CSP GPU Share
GPU 共享与调度
| NVIDIA k8s-device-plugin | 阿里云 GPU Share | 腾讯云 GPU Manager | 华为云 Volcano | AWS | Azure | Google Cloud | |
|---|---|---|---|---|---|---|---|
| 驱动管理 | 支持 | 依赖nvidia-runtime | 支持 | 不支持 | |||
| 显存隔离 | 不支持 | 支持多个Pod共享GPU,支持隔离,依赖于cGPU | 支持 | 不支持 | |||
| 算力隔离 | 不支持 | 不支持,cGPU支持算力隔离,gpushare不提供算力隔离 | 支持 | 不支持 | |||
| 拓扑感知 | 支持 | 不支持 | 支持 | 支持 | |||
| 资源Quota | 不支持 | 不支持 | 支持 | 支持 | |||
显存与算力共享隔离
阿里云 GPUShare + cGPU
阿里云基于 cGPU 和 GPUShare 实现了GPU共享调度,只支持以 gpu-mem 的形式申请,并且不支持申请多个卡。
支持关闭GPU显存隔离
默认开启显存隔离,可以通过环境变量关闭显存隔离
|
|
腾讯云 GPU Manager
现在的 GPU Manager 方案,方案设计上包括3个部分:
- cuda封装库 vcuda:是一个对nvidia-ml和libcuda库的封装库,通过劫持容器内用户程序的cuda调用限制当前容器内进程对GPU和显存的使用
- k8s device plugin:实现了GPU拓扑感知、设备和驱动映射等功能。
- k8s scheduler extender:实现 gpu 配额 和 避免碎片化调度
方案优点
- 同时支持碎片和整卡调度,提高GPU资源利用率
- 支持同一张卡上容器间GPU和显存的使用隔离
- 基于拓扑感知,提供最优的调度策略
- 对用户程序无侵入,用户无感
方案缺点
- 驱动和加速库的兼容性依赖于厂商
- 存在约5%的性能损耗
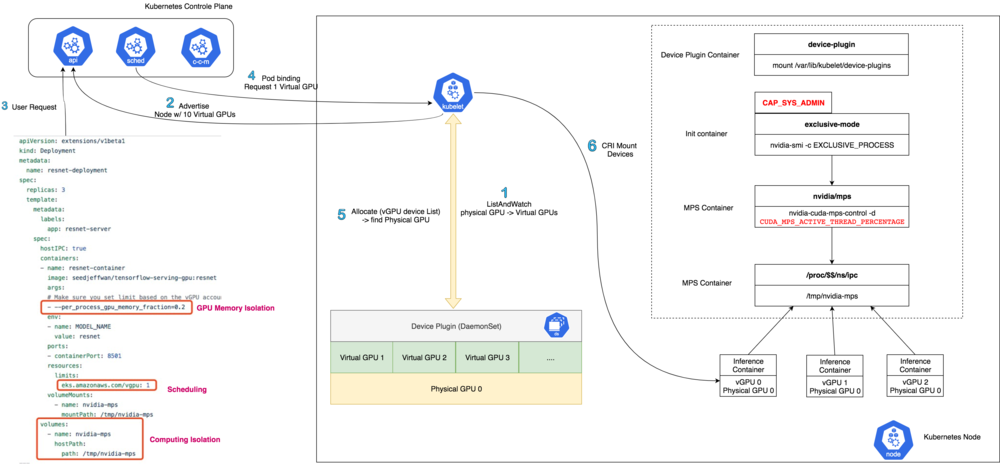
AWS 基于 MPS
AWS 支持 基于 MPS 构建的 GPU 共享插件,需要安装定制的GPU Device Plugin实现将GPU虚拟化多个卡:
GPU 拓扑感知
NVlink连接的单向通信带宽为25 GB/s,双向通信带宽为50 GB/s,PCle连接的通信带宽为16 GB/s。在训练过程中,选择不同的GPU组合,会得到不同的训练速度,所以在GPU的调度过程中,选择最优的GPU组合,可得到最优的训练速度。
下图为NVLink连接8个Tesla V100的混合立体网络拓扑。每块V100 GPU有6个NVLink通道,8块GPU间无法做到全连接,2块GPU间最多只能有2条NVLink连接。其中GPU0和GPU3,GPU0和GPU4之间有2条NVLink连接,GPU0和GPU1之间有一条NVLink连接,GPU0和6之间没有NVLink连接,故GPU0与GPU6之间仍然需要通过PCIe进行通信。
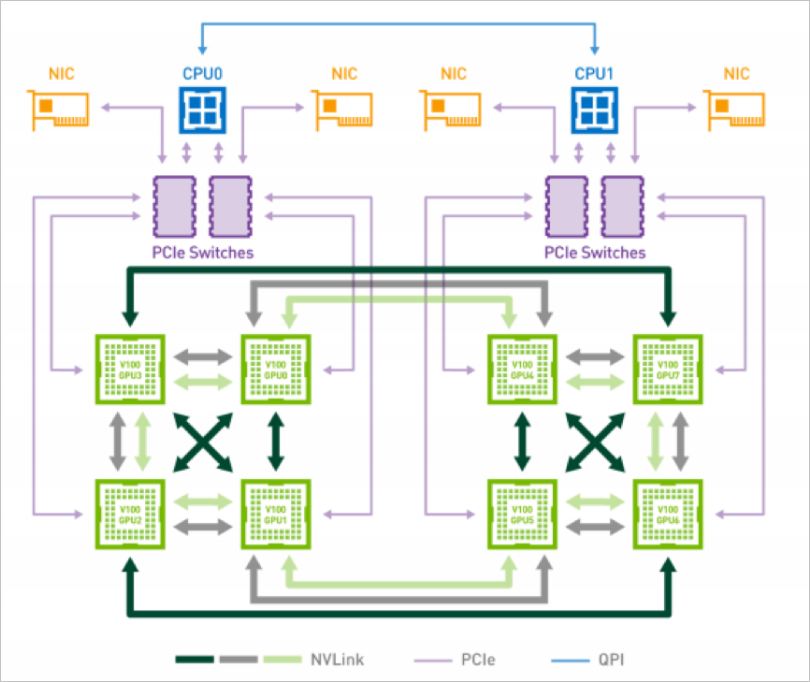
Kubernetes对节点的GPU拓扑信息不感知,调度过程中对GPU的选择比较随机,选择不同的GPU组合训练速度会存在较大的差异。
腾讯云 GPU Manager
gpu-manager-daemonset 会根据GPU拓扑结构生成GPU卡的拓扑树,选择最优的结构(距离最短的叶子节点)进行调度分配。
华为云 Volcano
阿里云 ack-ai-installer
阿里 对于以上问题,基于Scheduling Framework机制,实现GPU拓扑感知调度,在节点的GPU组合中选择具有最优训练速度的组合。
细粒度Quota准入
用户通过配置一个 ConfigMap,对每个 Namespace可用的GPU卡的配额做规划,同时也定义了资源池,这样在调度的时候就可以实现按照资源池及GPU型号进行策略调度。
|
|
具体在调度的时候,对每一个Pod,根据Namespace可以筛选出一系列含有GPU的Pods,然后当前Namespace下,对于某种GPU Model(比如P100),计算已经使用了的GPU大小,根据 ConfigMap 定义的配额,找到没超出。通过这个,得到所有没超出Quota的Models。
GPU 监控
指标监控
阿里云
阿里云容器团队 结合 Prometheus 和 Grafana 提供了 Pod 级别的 GPU 监控,通过一个 gpu-prometheus-exporter 可以提供 Node 和 Pod 级别的 GPU 监控。目前已经和他们托管的Prometheus结合起来,既可以监控独占的GPU,也可以监控共享的GPU,这里的共享GPU方案即是上文提到的cGPU和GPUShare,使用参考 产品文档 。
| 观测指标 | Metrics -> Label | Container | Pod | Namespace | Card | Node |
|---|---|---|---|---|---|---|
| GPU Memory 总的大小 | nvidia_gpu_memory_total_bytes | 支持,但是显示的是卡的显存总大小 | 支持,但是显示的是卡的显存总大小 | 支持,但是显示的是卡的显存总大小 | 支持 | 支持 |
| GPU Memory 使用的大小 | nvidia_gpu_memory_used_bytes | 支持 | 支持 | 支持 | 支持 | 支持 |
| GPU sharing Memory | nvidia_gpu_gpu_sharing_memory | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| GPU 占空比 | nvidia_gpu_duty_cycle | 支持,但卡上所有Container都一样 | 支持,但卡上所有Pod都一样 | 支持,但卡上所有Namespace都一样 | 支持 | 支持 |
| GPU 设备数目 | nvidia_gpu_num_devices | 无 | 无 | 无 | 无 | 支持 |
| GPU Power 使用 | nvidia_gpu_power_usage_milliwatts | 支持,但卡上所有Container都一样 | 支持,但卡上所有Pod都一样 | 支持,但卡上所有Namespace都一样 | 支持 | 支持 |
| GPU 温度 | nvidia_gpu_temperature_celsius | 支持,但卡上所有Container都一样 | 支持,但卡上所有Pod都一样 | 支持,但卡上所有Namespace都一样 | 支持 | 支持 |
不开启cGPU模式下的监控:
|
|
|
|
开启 cGPU 模式下的监控数据
|
|
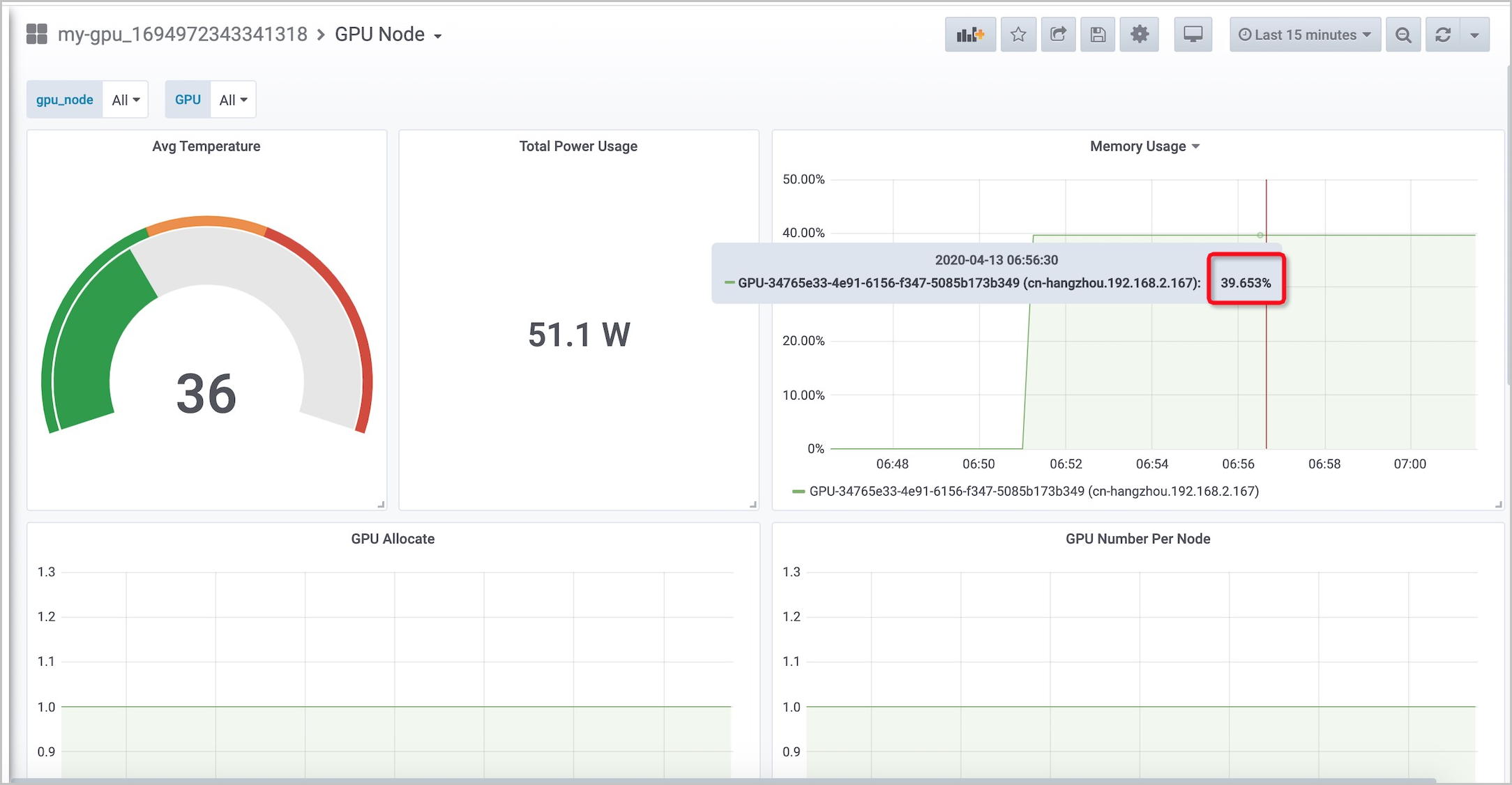
Node 级别 GPU 监控
面板指标:
- Avg Temperature
- Total Power Usage
- Memory Usage
- GPU Allocate
- GPU Number Per Node
- GPU Temperature
- Power Usage
- GPU Duty Cycle

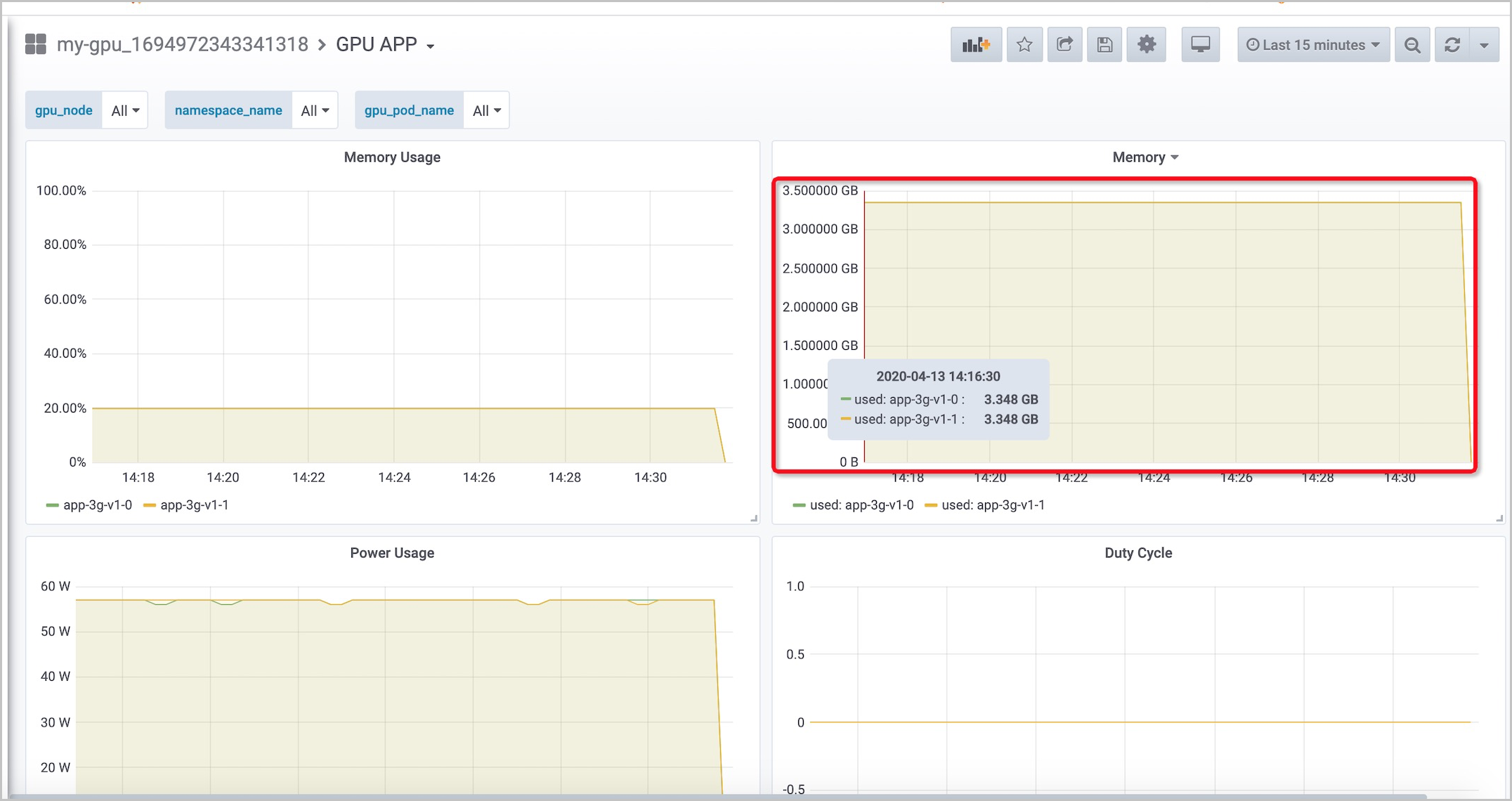
Pod 级别 GPU 监控
面板指标:
- Memory Usage
- Memory
- Power Usage
- Duty Cycle
- Temperature
阿里云的云监控团队,提供如下三个维度的GPU监控数据:GPU、实例、分组。
- GPU维度监控指标 GPU维度的监控指标采集每个GPU层面的监控数据,GPU维度的监控指标如下表所示:
| MetricName | 单位 | 名称 | dimensions |
|---|---|---|---|
| gpu_memory_freespace | Byte | GPU维度显存空闲量 | instanceId,gpuId |
| gpu_memory_totalspace | Byte | GPU维度显存总量 | instanceId,gpuId |
| gpu_memory_usedspace | Byte | GPU维度显存使用量 | instanceId,gpuId |
| gpu_gpu_usedutilization | % | GPU维度GPU使用率 | instanceId,gpuId |
| gpu_encoder_utilization | % | GPU维度编码器使用率 | instanceId,gpuId |
| gpu_decoder_utilization | % | GPU维度解码器使用率 | instanceId,gpuId |
| gpu_gpu_temperature | ℃ | GPU维度GPU温度 | instanceId,gpuId |
| gpu_power_readings_power_draw | W | GPU维度GPU功率 | instanceId,gpuId |
| gpu_memory_freeutilization | % | GPU维度显存空闲率 | instanceId,gpuId |
| gpu_memory_useutilization | % | GPU维度显存使用率 | instanceId,gpuId |
- 实例维度监控指标 实例维度监控指标对单个ECS实例上的多个GPU监控数据做最大值、最小值、平均值的聚合,便于查询实例层面的整体使用情况。
| MetricName | 单位 | 名称 | dimensions |
|---|---|---|---|
| instance_gpu_decoder_utilization | % | 实例维度GPU解码器使用率 | instanceId |
| instance_gpu_encoder_utilization | % | 实例维度GPU编码器使用率 | instanceId |
| instance_gpu_gpu_temperature | ℃ | 实例维度GPU温度 | instanceId |
| instance_gpu_gpu_usedutilization | % | 实例维度GPU使用率 | instanceId |
| instance_gpu_memory_freespace | Byte | 实例维度GPU显存空闲量 | instanceId |
| instance_gpu_memory_freeutilization | % | 实例维度GPU显存空闲率 | instanceId |
| instance_gpu_memory_totalspace | Byte | 实例维度GPU显存总量 | instanceId |
| instance_gpu_memory_usedspace | Byte | 实例维度GPU显存使用量 | instanceId |
| instance_gpu_memory_usedutilization | % | 实例维度GPU显存使用率 | instanceId |
| instance_gpu_power_readings_power_draw | W | 实例维度GPU功率 | instanceId |
- 分组维度监控指标 分组维度监控指标对单个应用分组里的多个ECS 实例的监控数据做最大值、最小值、平均值的聚合,便于查询集群层面的整体使用情况。
| MetricName | 单位 | 名称 | dimensions |
|---|---|---|---|
| group_gpu_decoder_utilization | % | 分组维度GPU解码器使用率 | groupId |
| group_gpu_encoder_utilization | % | 分组维度GPU编码器使用率 | groupId |
| group_gpu_gpu_temperature | ℃ | 分组维度GPU温度 | groupId |
| group_gpu_gpu_usedutilization | % | 分组维度GPU使用率 | groupId |
| group_gpu_memory_freespace | Byte | 分组维度GPU显存空闲量 | groupId |
| group_gpu_memory_freeutilization | % | 分组维度GPU显存空闲率 | groupId |
| group_gpu_memory_totalspace | Byte | 分组维度GPU显存总量 | groupId |
| group_gpu_memory_usedspace | Byte | 分组维度GPU显存使用量 | groupId |
| group_gpu_memory_usedutilization | % | 分组维度GPU显存使用率 | groupId |
| group_gpu_power_readings_power_draw | W | 分组维度GPU功率 | groupId |

腾讯云
TKE 监控体系如下,采用三级prometheus联邦架构,分别为:user prometheus、region promethues,top prometheus。
- user prometheus:user prometheus采集单个region下,每个集群的node、api server, etcd等组件的metrics。
- region promethues:region prometheus拉取各个cluster prometheus中的数据,聚合region级别的组件监控数据,同时可以监控cluster prometheus存活情况。为了监控所有支持环境的dashboard,nigthwatch等组件,为支持环境单独搭建一套支撑prometheus,完成对dashboard,nigthwatch等组件存活,以及metrics采集和聚合。
- top prometheus:top prometheus是最顶层prometheus,拉取region prometheus和支撑prometheus的metrics数据,完成跨region的聚合。同时也可以监控这2类prometheus的存活情况。

TKE monitor pod包括5个container,主要包括:
- prometheus: 主要采集tke相关的metrics。我们称之为user prometheus。
- barad importer: 主要从barad系统拉取node相关的metrics。
- argus-adapter: 一个prometheus remote writer,主要将metrics写入argus存储。
- kube-state-metrics:采集workload相关metrics。
- barad-adapter: 一个prometheus remote write, 将部分指标写入barad nws。

备注:
- Argus 是腾讯云内部的监控系统
- Barad 是腾讯云CVM的监控组件,每个CVM上都会安装Barad Agent,以获取Node的监控数据
腾讯云 Pod 级别 GPU 监控数据来自于 GPU Manager
GPU Manager 提供的 Metrics 如下:
|
|
其计算方法如下:
- 基于 NVML 库 的
nvmlDeviceGetComputeRunningProcesses和nvmlDeviceGetProcessUtilization两个API获得Device上的使用率
|
|
- 获得Container里面的Pids号,查找设备上属于此Container的PID进程,将其
smUtil和usedGpuMemory按进程加总
| Container级别 | Pod 级别 | Node 级别 | Cluster 级别 | Workload/Namespace级别 |
|---|---|---|---|---|
| k8s_container_gpu_used 按 Namespace 和 PodName 聚合容器GPU使用量 | k8s_pod_gpu_used Pod 实际使用的GPU | kube_node_status_capacity_gpu 节点上所有卡可用vcore的聚合 | k8s_cluster_gpu_total 所有Node的聚合 | k8s_workload_gpu_memory_used_bytes 按workload聚合算workload的GPU使用量 |
| k8s_container_rate_gpu_used_request 容器实际使用GPU与申请的GPU的比例 | k8s_pod_gpu_request Pod 申请的GPU | kube_node_status_capacity_gpu_memory_bytes 节点上所有卡可用memory的聚合 | k8s_cluster_gpu_memory_total_bytes | k8s_workload_rate_gpu_memory_used_cluster workload 使用的GPU Memory占集群的GPU的比例 |
| k8s_container_rate_gpu_used_node 容器实际使用的GPU 与 Node 上 GPU 的比例 | k8s_pod_rate_gpu_used_request Pod 实际使用的GPU与申请的GPU的比例 | kube_node_status_allocatable_gpu | k8s_cluster_gpu_used 集群使用的GPU | k8s_workload_gpu_used 按workload聚合算workload的GPU使用量 |
| k8s_container_gpu_memory_used_bytes 按 Namespace 和 PodName 聚合容器GPU memory 使用量 | k8s_pod_rate_gpu_used_node Pod 实际使用的GPU 占 Node GPU 的比例 | kube_node_status_allocatable_gpu_memory_bytes | k8s_cluster_rate_gpu_used_cluster 集群实际使用的GPU占集群总的GPU比例 | k8s_workload_rate_gpu_used_cluster workload 使用的GPU占集群的GPU的比例 |
| k8s_container_rate_gpu_memory_used_request 容器实际使用GPU Memory 与申请的GPU的比例 | k8s_pod_gpu_memory_used_bytes 实际使用的GPU Memory | k8s_node_gpu_used Node 上使用的GPU使用量 | k8s_cluster_rate_gpu_request_cluster 集群申请的GPU占集群总的GPU比例 | k8s_namespace_gpu_used |
| k8s_container_rate_gpu_memory_used_node 容器实际使用的GPU Memory 与 Node 上 GPU Memory 的比例 | k8s_pod_rate_gpu_memory_used_request 实际使用的GPU Memory 与申请的GPU Memory比例 | k8s_node_gpu_memory_used_bytes Node 上使用的GPU Memory | k8s_cluster_gpu_memory_used_bytes 集群使用的GPU Memory | k8s_namespace_rate_gpu_used_cluster |
| k8s_pod_rate_gpu_memory_used_node Pod 实际使用的GPU Memory 占 Node GPU Memory的比例 | k8s_node_rate_gpu_used Node 上使用的GPU使用量占Node上GPU 容量的比例 | k8s_cluster_rate_gpu_memory_used_cluster 集群使用的GPU Memory占总的GPU比例 | k8s_namespace_gpu_memory_used_bytes | |
| k8s_pod_rate_gpu_memory_used_node Pod 实际使用的GPU Memory占 Node GPU Memory的比例 | k8s_node_rate_gpu_memory_used Node 上使用的GPU Memory 占Node上GPU Memory容量的比例 | k8s_cluster_rate_gpu_memory_request_cluster 集群申请的GPU Memory占集群总的GPU比例 | k8s_namespace_rate_gpu_memory_used_cluster |


|
|
AWS
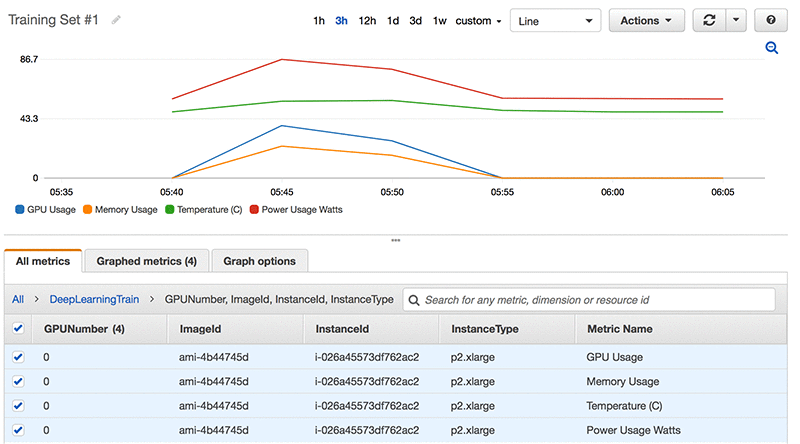
AWS 通过 Cloud Watch 支持监控 【卡级别】 每个 GPU 使用率:GPU 内存、GPU 温度和 GPU 功率,这需要安装 gpumon.py 在 Node上
Azure
根据 Azure 文档,Azure Monitor 监控指标包括:
| 指标名称 | 指标维度(标记) | 说明 |
|---|---|---|
| containerGpuDutyCycle | container.azm.ms/clusterId、container.azm.ms/clusterName、containerName、gpuId、gpuModel、gpuVendor | 在刚过去的采样周期(60 秒)中,GPU 处于繁忙/积极处理容器的状态的时间百分比。 占空比是 1 到 100 之间的数字。 |
| containerGpuLimits | container.azm.ms/clusterId、container.azm.ms/clusterName、containerName | 每个容器可以将限值指定为一个或多个 GPU。 不能请求或限制为 GPU 的一部分。 |
| containerGpuRequests | container.azm.ms/clusterId、container.azm.ms/clusterName、containerName | 每个容器可以请求一个或多个 GPU。 不能请求或限制为 GPU 的一部分。 |
| containerGpumemoryTotalBytes | container.azm.ms/clusterId、container.azm.ms/clusterName、containerName、gpuId、gpuModel、gpuVendor | 可用于特定容器的 GPU 内存量(以字节为单位)。 |
| containerGpumemoryUsedBytes | container.azm.ms/clusterId、container.azm.ms/clusterName、containerName、gpuId、gpuModel、gpuVendor | 特定容器使用的 GPU 内存量(以字节为单位)。 |
| nodeGpuAllocatable | container.azm.ms/clusterId、container.azm.ms/clusterName、gpuVendor | 节点中可供 Kubernetes 使用的 GPU 数。 |
| nodeGpuCapacity | container.azm.ms/clusterId、container.azm.ms/clusterName、gpuVendor | 节点中的 GPU 总数。 |
可以看到 Azure 不支持 GPU 在多个Pod共享,尽管支持Container级别的GPU监控指标,也是按照卡级别的汇总。
Google 通过 Cloud Monitoring 可以监控 Node 上的 GPU 使用数据,主要是 gpu_utilization 。
在 GKE 产品 中,可以监控的指标包括
- 占空比 (
container/accelerator/duty_cycle):加速器活跃处理的时间占过去的采样周期(10 秒)的百分比。介于 1 到 100 之间。 - 内存用量 (
container/accelerator/memory_used):已分配的加速器内存量(以字节为单位)。 - 内存容量 (
container/accelerator/memory_total):加速器内存总量(以字节为单位)。
Google 的 GPU 监控同样不支持多个 Pod 共享,尽管支持Container级别的GPU监控指标,也是按照卡级别的汇总。
异常监控
阿里云提供了通过Kubernetes 事件中心对 GPU Xid 错误进行监控告警。
Xid消息是来自NVIDIA驱动程序的错误报告,该报告会打印到操作系统的内核日志或事件日志中。Xid消息表明发生了一般的GPU错误,通常是由于驱动程序对GPU的编程不正确或发送给GPU的命令损坏所致。这些消息可能表示硬件问题、NVIDIA软件问题或用户应用程序问题。
GPU设备在使用中,容易发生一些Xid错误,可以配合Kubernetes事件中心,对这些Xid错误进行监控告警,及时发现并定位故障原因。
弹性伸缩
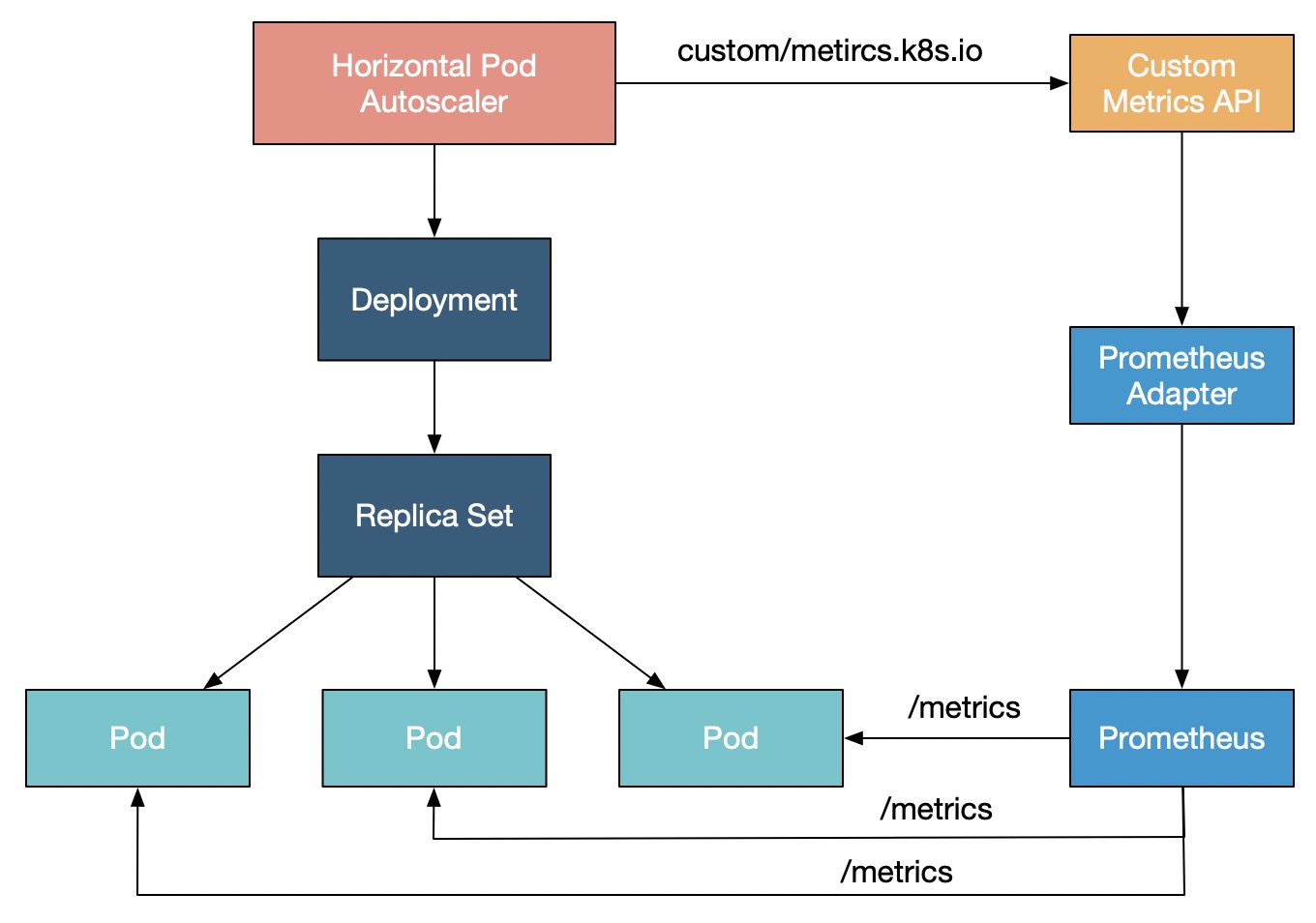
在高性能计算领域,比如深度学习模型训练、推理等场景,通常需要使用GPU来做计算加速。为了节省成本,您往往需要根据GPU指标(利用率、显存)来做弹性伸缩。虽然默认的HPA(Horizontal Pod Autoscaler)组件并不支持根据GPU指标实现弹性伸缩,但Kubernetes提供的External Metrics机制可以通过GPU指标实现容器弹性伸缩。
参考资料
-
No backlinks found.