BGP 协议
边界网关协议 BGP(Border Gateway Protocol)是一种实现自治系统 AS(Autonomous System)之间的路由可达,并选择最佳路由的距离矢量路由协议。
引入 BGP 背景
为方便管理规模不断扩大的网络,网络被分成了不同的自治系统。1982 年,外部网关协议 EGP(Exterior Gateway Protocol)被用于实现在 AS 之间动态交换路由信息。但是 EGP 设计得比较简单,只发布网络可达的路由信息,而不对路由信息进行优选,同时也没有考虑环路避免等问题,很快就无法满足网络管理的要求。BGP 是为取代最初的 EGP 而设计的另一种外部网关协议。不同于最初的 EGP,BGP 能够进行路由优选、避免路由环路、更高效率的传递路由和维护大量的路由信息。
虽然 BGP 用于在 AS 之间传递路由信息,但并不是所有 AS 之间传递路由信息都需要运行 BGP。比如在数据中心上行的连入 Internet 的出口上,为了避免 Internet 海量路由对数据中心内部网络的影响,设备采用静态路由代替 BGP 与外部网络通信。
路由协议
大部分路由协议都可以归为两类分布式路由算法:
- 链路-状态(link-state):交换邻居的链路状态信息,比距离矢量算法复杂
- 距离矢量(distance vector):交换路由表信息
链路状态算法
路由可扩展性和收敛速度都有改善,可以支持更大的网络,但仍然只适用于域内路由( interior routing)。
大部分大型服务供应商在域内(intra-domain)都使用 link-state 协议,主要是看中它的 快速收敛特性。
距离矢量算法
为每条路由维护一个距离矢量(vector of distances),其中“距离”用跳数(hops)或类似指标衡量。
每个节点独立计算最短路径,因此是分布式算法。
每个节点向邻居通告自己已知的最短路径,邻居根据收到的消息判断是否有更短路径,如果有就更新自己的路由信息,然后再次对外通告最短路径。如此反复,直到整个网络收敛到一 致状态。
BGP 优势
BGP 从多方面保证了网络的安全性、灵活性、稳定性、可靠性和高效性。
- BGP 采用认证和 GTSM 的方式,保证了网络的安全性。
- BGP 提供了丰富的路由策略,能够灵活的进行路由选路,并且能指导邻居按策略发布路由。
- BGP 提供了路由聚合和路由衰减功能由于防止路由震荡,有效提高了网络的稳定性。
- BGP 使用 TCP 作为其传输层协议(目的端口号 179),并支持与 BGP 与 BFD 联动、BGP Tracking 和 BGP GR 和 NSR,提高了网络的可靠性。
- 在邻居数目多、路由量大且大部分邻居具有相同出口的策略的场景下,BGP 使用按组打包技术极大的提高了 BGP 打包发包性能。
BGP 基本概念
自治系统
将路由域划分为独立的管理单元,称为自治系统(autonomous systems,AS)。 每个 AS 有自己独立的路由策略和 IGP。AS 是指在一个实体管辖下的拥有相同选路策略的 IP 网络。
- BGP 网络中的每个 AS 都被分配一个唯一的 AS 号,用于区分不同的 AS。
- AS 号分为 2 字节 AS 号和 4 字节 AS 号,其中 2 字节 AS 号的范围为 1 至 65535,4 字节 AS 号的范围为 1 至 4294967295。
- 支持 4 字节 AS 号的设备能够与支持 2 字节 AS 号的设备兼容。
BGP 分类
BGP 按照运行方式分为 EBGP(External/Exterior BGP)和 IBGP(Internal/Interior BGP)。
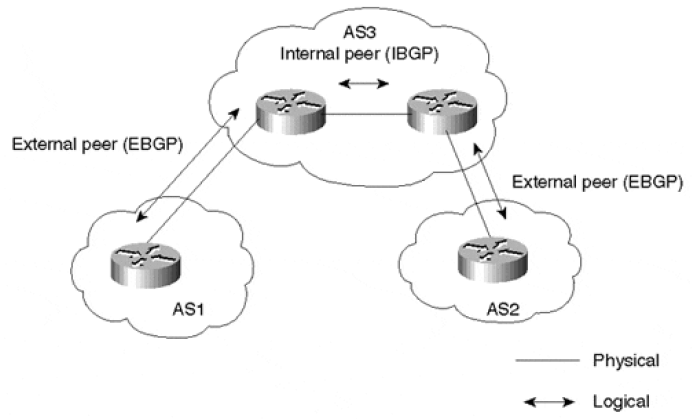
- EBGP:运行于不同 AS 之间的 BGP 称为 EBGP。为了防止 AS 间产生环路,当 BGP 设备接收 EBGP 对等体发送的路由时,会将带有本地 AS 号的路由丢弃。
- IBGP:运行于同一 AS 内部的 BGP 称为 IBGP。为了防止 AS 内产生环路,BGP 设备不将从 IBGP 对等体学到的路由通告给其他 IBGP 对等体,并与所有 IBGP 对等体建立全连接。为了解决 IBGP 对等体的连接数量太多的问题,BGP 设计了路由反射器和 BGP 联盟。
BGP 角色
BGP 报文交互中分为 Speaker 和 Peer 两种角色。
- Speaker:发送 BGP 报文的设备称为 BGP 发言者(Speaker),它接收或产生新的报文信息,并发布(Advertise)给其它 BGP Speaker。
- Peer:相互交换报文的 Speaker 之间互称对等体(Peer)。若干相关的对等体可以构成对等体组(Peer Group)。
BGP 的 Router ID
BGP 的 Router ID 是一个用于标识 BGP 设备的 32 位值,通常是 IPv4 地址的形式,在 BGP 会话建立时发送的 Open 报文中携带。对等体之间建立 BGP 会话时,每个 BGP 设备都必须有唯一的 Router ID,否则对等体之间不能建立 BGP 连接。
BGP 的 Router ID 在 BGP 网络中必须是唯一的,可以采用手工配置,也可以让设备自动选取。缺省情况下,BGP 选择设备上的 Loopback 接口的 IPv4 地址作为 BGP 的 Router ID。如果设备上没有配置 Loopback 接口,系统会选择接口中最大的 IPv4 地址作为 BGP 的 Router ID。一旦选出 Router ID,除非发生接口地址删除等事件,否则即使配置了更大的地址,也保持原来的 Router ID。
BGP 工作原理
BGP 是一种路径矢量协议(path vector protocol),Path vector 是一条路由(network prefix)经过的所有 AS 组成的路径。目的是防止出现路由环路。
- BGP 使用 TCP 协议,运行在 179 端口。
- peer 之间建立连接之后交换全部路由,之后只交换更新的路由(增量更新)
- 交换路由是 UPDATE 消息
- 维护路由表的版本号,每次路由表有更新,版本号都会递增
- 通过 UPDATE 消息通告和撤回路由
BGP 的报文
BGP 对等体间通过以下 5 种报文进行交互,其中 Keepalive 报文为周期性发送,其余报文为触发式发送:
- Open:用于建立 BGP 对等体连接。
- Update:用于在对等体之间交换路由信息。
- Notification:用于中断 BGP 连接。
- Keepalive:用于保持 BGP 连接。
- Route-refresh:用于在改变路由策略后请求对等体重新发送路由信息。只有支持路由刷新(Route-refresh)能力的 BGP 设备会发送和响应此报文。
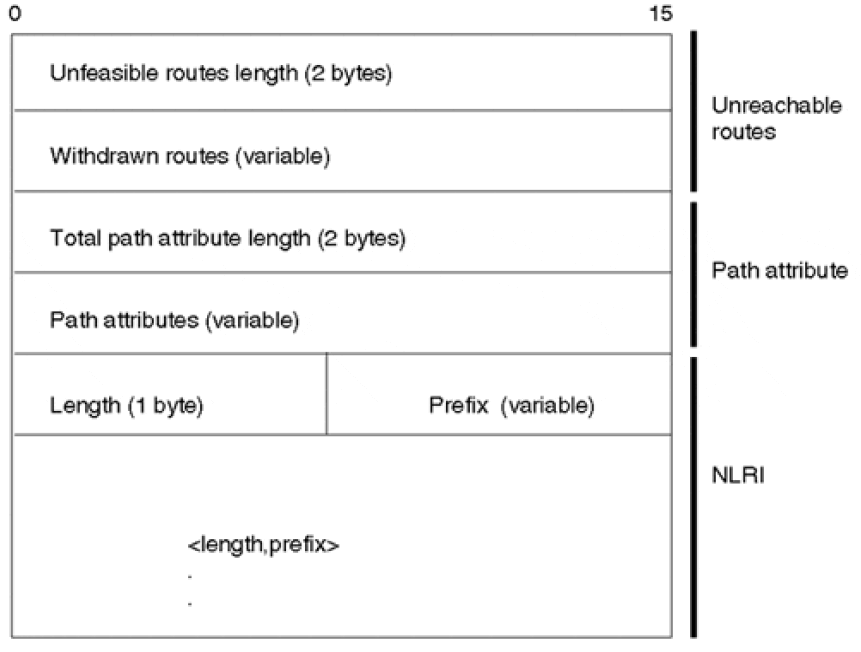
UPDATE 消息:
- Network Layer Reachability Information (NLRI):网络层可达信息
- Path Attributes
- Unfeasible Routes
BGP 状态机
BGP 对等体的交互过程中存在以下 6 种状态,其中最常见的 3 个状态是:Idle、Active 和 Established。
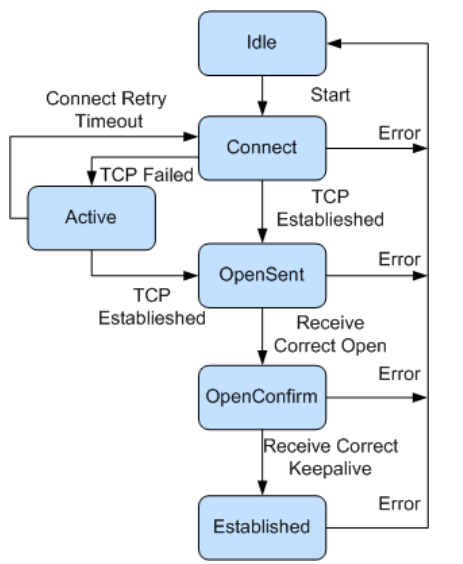
- Idle 状态是 BGP 初始状态。在 Idle 状态下,BGP 拒绝邻居发送的连接请求。只有在收到本设备的 Start 事件后,BGP 才开始尝试和其它 BGP 对等体进行 TCP 连接,并转至 Connect 状态。
- 在 Connect 状态下,BGP 启动连接重传定时器(Connect Retry),等待 TCP 完成连接。
- 如果 TCP 连接成功,那么 BGP 向对等体发送 Open 报文,并转至 OpenSent 状态。
- 如果 TCP 连接失败,那么 BGP 转至 Active 状态。
- 如果连接重传定时器超时,BGP 仍没有收到 BGP 对等体的响应,那么 BGP 继续尝试和其它 BGP 对等体进行 TCP 连接,停留在 Connect 状态。
- 在 Active 状态下,BGP 总是在试图建立 TCP 连接。
- 如果 TCP 连接成功,那么 BGP 向对等体发送 Open 报文,关闭连接重传定时器,并转至 OpenSent 状态。
- 如果 TCP 连接失败,那么 BGP 停留在 Active 状态。
- 如果连接重传定时器超时,BGP 仍没有收到 BGP 对等体的响应,那么 BGP 转至 Connect 状态。
- 在 OpenSent 状态下,BGP 等待对等体的 Open 报文,并对收到的 Open 报文中的 AS 号、版本号、认证码等进行检查。
- 如果收到的 Open 报文正确,那么 BGP 发送 Keepalive 报文,并转至 OpenConfirm 状态。
- 如果发现收到的 Open 报文有错误,那么 BGP 发送 Notification 报文给对等体,并转至 Idle 状态。
- 在 OpenConfirm 状态下,BGP 等待 Keepalive 或 Notification 报文。如果收到 Keepalive 报文,则转至 Established 状态,如果收到 Notification 报文,则转至 Idle 状态。
- 在 Established 状态下,BGP 可以和对等体交换 Update、Keepalive、Route-refresh 报文和 Notification 报文。
- 如果收到正确的 Update 或 Keepalive 报文,那么 BGP 就认为对端处于正常运行状态,将保持 BGP 连接。
- 如果收到错误的 Update 或 Keepalive 报文,那么 BGP 发送 Notification 报文通知对端,并转至 Idle 状态。
- Route-refresh 报文不会改变 BGP 状态。
- 如果收到 Notification 报文,那么 BGP 转至 Idle 状态。
- 如果收到 TCP 拆链通知,那么 BGP 断开连接,转至 Idle 状态。
BGP 对等体之间的交互原则
BGP 设备将最优路由加入 BGP 路由表,形成 BGP 路由。BGP 设备与对等体建立邻居关系后,采取以下交互原则:
- 从 IBGP 对等体获得的 BGP 路由,BGP 设备只发布给它的 EBGP 对等体。
- 从 EBGP 对等体获得的 BGP 路由,BGP 设备发布给它所有 EBGP 和 IBGP 对等体。
- 当存在多条到达同一目的地址的有效路由时,BGP 设备只将最优路由发布给对等体。
- 路由更新时,BGP 设备只发送更新的 BGP 路由。
- 所有对等体发送的路由,BGP 设备都会接收。
BGP 路由过程
BGP 是一种相当简单的协议,这也是它灵活的原因。BGP peer 之间通过 UPDATE 消息交换 路由。BGP 路由器收到 UPDATE 消息后,运行一些策略或者对消息进行过滤,然后将路由转发给其他 BGP peers。
BGP 实现需要维护一张 BGP 路由表,这张表是和 IP 路由表独立的。如果到同一目的地有多条路由,BGP 并不会将所有这些路由都转发给 peer;而是选出最优路由,然后将最优路由转发给 peer。除了传递从 peer 来的 eBGP 路由,或从路由反射器客户端(RR client) 来的 iBGP 路由之外,BGP 路由器还可以主动发起路由更新,通告它所在 AS 内的内部网络。
来源是本 AS 的合法的本地路由,以及从 BGP peer 学习到的最优路由,会被添加到 IP 路由表。IP 路由表是最终的路由决策表,用于操控转发表。
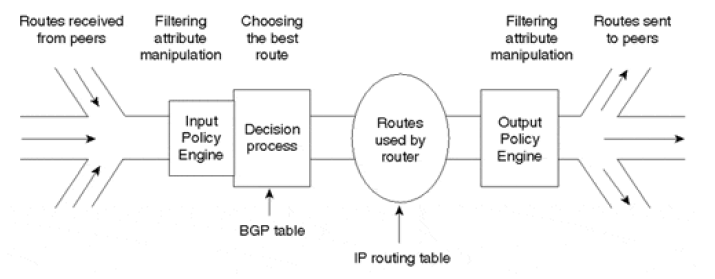
一个 BGP 路由器可以从多个邻居接收 NLR I 更新信息,并且将(自己拥有的)NLRI 信息通告给自己的邻居们(与收到 NLRI 更新消息的邻居可以不一致)。针对每一个邻居,BGP 要维护 的 RIB (Routing Information Base) 包括三部分:
- Adj-RIBs-In:存储了从对等体学习到的路由理新中未经处理的路由信息,这些包含在 Adj-RIBs-In 中的路由被认为是可行路由。
- Loc-RIB:本地路由信息库,注意与路由器的主路由表的区别。包含了 BGP Speaker 对 Adj-RIBs-In 中的路由应用本地策略之后选定的路由
- Adj-RIBs-Out:本地 BGP Speaker 即将要发出去的 RIB 信息,表示经过选择要告知邻居的路由信息
BGP 路由决策通过对 Adj-RIBs-In 中的路由应用本地路由策略,且向 Loc-RIB 和 Adj-RIBs-Out 中输入选定或修改的路由进行路由选择。其有三个阶段。
- 第一阶段:计算每条可行路由的优先级
- 第二阶段:从所有可用路由中为特定目的地选出最佳路由,并将其安装到 Loc-RIB 中。
- 第三阶段:将相应的路由加入到 Adj-RIBs-Out 中,以便向对等体进行宣告。
根据 RFC 1771,BGP 协议中路由(route)的定义是:一条路由是一个目标及其到达这个目标的一条路径的属性组成的信息单元(a route is defined as a unit of information that pairs a destination with the attributes of a path to that destination)。
路由在 BGP peer 之间通过 UPDATE 消息进行通告:目标是 NLRI 字段,路径是 path 属性字段。
路由存储在 RIB(Routing Information Bases)。
BGP speaker 选择通告一条路由的时候,可能会修改路由的 path 属性。
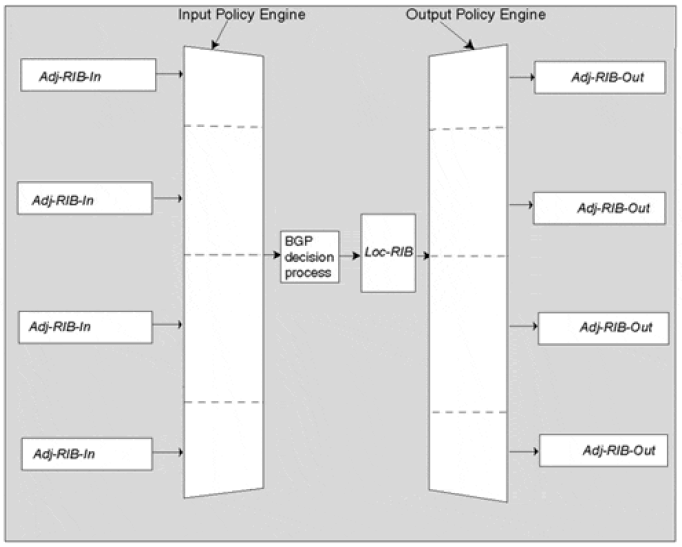
- 一个 Adj-RIB-In 逻辑上对应一个 peer,存储从 peer 学习到的路由
- Loc-RIB 存储最优路由
- 一个 Adj-RIB-Out 逻辑上对应一个 peer,存储准备从这个路由器发送给对应 peer 的路由
这里的逻辑图是将过程分成了三部分,每部分都有自己的存储,但实现不一定这样,事实上大部分实现都是共享一份路由表,以节省内存。
BGP 的路由选择
在 BGP 路由表中,到达同一目的地可能存在多条路由。此时 BGP 会选择其中一条路由作为最佳路由,并只把此路由发送给其对等体。BGP 为了选出最佳路由,会根据 BGP 的路由优选规则依次比较这些路由的 BGP 属性。
BGP 属性
路由属性是对路由的特定描述,所有的 BGP 路由属性都可以分为以下 4 类,常见 BGP 属性类型所示:
- 公认必须遵循(Well-known mandatory):所有 BGP 设备都可以识别此类属性,且必须存在于 Update 报文中。如果缺少这类属性,路由信息就会出错。
- 公认任意(Well-known discretionary):所有 BGP 设备都可以识别此类属性,但不要求必须存在于 Update 报文中,即就算缺少这类属性,路由信息也不会出错。
- 可选过渡(Optional transitive):BGP 设备可以不识别此类属性,如果 BGP 设备不识别此类属性,但它仍然会接收这类属性,并通告给其他对等体。
- 可选非过渡(Optional non-transitive):BGP 设备可以不识别此类属性,如果 BGP 设备不识别此类属性,则会被忽略该属性,且不会通告给其他对等体。
BGP 常见属性类型:
| 属性名 | 类型 |
|---|---|
| Origin 属性 | 公认必须遵循 |
| AS_Path 属性 | 公认必须遵循 |
| Next_Hop 属性 | 公认必须遵循 |
| Local_Pref 属性 | 公认任意 |
| MED 属性 | 可选非过渡 |
| Community 属性 | 可选过渡 |
| Originator_ID 属性 | 可选非过渡 |
| Cluster_List 属性 | 可选非过渡 |
Origin
Origin 属性用来定义路径信息的来源,标记一条路由是怎么成为 BGP 路由的。它有以下 3 种类型:
- 0:
IGP,具有最高的优先级。通过network命令注入到 BGP 路由表的路由,其 Origin 属性为 IGP。 - 1:
EGP,优先级次之。通过 EGP 得到的路由信息,其 Origin 属性为 EGP。 - 2:
Incomplete,优先级最低。通过其他方式学习到的路由信息。比如 BGP 通过import-route命令引入的路由,其 Origin 属性为 Incomplete。
AS_PATH
AS_PATH 属性按矢量顺序记录了某条路由从本地到目的地址所要经过的所有 AS 编号。在接收路由时,设备如果发现 AS_Path 列表中有本 AS 号,则不接收该路由,从而避免了 AS 间的路由环路。
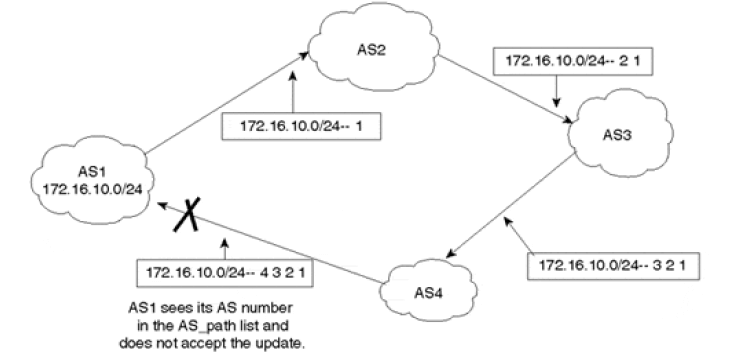
当 BGP Speaker 传播自身引入的路由时:
- 当 BGP Speaker 将这条路由通告到 EBGP 对等体时,便会在 Update 报文中创建一个携带本地 AS 号的 AS_PATH 列表。
- 当 BGP Speaker 将这条路由通告给 IBGP 对等体时,便会在 Update 报文中创建一个空的 AS_PATH 列表。
当 BGP Speaker 传播从其他 BGP Speaker 的 Update 报文中学习到的路由时:
- 当 BGP Speaker 将这条路由通告给 EBGP 对等体时,便会把本地 AS 编号添加在 AS_Path 列表的最前面(最左面)。收到此路由的 BGP 设备根据 AS_Path 属性就可以知道去目的地址所要经过的 AS。离本地 AS 最近的相邻 AS 号排在前面,其他 AS 号按顺序依次排列。
- 当 BGP Speaker 将这条路由通告给 IBGP 对等体时,不会改变这条路由相关的 AS_Path 属性。
Next_Hop
Next_Hop 属性记录了路由的下一跳信息。BGP 的下一跳属性和 IGP 的有所不同,不一定就是邻居设备的 IP 地址。
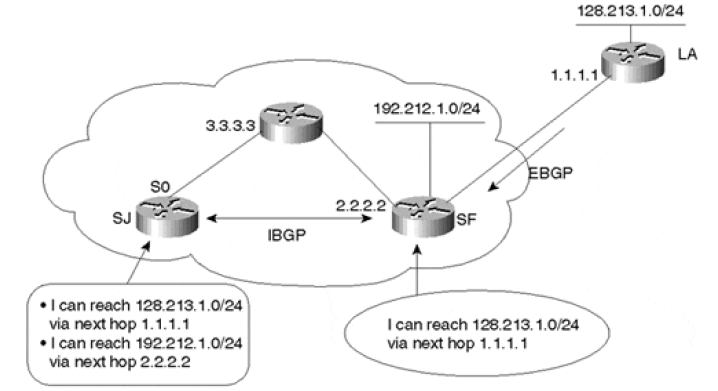
通常情况下,Next_Hop 属性遵循下面的规则:
- BGP Speaker 在向 EBGP 对等体发布某条路由时,会把该路由信息的下一跳属性设置为本地与对端建立 BGP 邻居关系的接口地址。
- BGP Speaker 将本地始发路由发布给 IBGP 对等体时,会把该路由信息的下一跳属性设置为本地与对端建立 BGP 邻居关系的接口地址。
- BGP Speaker 在向 IBGP 对等体发布从 EBGP 对等体学来的路由时,并不改变该路由信息的下一跳属性。
Local_pref
- Local_Pref 属性表明路由器的 BGP 优先级,用于判断流量离开 AS 时的最佳路由。
- 当 BGP 的设备通过不同的 IBGP 对等体得到目的地址相同但下一跳不同的多条路由时,将优先选择 Local_Pref 属性值较高的路由。
- Local_Pref 属性仅在 IBGP 对等体之间有效,不通告给其他 AS。
- Local_Pref 属性可以手动配置,如果路由没有配置 Local_Pref 属性,BGP 选路时将该路由的 Local_Pref 值按缺省值 100 来处理。
MED
- MED(Multi-Exit Discriminator)属性用于判断流量进入 AS 时的最佳路由。
- 当一个运行 BGP 的设备通过不同的 EBGP 对等体得到目的地址相同但下一跳不同的多条路由时,在其它条件相同的情况下,将优先选择 MED 值较小者作为最佳路由。
- MED 属性仅在相邻两个 AS 之间传递,收到此属性的 AS 一方不会再将其通告给任何其他第三方 AS。
- MED 属性可以手动配置,如果路由没有配置 MED 属性,BGP 选路时将该路由的 MED 值按缺省值 0 来处理。
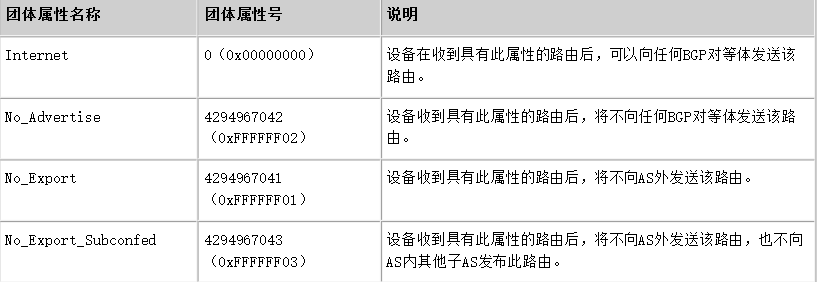
Community
Community 属性用于标识具有相同特征的 BGP 路由,使路由策略的应用更加灵活,同时降低了维护管理的难度。
团体属性分为自定义团体属性和公认团体属性。公认团体属性如下所示:
Originator_ID
Originator_ID 属性用于解决路由反射器场景中的环路问题。
Cluster_List
Cluster_List 属性用于解决路由反射器场景中的环路问题。
BGP 选择路由的策略
当到达同一目的地存在多条路由时,BGP 依次对比下列属性来选择路由:
- 如果下一跳不可达,则忽略此路由(这就是为什么有一条 IGP 路由作为下一跳如此重要的原因)
- 选择权重最大的一条路径
- 如果权重相同,选择本地偏向(local preference)最大的一条路由
- 如果没有源自本地的路由(locally originated routes),并且 local preference 相 同,则选择 AS_PATH 最短的路由
- 如果 AS_PATH 相同,选择 origin type 最低(
IGP < EGP < INCOMPLETE)的路由 - 如果 origin type 相同,选择 MED 最低的,如果这些路由都是从同一个 AS 收到的
- 如果 MED 相同,优先选择 eBGP(相比于 iBGP)
- 如果前面所有条件都相同,选择经过最近的 IGP 邻居的路由——也就是选择 AS 内部最短的到达目的的路径
- 如果内部路径也相同,那就依靠 BGP ROUTE_ID 来选择了。选择从 RID 最小的 BGP 路由器来的路由。对 Cisco 路由器来说,RID 就是路由器的 loopback 地址。
BGP 负载分担
当到达同一目的地址存在多条等价路由时,可以通过 BGP 等价负载分担实现均衡流量的目的。形成 BGP 等价负载分担的条件是“BGP 选择路由的策略”的 1 至 8 条规则中需要比较的属性完全相同。
IBGP 优化
为保证 IBGP 对等体之间的连通性,需要在 IBGP 对等体之间建立全连接关系。 如图所示,虽然 RTA-RTC 之间没有物理链路,但仍然有一条逻辑 peer 链路。
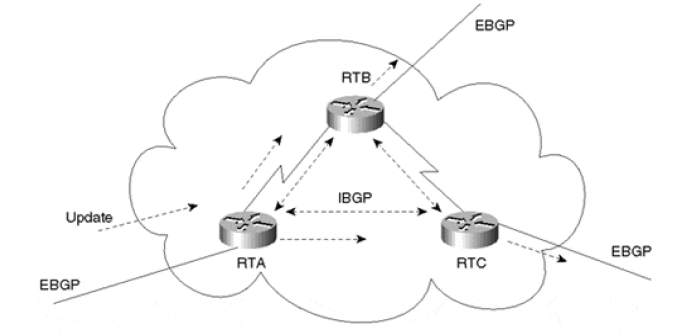
根据 BGP 对等体之间的交互原则 「从 IBGP 对等体获得的 BGP 路由,BGP 设备只发布给它的 EBGP 对等体。」,RTB 从 RTA 收到的 UPDATE 消息并不会发送给 RTC:
- RTC 是内部节点(同一个 AS)
- 这条 UPDATE 消息也是从内部节点发来的(RTA)
因此,如果 RTA-RTC 之间没有做 peer,RTC 就收不到 RTA 的消息;所以没有 RR 的情况 下必须得用 full-mesh。
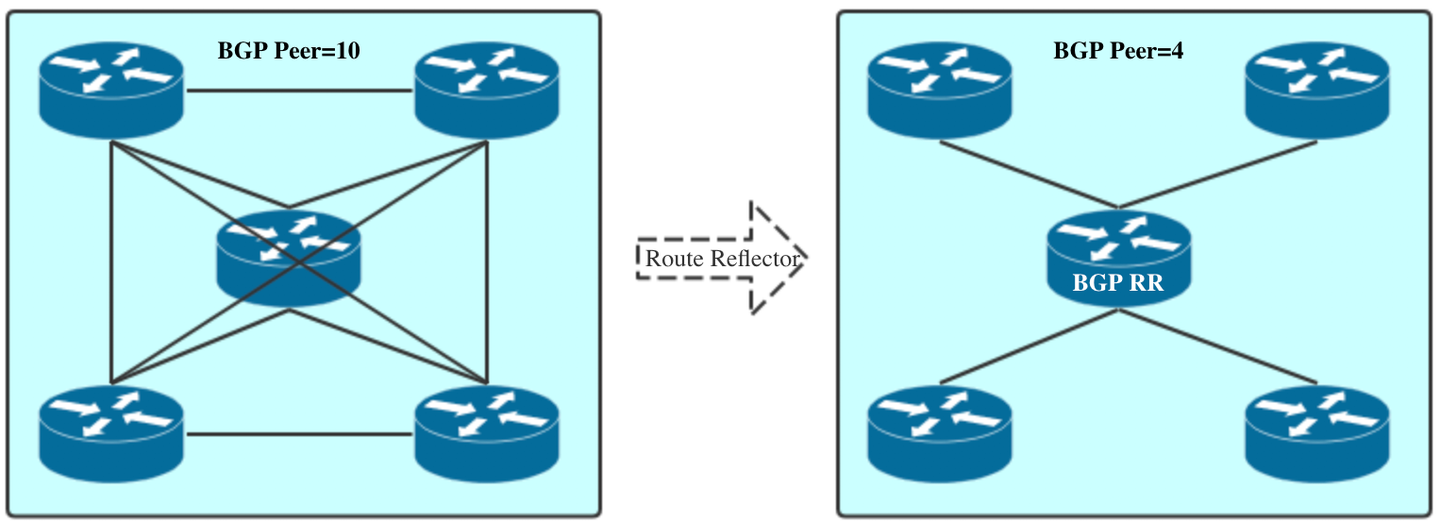
假设在一个 AS 内部有 n 台设备,那么建立的 IBGP 连接数就为 n(n-1)/2。当设备数目很多时,设备配置将十分复杂,而且配置后网络资源和 CPU 资源的消耗都很大。为了避免 full-mesh 的连接方式,常见的 IBGP 优化有两种,一种是 Route Reflector(路由反射器),一种是 BGP Confederation(BGP 联盟)。
Route Reflector
Route Reflector,路由反射器,这是一个特殊的 IBGP router。一般的 IBGP router 不会传递来自其他 IBGP router 的路由。但路由反射器是例外,它会将学习到的 IBGP 路由,传递给所有连接的 RR-client。这样,一个 BGP router 的路由可以不用与其他的 BGP router 建立连接,而通过路由反射器发送给其他的 BGP router。
在一个 AS 内部关于路由反射器有以下几种角色:
- Route Reflector:允许把从 IBGP 对等体学到的路由反射到其他 IBGP 对等体的 BGP 设备,类似 OSPF 网络中的 DR。
- Client:与 RR 形成反射邻居关系的 IBGP 设备。在 AS 内部客户机只需要与 RR 直连。
- Non-Client:既不是 RR 也不是客户机的 IBGP 设备。在 AS 内部非客户机与 RR 之间,以及所有的非客户机之间仍然必须建立全连接关系。
- Originator:在 AS 内部始发路由的设备。Originator_ID 属性用于防止集群内产生路由环路。
- Cluster:路由反射器及其客户机的集合。Cluster_List 属性用于防止集群间产生路由环路。
同一集群内的 RR-client 只需要与该集群的 RR 直接交换路由信息,因此客户机只需要与 RR 之间建立 IBGP 连接,不需要与其他客户机建立 IBGP 连接,从而减少了 IBGP 连接数量。RR 突破了 「从 IBGP 对等体获得的 BGP 路由,BGP 设备只发布给它的 EBGP 对等体。」的限制,并采用独有的 Cluster_List 属性和 Originator_ID 属性防止路由环路。
RR 向 IBGP 邻居发布路由规则如下:
- 从非客户机学到的路由,发布给所有客户机。
- 从客户机学到的路由,发布给所有非客户机和客户机(发起此路由的客户机除外)。
- 从 EBGP 对等体学到的路由,发布给所有的非客户机和客户机。
下列例子中有 5 个 BGP router,那么 full-mesh 需要管理总共 10 个 BGP peer 连接,而使用路由反射器,只需要 4 个 BGP peer。
Cluster_List 属性
路由反射器和它的客户机组成一个集群(Cluster),使用 AS 内唯一的 Cluster ID 作为标识。为了防止集群间产生路由环路,路由反射器使用 Cluster_List 属性,记录路由经过的所有集群的 Cluster ID。
- 当一条路由第一次被 RR 反射的时候,RR 会把本地 Cluster ID 添加到 Cluster List 的前面。如果没有 Cluster_List 属性,RR 就创建一个。
- 当 RR 接收到一条更新路由时,RR 会检查 Cluster List。如果 Cluster List 中已经有本地 Cluster ID,丢弃该路由;如果没有本地 Cluster ID,将其加入 Cluster List,然后反射该更新路由。
Originator_ID 属性
Originator ID 由 RR 产生,使用的 Router ID 的值标识路由的始发者,用于防止集群内产生路由环路。
- 当一条路由第一次被 RR 反射的时候,RR 将 Originator_ID 属性加入这条路由,标识这条路由的发起设备。如果一条路由中已经存在了 Originator_ID 属性,则 RR 将不会创建新的 Originator_ID 属性。
- 当设备接收到这条路由的时候,将比较收到的 Originator ID 和本地的 Router ID,如果两个 ID 相同,则不接收此路由。
备份路由反射器
为增加网络的可靠性,防止单点故障对网络造成影响,有时需要在一个集群中配置一个以上的 RR。由于 RR 打破了从 IBGP 对等体收到的路由不能传递给其他 IBGP 对等体的限制,所以同一集群内的 RR 之间中可能存在环路。这时,该集群中的所有 RR 必须使用相同的 Cluster ID,以避免 RR 之间的路由环路。
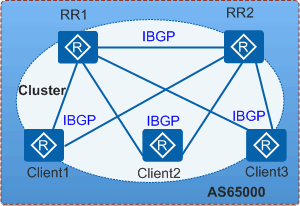
如上图,路由反射器 RR1 和 RR2 在同一个集群内,配置了相同的 Cluster ID。
- 当客户机 Client1 从 EBGP 对等体接收到一条更新路由,它将通过 IBGP 向 RR1 和 RR2 通告这条路由。
- RR1 和 RR2 在接收到该更新路由后,将本地 Cluster ID 添加到 Cluster List 前面,然后向其他的客户机(Client2、Client3)反射,同时相互反射。
- RR1 和 RR2 在接收到该反射路由后,检查 Cluster List,发现自己的 Cluster ID 已经包含在 Cluster List 中。于是 RR1 和 RR2 丢弃该更新路由,从而避免了路由环路。
多集群路由反射器
一个 AS 中可以存在多个集群,各个集群的 RR 之间建立 IBGP 对等体。当 RR 所处的网络层不同时,可以将较低网络层次的 RR 配成客户机,形成分级 RR。当 RR 所处的网络层相同时,可以将不同集群的 RR 全连接,形成同级 RR。
分级路由反射器:
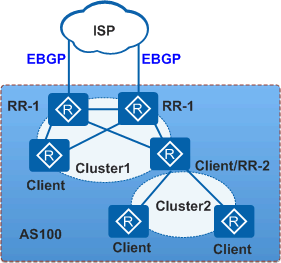
在实际的 RR 部署中,常用的是分级 RR 的场景。如上图,ISP 为 AS100 提供 Internet 路由。AS100 内部分为两个集群,其中 Cluster1 内的四台设备是核心路由器,采用备份 RR 的形式保证可靠性。
同级路由反射器:
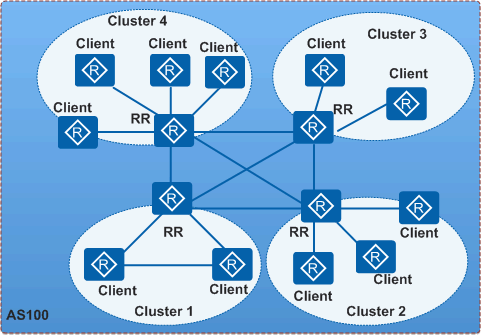
如上图,一个骨干网被分成多个集群。各集群的 RR 互为非客户机关系,并建立全连接。此时虽然每个客户机只与所在集群的 RR 建立 IBGP 连接,但所有 RR 和客户机都能收到全部路由信息。
BGP Confederation
解决 AS 内部的 IBGP 网络连接激增问题,除了使用路由反射器之外,还可以使用联盟(Confederation)。联盟将一个 AS 划分为若干个子 AS。每个子 AS 内部建立 IBGP 全连接关系,子 AS 之间建立联盟 EBGP 连接关系,但联盟外部 AS 仍认为联盟是一个 AS。配置联盟后,原 AS 号将作为每个路由器的联盟 ID。
这样有两个好处:
- 一是可以保留原有的 IBGP 属性,包括 Local Preference 属性、MED 属性和 NEXT_HOP 属性等;
- 二是联盟相关的属性在传出联盟时会自动被删除,即管理员无需在联盟的出口处配置过滤子 AS 号等信息的操作。
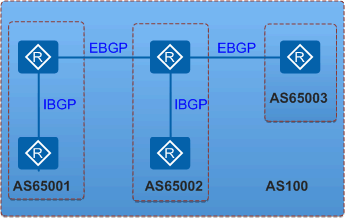
如上图所示:AS100 使用联盟后被划分为 3 个子 AS:AS65001、AS65002 和 AS65003,使用 AS100 作为联盟 ID。此时 IBGP 的连接数量从 10 条减少到 4 条,不仅简化了设备的配置,也减轻了网络和 CPU 的负担。而 AS100 外的 BGP 设备因为仅知道 AS100 的存在,并不知道 AS100 内部的联盟关系,所以不会增加 CPU 的负担。
方案对比
路由反射器和联盟的比较:
| 路由反射器 | 联盟 |
|---|---|
| 不需要更改现有的网络拓扑,兼容性好。 | 需要改变逻辑拓扑。 |
| 配置方便,只需要对作为反射器的设备进行配置,客户机并不需要知道自己是客户机。 | 所有设备需要重新进行配置。 |
| 集群与集群之间仍然需要全连接。 | 联盟的子 AS 之间是特殊的 EBGP 连接,不需要全连接。 |
| 适用于中、大规模网络。 | 适用于大规模网络。 |
BGP 平滑重启
BGP 的平滑重启 GR(Graceful Restart)作为高可靠性的解决方案,其根本目的都是为了保证用户业务在设备故障的时候不受影响或者影响最小。
BGP GR 技术保证了在设备重启或者主备倒换过程中转发层面能够继续指导数据的转发,同时控制层面邻居关系的重建以及路由计算等动作不会影响转发层面的功能,从而避免了路由震荡引发的业务中断,提高了整网的可靠性。
GR 相关概念:
- GR Restarter:指由管理员触发或故障触发后,以 GR 方式重启的设备。
- GR Helper:GR Restarter 的邻居,协助 GR Restarter 进行 GR 的设备。
- GR Time:是 GR Helper 检测到 GR Restarter 重启或者主备倒换后,保持转发信息不删除的时间。
BGP GR 的过程是:
- 利用 BGP 的能力协商机制,GR Restarter 和 GR Helper 了解彼此的 GR 能力,建立有 GR 能力的会话。
- 当 GR Helper 检查到 GR Restarter 重启或者主备倒换后,不删除和 GR Restarter 相关的路由和转发表项,也不通知其他邻居,而是等待重建 BGP 连接。
- GR Restarter 在 GR Time 超时前与重启前的所有 GR Helper 新建立好邻居关系。
路由聚合
在大规模的网络中,BGP 路由表十分庞大,给设备造成了很大的负担,同时使发生路由振荡的几率也大大增加,影响网络的稳定性。
路由聚合是将多条路由合并的机制,它通过只向对等体发送聚合后的路由而不发送所有的具体路由的方法,减小路由表的规模。并且被聚合的路由如果发生路由振荡,也不再对网络造成影响,从而提高了网络的稳定性。
BGP 在 IPv4 网络中支持自动聚合和手动聚合两种方式,而 IPv6 网络中仅支持手动聚合方式:
- 自动聚合:对 BGP 引入的路由进行聚合。配置自动聚合后,BGP 将按照自然网段聚合路由(例如非自然网段 A 类地址 10.1.1.1/24 和 10.2.1.1/24 将聚合为自然网段 A 类地址 10.0.0.0/8),并且 BGP 向对等体只发送聚合后的路由。
- 手动聚合:对 BGP 本地路由表中存在的路由进行聚合。手动聚合可以控制聚合路由的属性,以及决定是否发布具体路由。
为了避免路由聚合可能引起的路由环路,BGP 设计了 AS_Set 属性。AS_Set 属性是一种无序的 AS_Path 属性,标明聚合路由所经过的 AS 号。当聚合路由重新进入 AS_Set 属性中列出的任何一个 AS 时,BGP 将会检测到自己的 AS 号在聚合路由的 AS_Set 属性中,于是会丢弃该聚合路由,从而避免了路由环路的形成。
路由衰减
当 BGP 应用于复杂的网络环境时,路由振荡十分频繁。为了防止频繁的路由振荡带来的不利影响,BGP 使用路由衰减来抑制不稳定的路由。
路由振荡指路由表中添加一条路由后,该路由又被撤销的过程。当发生路由振荡时,设备就会向邻居发布路由更新,收到更新报文的设备需要重新计算路由并修改路由表。所以频繁的路由振荡会消耗大量的带宽资源和 CPU 资源,严重时会影响到网络的正常工作。
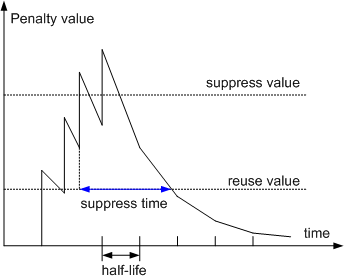
路由衰减使用惩罚值(Penalty value)来衡量一条路由的稳定性,惩罚值越高说明路由越不稳定。如上图所示,路由每发生一次振荡,BGP 便会给此路由增加 1000 的惩罚值,其余时间惩罚值会慢慢下降。当惩罚值超过抑制阈值(suppress value)时,此路由被抑制,不加入到路由表中,也不再向其他 BGP 对等体发布更新报文。被抑制的路由每经过一段时间,惩罚值便会减少一半,这个时间称为半衰期(half-life)。当惩罚值降到再使用阈值(reuse value)时,此路由变为可用并被加入到路由表中,同时向其他 BGP 对等体发布更新报文。从路由被抑制到路由恢复可用的时间称为抑制时间(suppress time)。
路由衰减只对 EBGP 路由起作用,对 IBGP 路由不起作用。这是因为 IBGP 路由可能含有本 AS 的路由,而 IGP 网络要求 AS 内部路由表尽可能一致。如果路由衰减对 IBGP 路由起作用,那么当不同设备的衰减参数不一致时,将会导致路由表不一致。
BGP 与 BFD 联动
BGP 协议通过周期性的向对等体发送报文来实现邻居检测机制。但这种机制检测到故障所需时间比较长,超过 1 秒钟。当数据的传输速度达到 Gbit/s 级别时,这种机制的检测时间将导致大量数据丢失,无法满足网络高可靠性的需求。BGP 与 BFD (Bidirectional Forwarding Detection)联动可以利用 BFD 的毫秒级快速检测机制解决上述问题。
BGP Rracking
BGP Tracking 可以为 BGP 提供快速的链路故障检测,加速 BGP 网络的收敛速度。当使能了 BGP Tracking 功能的 BGP 对等体之间的链路发生故障时,BGP Tracking 将快速感知到达邻居的路由的不可达,并由路由管理模块通知到 BGP,从而实现快速收敛。
与 BFD 特性相比,BGP Tracking 配置简单,只需在本地配置而不需要全网配置。但是由于 BGP Tracking 是路由层面的感知方式,而 BFD 是链路层面的感知方式,所以 BGP Tracking 收敛速度比 BFD 慢,不适用于对收敛时间要求较高的语音等业务。
BGP 安全性
BGP 使用认证和通用 TTL 安全保护机制 GTSM(Generalized TTL Security Mechanism)两个方法保证 BGP 对等体间的交互安全。
BGP 认证
BGP 认证分为 MD5 认证和 Keychain 认证,对 BGP 对等体关系进行认证是提高安全性的有效手段。MD5 认证只能为 TCP 连接设置认证密码,而 Keychain 认证除了可以为 TCP 连接设置认证密码外,还可以对 BGP 协议报文进行认证。
BGP GTSM
BGP GTSM 检测 IP 报文头中的 TTL(time-to-live)值是否在一个预先设置好的特定范围内,并对不符合 TTL 值范围的报文进行允许通过或丢弃的操作,从而实现了保护 IP 层以上业务,增强系统安全性的目的。
例如将 IBGP 对等体的报文的 TTL 的范围设为 254 至 255。当攻击者模拟合法的 BGP 协议报文,对设备不断的发送报文进行攻击时,TTL 值必然小于 254。如果没有使能 BGP GTSM 功能,设备收到这些报文后,发现是发送给本机的报文,会直接上送控制层面处理。这时将会因为控制层面处理大量攻击报文,导致设备 CPU 占用率高,系统异常繁忙。如果使能 BGP GTSM 功能,系统会对所有 BGP 报文的 TTL 值进行检查,丢弃 TTL 值小于 254 的攻击报文,从而避免了因网络攻击报文导致 CPU 占用率高的问题。
BGP ORF
RFC5291、RFC5292 规定了 BGP 基于前缀的 ORF(Outbound Route Filtering)能力,能将本端设备配置的基于前缀的入口策略通过路由刷新报文发送给 BGP 邻居。BGP 邻居根据这些策略构造出口策略,在路由发送时对路由进行过滤。这样不仅避免了本端设备接收大量无用的路由,降低了本端设备的 CPU 使用率,还有效减少了 BGP 邻居的配置工作,降低了链路带宽的占用率。
BGP 按组打包
目前现网路由表的快速增长,以及网络拓扑的复杂性导致 BGP 需要支持更多的邻居。特别是一些邻居数目多且路由量大的场景下,针对路由器需要给大量的 BGP 邻居发送路由,且大部分邻居具有相同出口策略的特点,要求较高的打包发包性能。
按组打包技术将所有拥有共同出口策略的 BGP 邻居当作是一个打包组。这样每条待发送路由只被打包一次然后发给组内的所有邻居,使打包效率指数级提升。例如,一个反射器有 100 个客户机,有 10 万条路由需要反射。如果按照每个邻居分别打包的方式,反射器 RR 在向 100 个客户机发送路由的时候,所有路由被打包的总次数是 10 万 ×100。而按组打包技术将这个过程变为 10 万 ×1,性能相当于提升了 100 倍。
BGP 与 IGP 交互
BGP 与 IGP 在设备中使用不同的路由表,为了实现不同 AS 间相互通讯,BGP 需要与 IGP 进行交互,即 BGP 路由表和 IGP 路由表相互引入。
BGP 引入 IGP 路由
BGP 协议本身不发现路由,因此需要将其他路由引入到 BGP 路由表,实现 AS 间的路由互通。当一个 AS 需要将路由发布给其他 AS 时,AS 边缘路由器会在 BGP 路由表中引入 IGP 的路由。为了更好的规划网络,BGP 在引入 IGP 的路由时,可以使用路由策略进行路由过滤和路由属性设置,也可以设置 MED 值指导 EBGP 对等体判断流量进入 AS 时选路。
BGP 引入路由时支持 Import 和 Network 两种方式:
- Import 方式是按协议类型,将 RIP、OSPF、ISIS 等协议的路由引入到 BGP 路由表中。为了保证引入的 IGP 路由的有效性,Import 方式还可以引入静态路由和直连路由。
- Network 方式是逐条将 IP 路由表中已经存在的路由引入到 BGP 路由表中,比 Import 方式更精确。
IGP 引入 BGP 路由
当一个 AS 需要引入其他 AS 的路由时,AS 边缘路由器会在 IGP 路由表中引入 BGP 的路由。为了避免大量 BGP 路由对 AS 内设备造成影响,当 IGP 引入 BGP 路由时,可以使用路由策略,进行路由过滤和路由属性设置。
MP-BGP
传统的 BGP-4 只能管理 IPv4 单播路由信息,对于使用其它网络层协议(如 IPv6、组播等)的应用,在跨 AS 传播时就受到一定限制。BGP 多协议扩展 MP-BGP(MultiProtocol BGP)就是为了提供对多种网络层协议的支持,对 BGP-4 进行的扩展。目前的 MP-BGP 标准是 RFC4760,使用扩展属性和地址族来实现对 IPv6、组播和 VPN 相关内容的支持,BGP 协议原有的报文机制和路由机制并没有改变。
MP-BGP 对 IPv6 单播网络的支持特性称为 BGP4+,对 IPv4 组播网络的支持特性称为 MBGP(Multicast BGP)。MP-BGP 为 IPv6 单播网络和 IPv4 组播网络建立独立的拓扑结构,并将路由信息储存在独立的路由表中,保持单播 IPv4 网络、单播 IPv6 网络和组播网络之间路由信息相互隔离,也就实现了用单独的路由策略维护各自网络的路由。
BGP 使用的报文中,与 IPv4 相关的三处信息都由 Update 报文携带,这三处信息分别是:NLRI 字段、Next_Hop 属性、Aggregator 属性。
为实现对多种网络层协议的支持,BGP 需要将网络层协议的信息反映到 NLRI 及 Next_Hop。因此 MP-BGP 引入了两个新的可选非过渡路径属性:
- MP_REACH_NLRI:Multiprotocol Reachable NLRI,多协议可达 NLRI。用于发布可达路由及下一跳信息。
- MP_UNREACH_NLRI:Multiprotocol Unreachable NLRI,多协议不可达 NLRI。用于撤销不可达路由。
参考资料
-
No backlinks found.