eBPF Map 操作
eBPF Map 是用户空间和内核空间进行数据交换、信息传递的桥梁,它以 key/value 方式将数据存储在内核中,可以被任何知道它们的BPF程序访问。在内核空间的程序创建 BPF Map 并返回对应的 文件描述符,在用户空间运行的程序就可以通过这个文件描述符来访问并操作BPF Map。eBPF Map 支持多种数据结构类型,在 上一篇博客 中已经简单介绍过,本文将通过代码实例展示其使用方法,所有代码可以在我的 Github 中找到。
创建BPF Map
最初创建 BPF Map 的方式都是通过 bpf 系统调用函数,传入的第一个参数是BPF_MAP_CREATE,在 上一篇博客 中已经介绍,此处不在详述。
|
|
相对于直接使用 bpf 系统调用函数来创建BPF Map,在实际场景中常用的是基于 SEC("maps") 这个语法糖来做到声明即创建:
|
|
关键点就是SEC("maps"),ELF convention,它的工作原理是这样的:
- 声明 ELF Section 属性
SEC("maps") - 内核代码
bpf_load.c扫描目标文件中所有 Section 信息,它会扫描目标文件里定义的 Section,其中就有用来创建BPF Map的SEC("maps"),我们可以到相关代码里看到说明:
|
|
bpf_load.c扫描到SEC("maps")后,对BPF Map相关的操作是由load_maps函数完成,其中的bpf_create_map_node()和bpf_create_map_in_map_node()就是创建BPF Map的关键函数- 它们背后都是调用了定义在内核代码tools/lib/bpf/bpf.c中的方法,而这个方法就是使用上文提到的
BPF_MAP_CREATE命令进行的系统调用。 - 最后在编译程序时,通过添加
bpf_load.o作为依赖库,并合并为最终的可执行文件中,这样在程序运行起来时,就可以通过声明SEC("maps")即可完成创建BPF Map的行为了。
从上面梳理的过程可以看到,这个简化版虽然使用了语法糖,但最后还是会去使用 bpf() 函数完成系统调用。
数据结构
本小节将介绍 eBPF Map 的几种常见的数据结构,包括其使用场景和使用方法。
Hash Table
对于 BPF_MAP_TYPE_HASH 类型的 eBPF Map,其 key 和 value 都是可自定义的数据结构,使用方法如下所示:
|
|
Array
对于 BPF_MAP_TYPE_ARRAY 类型的 eBPF Map,有以下特性:
- 它的 key 是作为一个数组的索引,只能是 4 个字节
- 在 Array 初始化的时候,Array 中所有的元素都
pre-allocated并且初始化未 0 map_delete_elem()函数会返回EINVAL,因为 Array 中的元素不能够被删除map_update_elem()函数更新元素的时候是non-atomic的,并没有并发保护
BPF_MAP_TYPE_ARRAY 类型的 eBPF Map 主要用于以下两种情景:
-
全局变量:可以申请一个只有一个元素的 Array,key = 0,value 是一些全局变量的集合
-
aggregation of tracing events into fixed set of buckets
下面展示了使用 BPF_MAP_TYPE_ARRAY 作为全局变量的方法:
|
|
Prog Array
BPF_MAP_TYPE_PROG_ARRAY 类型的 eBPF Map 主要用于尾调用,尾调用执行涉及两个步骤:
- 设置类型为
BPF_MAP_TYPE_PROG_ARRAY的 map,这个 map 可以从用户空间通过 key/value 操作 - 调用辅助函数
bpf_tail_call()如下所示,内核将这个辅助函数调用内联到一个特殊的 BPF 指令内。目前,这样的程序数组在用户空间侧是只写模式- 一个对程序数组的引用(a reference to the program array)
- 一个查询 map 所用的 key。
|
|
内核根据传入的文件描述符查找相关的 BPF 程序,自动替换给定的 map slot 处的程序指针。如果没有找到给定的 key 对应的 value,内核会跳过(fall through)这一步 ,继续执行 bpf_tail_call() 后面的指令。
尾调用是一个强大的功能,它可以实现:
- 通过尾调用结构化地解析网络报头
- 运行时原子地添加或替换功能,也即动态地改变 BPF 程序的执行行为
在 samples/bpf 中可以看到 BPF_MAP_TYPE_PROG_ARRAY 的使用示例:
|
|
Map In Map
eBPF 提供了两种特殊的 Map 类型,BPF_MAP_TYPE_ARRAY_OF_MAPS 和 BPF_MAP_TYPE_HASH_OF_MAPS,实现了 map-in-map,也就是 eBPF Map 中每一个 entry 的 Value 也是一个 Map,如下所示:

BPF_MAP_TYPE_ARRAY_OF_MAPS 和 BPF_MAP_TYPE_HASH_OF_MAPS 的区别在于,outer map 是一个 Array 还是 HashTable。
Create
之前的常规 eBPF Map 是在 load time 创建的,对于 map-in-map,我们需要定义一个 outer map,inner map 是在 runtime 被用户创建并插入到 outer map。outer map 定义如下所示:
|
|
这里需要注意:
outer map的value_size必须是__u32,这正好是inner map id的大小
尽管你不需要在 BPF C 程序中定义 inner map,verifier 需要在 load time 知道 inner map 的定义。所以,在调用 bpf_object__load 前,你必须创建一个 dummy inner map 并且 通过调用 bpf_map__set_inner_map_fd 设置它的 fd 到 outer map 。注意,verifier 要求 dummy inner map 的 fd 必须在 load 之后关闭。
|
|
Insert
Insert Into Outer Map
插入到 outer map 步骤如下:
- 创建一个新的
inner map - 将创建的
inner map的 fd 作为 value 插入到outer map - 关闭
inner map fd
|
|
注意:
outer map的每一项 entry 的 value 是the id of an inner map,但是调用bpf_map_update_elemAPI 时给的参数是the fd of the inner map- 在插入之后你必须关闭
inner map fd以避免内存泄漏。
Insert Into Inner Map
如前所述,outer map 的每一项 entry 的 value 是 the id of an inner map,而不是 the fd of the inner map。即使我们在调用 bpf_map_update_elem 传递的参数是 inner map fd,使用 bpf_map_lookup_elem 的时候我们的到的 value 是 inner map id,为了获得 inner map fd,可以调用 bpf_map_get_fd_by_id。拿到 inner map fd 之后,就可以像之前一样操作 inner map 了。
|
|
注意,每次调用 bpf_map_get_fd_by_id 都会返回一个新的 fd,你必须在使用之后关闭它以避免内存泄露。
Delete
对于 inner map 的删除和常规 Map 一样,可以调用 bpf_map_delete_elem:
|
|
Perf Event Array
有时候我们期望 eBPF 程序能够通知用户态程序数据准备好了,array、hash 类型的 eBPF map 不满足此类使用场景,这时候就轮到 BPF_MAP_TYPE_PERF_EVENT_ARRAY 了。与普通 hash、array 类型有些不同,它没有 bpf_map_lookup_elem() 方法,使用的是 bpf_perf_event_output() 向用户态传递数据。它的 value_size 只能是 sizeof(u32),代表的是 perf_event 的文件描述符;max_entries 则是 perf_event 的文件描述符数量。
有关源码如下:
|
|
Note:
- 这里的
seq代表的是消息序列号- 若用户态不向内核态传递消息,PERF_EVENT_ARRAY map 中的
max_entries没有意义。该 map 向用户态传递的数据暂存在 perf ring buffer 中,而由max_entries指定的 map 存储空间存放的是 perf_event 文件描述符,若用户态程序不向 map 传递 perf_event 的文件描述符,其值可以为 0。用户态程序使用bpf(BPF_MAP_UPDATE_ELEM)将由sys_perf_event_open()取得的文件描述符传递给 eBPF 程序,eBPF 程序再使用bpf_perf_event_{read, read_value}()得到该文件描述符。于此有关的用法见 linux kernel 下的 sample/bpf/tracex6_{user, kern.c}。
libbpf 提供了 PERF_EVENT_ARRAY map 在用户态开箱即用的 API,它使用了 epoll 进行封装,仅需调用 perf_buffer__new()、perf_buffer__poll() 即可使用:
|
|
实战入门
现在我们就可以借助 BPF Map 来实现在内核空间收集网络包信息,主要包括源地址和目标地址,在用户空间展示这些信息。代码主要分两个部分:
- 一个是运行在内核空间的程序,主要功能为创建出定制版BPF Map,收集目标信息并存储至BPF Map中。
- 另一个是运行在用户空间的程序,主要功能为读取上面内核空间创建出的BPF Map里的数据,并进行格式化展示,以演示BPF Map在两者之间进行数据传递。
请注意,该程序的编译运行是基于Linux内核代码中BPF示例环境,如果你还不熟悉,可以参考 上一篇博客。
内核空间
下面首先介绍运行在内核空间的示例代码:
|
|
我们先来看运行在内核空间的BPF程序代码重点内容:
- 通过
SEC("maps")声明并创建了一个名为tracker_map 的BPF Map,它的类型是BPF_MAP_TYPE_HASH,它的 key 和 value 都是自定义的struct,定义在了xdp_ip_tracker_common.h头文件中,具体如下所示:
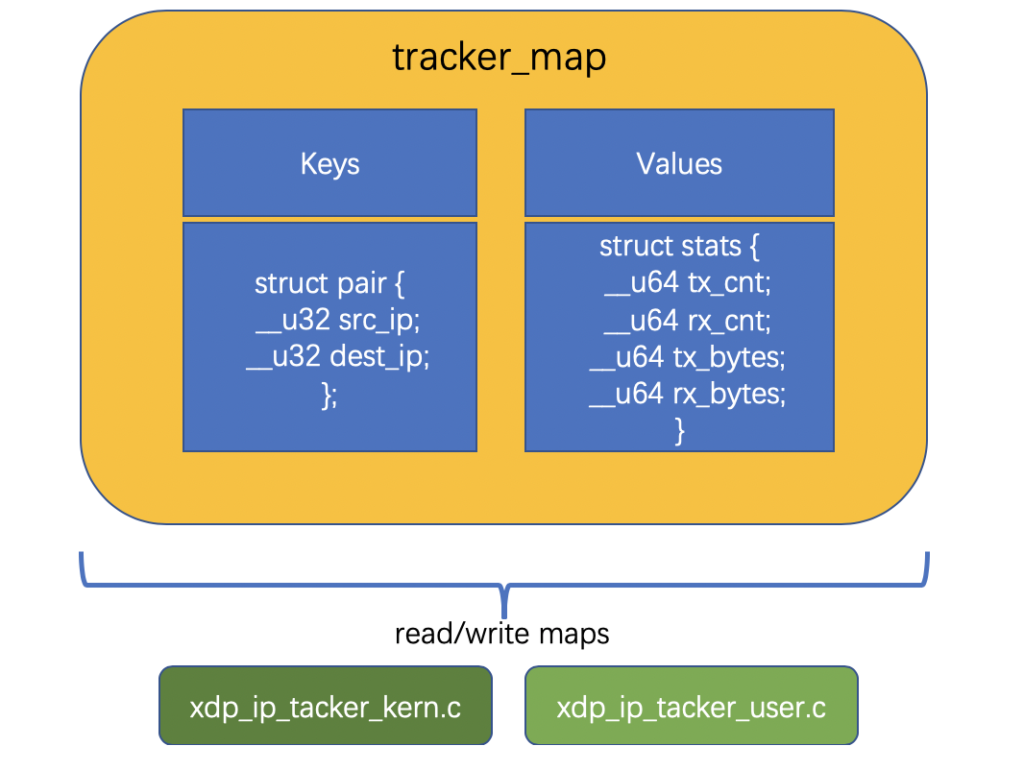
- 函数
parse_and_track是对网络包进行分析和过滤,把源地址和目的地址联合起来作为BPF Map的key,把当前网络包的大小以 byte 单位记录下来,并联合网络包计数器作为BPF Map的value。对于连续的网络包,如果生成的key已经存在,就把value累加,否则就新增一对key-value存入BPF Map中。其中通过bpf_map_lookup_elem()函数来查找元素,bpf_map_update_elem()函数来新增元素。
用户空间
接下来是运行在用户空间的示例代码:
|
|
- 用户空间的代码跟一般看到的C程序的结构是一样的,都是有main函数作为入口。基本流程是,通过
load_bpf_file()函数(本质就是用BPF_PROG_LOAD命令进行系统调用)加载对应内核空间的BPF程序编译出来的**.o**文件,这种通过编程加载BPF程序的方式,和我们之前通过命令行工具的方式相比,更具灵活性,适合实际场景中的产品分发。 - 加载完BPF程序之后,使用
set_link_xdp_fd()函数 attach 到目标hook上,看函数名就知道了,这是XDP network hook。它接受的两个主要的参数是:ifindex,这个是目标网卡的序号(可以通过ip a查看),我这里填写的是6,它是对应了一个docker容器的veth虚拟网络设备;prog_fd[0],这个是BPF程序加载到内存后生成的文件描述符fd。
- 有两个神奇的变量
prog_fd和map_fd得说明下:- 它们都是定义在
bpf_load.c的全局变量; prog_fd是一个数组,在加载内核空间BPF程序时,一旦fd生成后,就添加到这个数组中去;map_fd也是一个数组,在运行上文提到的load_maps()函数时,一旦完成创建BPF Map系统调用生成fd后,同样会添加到这个数组中去。 因此在bpf sample文件夹下的程序可以直接使用这两个变量,作为对于BPF程序和BPF Map的引用。
- 它们都是定义在
- 从代码 71 行开始是一个无限循环,里面是每2秒获取一下目标BPF Map的数据。获取的逻辑是通过
bpf_map_get_next_key(map_fd[0], &lookup_key, &next_key)函数,map_fd[0]是你的目标BPF Map;lookup_key是需要查找的BPF Map目标key,这个参数是要主动传入的,而next_key是这个目标key相邻的下一个key,这个参数是被动赋值的。如果你想从头开始遍历BPF Map,就可以通过传入一个一定不存在的key作为lookup_key,然后next_key会被自动赋值为BPF Map中第一个key,key知道了,对应的value也就可以被读取了,直到bpf_map_get_next_key()返回为-1,即next_key没有可以被赋值的了,遍历也就完成了,这个函数工作起来是不是像一个iterator。 通过上面两层循环,不停遍历BPF Map并打印里面的内容,一旦有新的网络包进来,也能及时获取到相关信息。
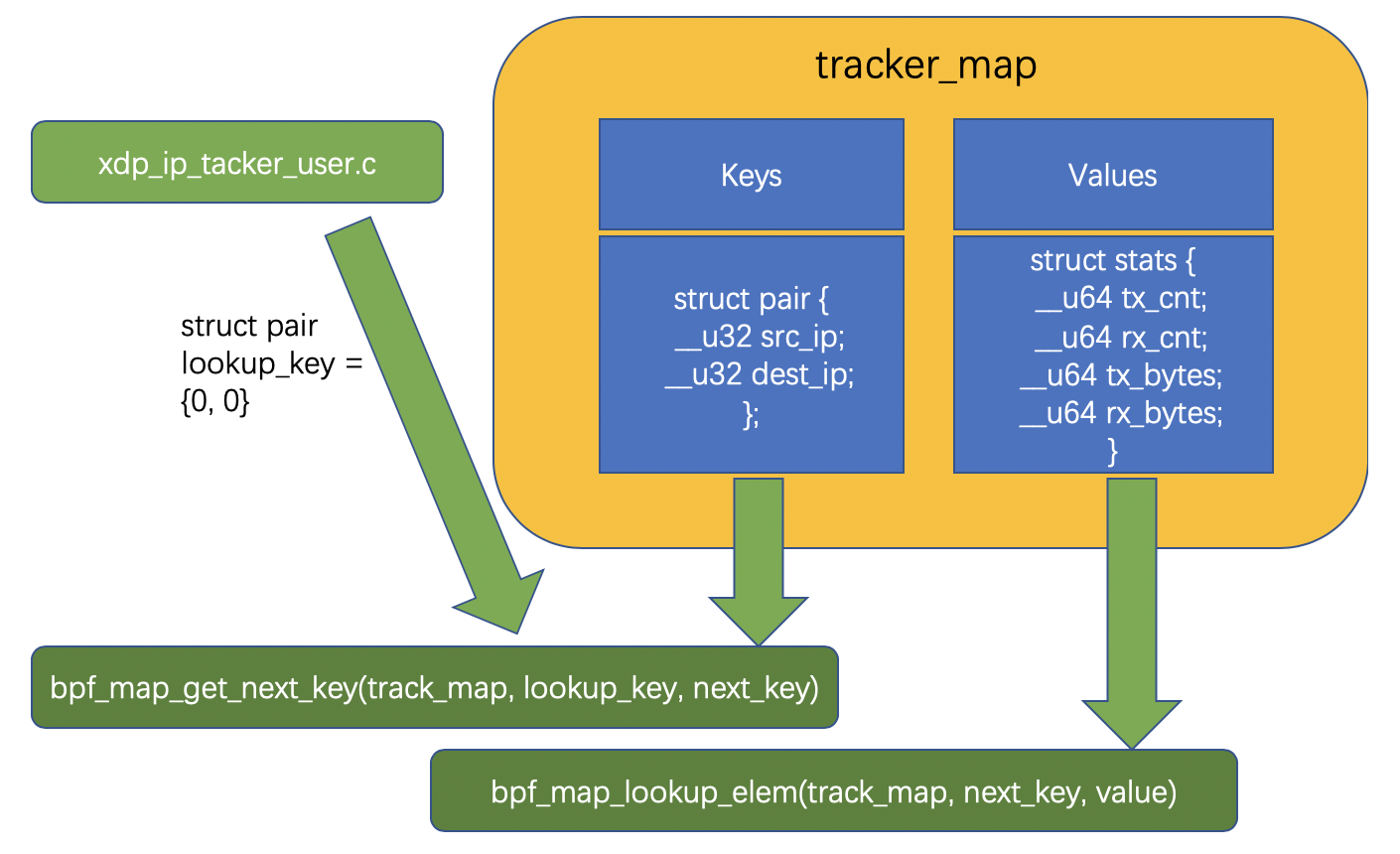
还有一段非常陌生的代码,如下所示:
|
|
- 这里有一个struct叫
rlimit,全称是resource limit,顾名思义,它是控制应用进程能使用资源的限额。 - 常量
RLIM_INFINITY看起来就是无限的意思,因此第一行代码就是定义了一个没有上限的资源配额。 - 第二行代码使用了函数
setrlimit(),传入的第一个参数是一个资源规格名称——RLIMIT_MEMLOCK,即内存;第二个参数是刚才定义的无限资源配额,可以猜出这行代码的意思就是为内存资源配置了无限配额,即没有内存上限。 - 为什么要把内存限制放开呢?因为操作系统在不同的CPU架构,对于应用进程能使用的内存限制是不统一的,而不同的BPF程序需要使用到的内存资源也是可变的,比如你的BPF Map申请了很大的
max_entries,那么这个BPF程序一定会使用不少的内存。因此为了成功运行BPF程序,就把对于内存的限制放开成无限了。
匿名 inode
在Unix/Linux的世界,一切皆是文件,BPF Map也不例外。从上文看到我们是可以通过文件描述符fd来访问BPF Map内的数据,因此BPF Map创建是遵循Linux文件创建的过程。实现BPF_MAP_CREATE系统调用命令的函数是map_create(),即创建BPF Map的核心函数:
|
|
其中bpf_map_new_fd()函数就是用来为BPF Map分配fd的,下面是其函数主体:
|
|
要说的是anon_inode_getfd()这个函数,它不是一般的分配 fd 的方式,是一种特殊的匿名方式,它的inode没有被绑定到磁盘上的某个文件,而是仅仅在内存里。一旦fd关闭后,对应的内存空间就会被释放,相关数据,即我们的 BPF Map也就被删除了。它的comment doc写得非常好,详细大家可以自行了解。
也可以通过lsof和cat /proc/[pid]/fd命令看到BPF Map作为 anon_inode 的效果(其实普通的BPF程序也是这个type):
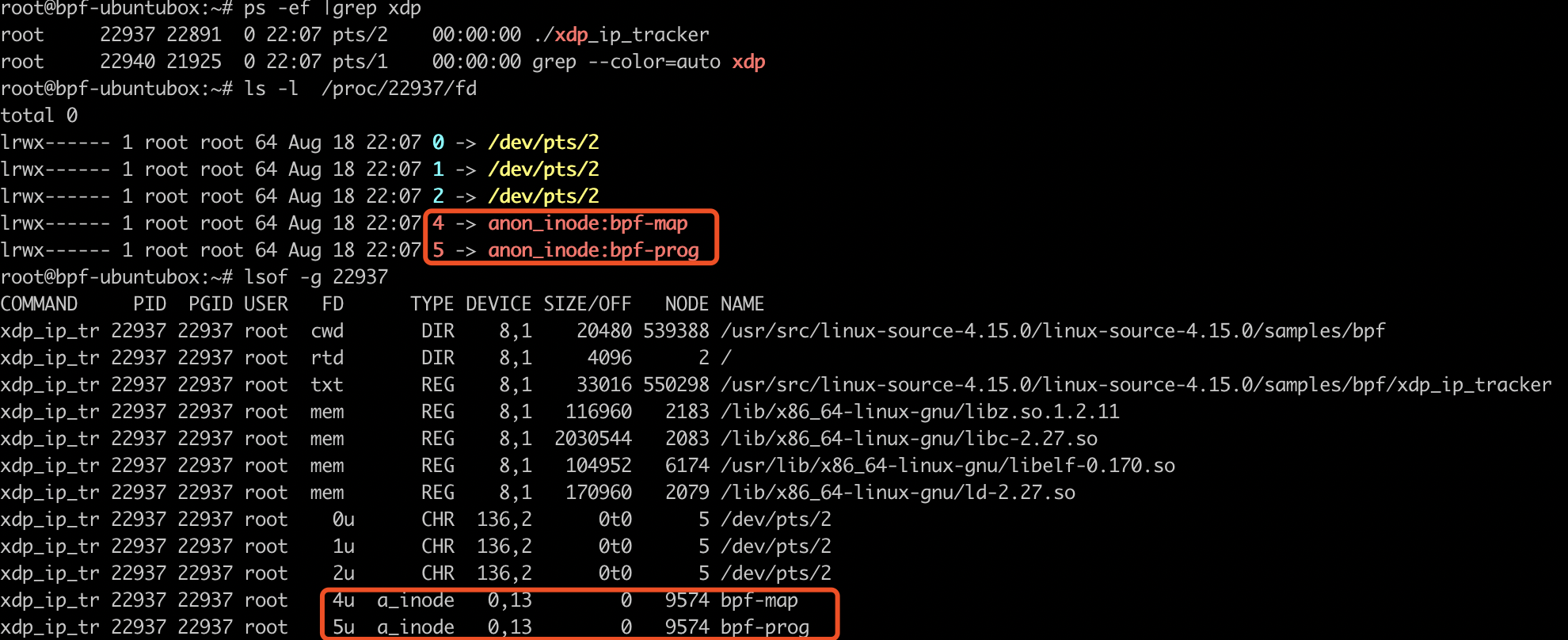
BPF Map 调试
如果想看当前操作系统上面是否有正在使用BPF Map,可以使用BPF社区大力推荐的命令行工具——BPFtool,它是专门用来查看BPF程序和BPF Map的命令行工具,并且可以对它们做一些简单操作。BPFtool源码 被维护在Linux内核代码里,因此一般都是通过make命令自行编译出可执行文件,操作起来并不麻烦,如下所示:
|
|
需要注意的是,不同内核版本下的BPFtool代码有所差异,其功能也不一样,一般来说高版本内核下的BPFtool功能更多,也是向下兼容的。我使用的就是在5.6.6内核版本下编译出来的BPFtool,并且在内核版本是4.15.0操作系统上运行顺畅。
接下来给大家简单演示如何使用bpftool查看BPF Map信息,主要用两个命令进行查看:
|
|
参考资料
- BPF数据传递的桥梁——BPF MAP
- Linux Kernel Patch, bpf: add hashtable type of eBPF maps, v3.19-rc1
- Linux Kernel Patch, bpf: add array type of eBPF maps, v3.19-rc1
- Linux Kernel Patch, bpf: allow bpf programs to tail-call other bpf programs, v4.2-rc1
- Linux Kernel Patch, bpf: Add new bpf map type to store the pointer to struct perf_event, v4.3-rc1
- Linux Kernel Patch, bpf: introduce BPF_MAP_TYPE_PERCPU_HASH map, v4.6-rc1
- Linux Kernel Patch, bpf: introduce BPF_MAP_TYPE_PERCPU_ARRAY map, v4.6-rc1
- Linux Kernel Patch, bpf: Add hash of maps support
- Use Map-in-Map in BPF programs via Libbpf
-
No backlinks found.