垃圾收集器,使用三色抽象、并发增量回收、混合写屏障、调步算法以及用户程序协助等机制将垃圾收集的暂停时间优化至毫秒级以下,从早期的版本看到今天,我们能体会到其中的工程设计和演进,作者觉得分析垃圾收集的是实现还是非常有趣和值得的。
延伸阅读
- Garbage Collection In Go : Part I - Semantics
- Getting to Go: The Journey of Go’s Garbage Collector
- The Garbage Collection Handbook
- Immix: A Mark-Region Garbage Collector with Space Efficiency, Fast Collection, and Mutator Performance
- Go’s march to low-latency GC
- GopherCon 2015: Rick Hudson - Go GC: Solving the Latency Problem
- Go GC: Latency Problem Solved
- Concurrent garbage collection
- Design and Implementation of a Comprehensive Real-time Java Virtual Machine
-
No backlinks found.