State of AI: 2024 年度人工智能报告之 Research 篇
本周四 stateof. Ai 1出品了 2024 年度人工智能报告2。该报告由英国知名风投公司 Air Street Capital 的合伙人 Nathan Benaich 等联合撰写,该系列报告从 2018 年开始已经连续撰写了 7 年。除了主要作者外,还有众多研究者、机构把关,既有深度又有广度,涉及科研进展、产业界发展、政治影响、AI 安全等众多领域,涵盖了 AI 的方方面面。本文编译自该报告,并附带简单分析,期待之后有机会能够进一步深度解读,强烈推荐阅读原报告。
以下为全文目录,受限于篇幅,本报告将分为 3 篇发布,本篇为第一篇,主要关注过去一年中 AI 领域的相关突破与进展,之后两篇将在接下来的两天同步发布,敬请期待。
- State of AI 2024 报告年度总结
- 科研进展:技术突破及其能力
- 产业界发展:当前 AI 创新的商业化应用以及对应的商业化影响
- 政治影响:AI 监管,AI 产生的经济影响,AI 的地缘政治演进
- AI 安全:明确和减轻将来庞大 AI 系统可能产生的灾难性影响
- 对 2025 年的预测
01 Summary
Research
- Frontier lab 的表现趋于一致,但在 o1 发布后,OpenAI 仍保持领先,规划和推理成为一个主要的前沿领域。
- Foundation Models 展示了它们突破语言的能力,随着多模态研究深入数学、生物学、基因组学、物理科学和神经科学等领域。
- 美国制裁未能阻止中国 (V)LLMs 在社区排行榜上的崛起。
Industry
- NVIDIA 依然是全球最强大的公司,享受着 3 万亿美元俱乐部的时光,而监管机构则在调查生成式人工智能领域的权力集中情况。
- 更成熟的生成式人工智能公司带来了数十亿美元的收入,而初创企业在视频和音频生成等领域开始获得认可。尽管公司们开始从模型转向产品,但关于定价和可持续性的长期问题仍未得到解决。
- 在公共市场的牛市推动下,人工智能公司的价值达到了 9 万亿美元,而私营公司的投资水平也健康增长。
Politics
- 随着全球治理努力停滞,国家和地区的人工智能监管仍在继续推进,美国和欧盟通过了一些有争议的立法。
- 计算需求的现实迫使大型科技公司面对现实世界中在 Scaling 和自身排放目标上的物理限制。与此同时,各国政府在建立能力方面的努力依然滞后。
- 预计人工智能对选举、就业和其他一系列敏感领域的影响尚未在任何规模上实现。
Safety
- 从安全到加速的氛围转变发生,因为之前警告我们人类将面临灭绝的公司需要加快企业销售和消费者应用的使用。
- 全球各国政府效仿英国,建立围绕人工智能安全的国家能力,成立研究所并研究关键国家基础设施的潜在脆弱性。
- 每一个提议的 jailbreaking “fix” 都未能成功,但研究人员对更复杂的长期攻击日益感到担忧。

02 Research
OpenAI 统治的结束与继续
OpenAI’s reign of terror came to an end, until…
在今年的大部分时间里,基准测试和社区排行榜都显示出 GPT-4 与“其他最优秀模型”之间的巨大差距。然而,Claude 3.5 Sonnet、Gemini 1.5 和 Grok 2 几乎消除了这一差距,因为模型性能现在开始趋于一致。
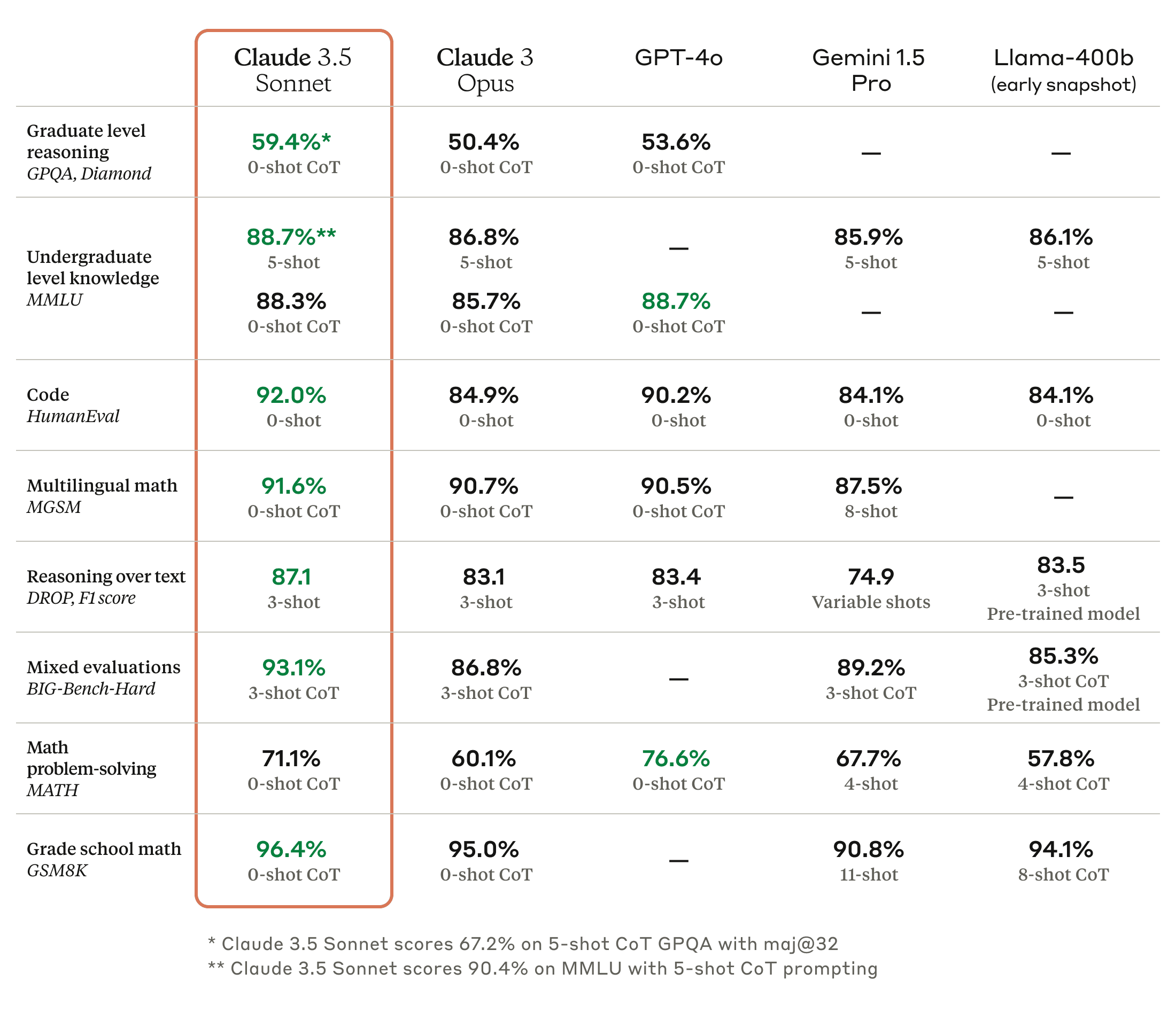
- 在正式基准测试和基于氛围的分析中,资金最充足的前沿实验室在各项能力上能够相互之间获得低个位数的分数。
- 模型现在在编码能力上始终表现出色,在 factual recall 和数学方面也很强,但在开放式问答和多模态问题解决上则表现较差。
- 许多模型变体的差异已足够小,因此可能主要是由于实现上的不同。例如,GPT-4o 在 MMLU 上的表现优于 Claude 3.5 Sonnet,但在旨在更具挑战性的 MMLU-Pro 上表现则似乎不如后者。
- 考虑到架构之间相对微妙的技术差异以及预训练数据中可能存在的重叠,模型构建者现在越来越需要在新的能力和产品特性上进行竞争。
…the Strawberry landed, doubling down on scaling inference compute
OpenAI 团队显然早已意识到 inference compute 的潜力,OpenAI o1 在其他实验室探索该技术的论文发布几周内便出现了[^3][^4]。
- 通过将计算从预训练和后训练转移到推理,o1 以逐步推理的方式(链式思维,CoT)处理复杂提示,并利用强化学习来优化 CoT 及其使用的策略。这使得解决多层次的数学、科学和编码问题成为可能,而这些问题在历史上由于 next-token prediction 的固有限制,通常是大型语言模型(LLMs)所难以应对的。
- OpenAI 在 reasoning-heavy 基准测试中报告了相对于 4o 的显著改进,尤其是在 AIME 2024(竞赛数学)上,得分高达 83.83,远超 13.4。
- 然而,这种能力的代价不菲:o1-preview 的 100 万个输入 token 成本为 15 美元,而 100 万个输出 token 则需花费 60 美元。这使得它比 GPT-4o 贵 3 到 4 倍。
- OpenAI 在其 API 文档中明确表示,o1 并不是 4o 的直接替代品,也不是处理需要快速响应、图像输入或 function calling 的任务的最佳模型。
o1 showcases both areas of incredible strength and persistent weakness
社区迅速对 o1 进行测试,发现它在某些逻辑问题和难题上的表现显著优于其他大型语言模型(LLMs)。然而,它的真正优势体现在复杂的数学和科学任务上,一段关于一名博士生惊讶反应的视频在网络上走红,视频中 o1 在大约一个小时内复现了他一年的博士代码。3
然而,该模型在某些类型的空间推理方面仍然较弱。像它的前辈一样,它仍然无法在棋局中自保……但未来或许会有所改变。4
Llama 3 closes the gap between open and closed models
在四月,Meta 发布了 Llama 3 系列,七月推出了 3.1,九月推出了 3.2。Llama 3.1 405B,作为他们迄今为止最大的模型,能够在推理、数学、多语言和长上下文任务上与 GPT-4o 和 Claude 3.5 Sonnet 抗衡。这标志着开放模型首次缩小了与专有前沿技术之间的差距。56
- Meta 坚持使用自 Llama 1 以来的相同 decoder-only 架构,仅进行了小幅调整,例如增加了更多的 transformer 层数和注意力头。
- Meta 使用了惊人的 15T 的 Token 来训练该系列。尽管这超出了
Chinchilla-optimal的训练计算量,但他们发现 8B 和 70B 模型在达到 15T 的训练量时表现出对数线性的改善。 - Llama 3.1 405B 是在超过 16,000 个 H100 GPU 上训练的,这是第一个在如此规模上训练的 Llama 模型。
- Meta 随后在九月推出了 Llama 3.2,其中包含了 11B 和 90B 的多模态语言模型(Llama 的多模态首次亮相)。
- 前者与 Claude 3 Haiku 竞争,后者则与 GPT-4o-mini 相抗衡。
- 该公司还发布了 1B 和 3B 的仅文本模型,旨在在设备上运行。
- 基于 Llama 的模型在 Hugging Face 上的下载量已超过 4.4 亿次。
But how ‘open’ are ‘open source’ models?
由于开源得到了相当大的社区支持,并成为一个热点监管问题,一些研究人员建议该术语常常被误用。它可能被用来将在权重、数据集、许可和访问方法等方面的开放实践混为一谈。7
模型基准测试与能力评估
Is contamination inflating progress?
随着新的模型系列在基准测试中报告出色的初始表现,研究人员越来越关注数据集污染的问题:即测试或验证数据泄漏到训练集中。8910
- Scale 的研究人员在一个新的 Grade School Math 1000(GSM1k)上重新测试了一些模型,该数据集反映了已建立的 GSM8k 基准的风格和复杂性,发现某些情况下性能显著下降。
- 同样,X.ai 的研究人员使用一个基于匈牙利全国决赛数学考试的数据集进行了模型的重新评估,结果也类似。
Researchers try to correct problems in widely used benchmarks
但基准测试挑战是双刃剑。一些最受欢迎的基准测试中存在惊人高的错误率,这可能导致我们低估某些模型的能力,带来安全隐患。同时,过拟合的诱惑也非常强烈。1112
- 爱丁堡大学的一个团队指出了 MMLU 中的错误数量,包括错误的真实答案、不明确的问题和多个正确答案。尽管大多数单独主题的错误率较低,但在某些领域(如病毒学)却出现了大幅上升,分析的实例中有 57%存在错误。
- 在经过手动修正的 MMLU 子集中,模型的整体表现有所提升,尽管在专业法律和形式逻辑方面表现下降。这表明不准确的 MMLU 实例在预训练过程中被学习到了。
- 在更具安全关键性的领域,OpenAI 警告称,SWE-bench 评估模型解决现实世界软件问题的能力,低估了模型的自主软件工程能力,因为其中包含了一些难以或无法解决的任务。
- 研究人员与基准测试的创建者合作,推出了 SWE-bench Verified。
Live by the vibes, die by the vibes…or close your eyes for a year and OpenAI is still #1
LMSYS Chatbot Arena 排行榜已成为社区最喜欢的通过“氛围” vibes 形式化评估的方法。但随着模型性能的提升,它开始产生一些反直觉的结果。
- 该竞技场允许用户并排与两个随机选择的聊天机器人互动,从而提供了一种粗略的众包评估。
- 然而,具有争议的是,这导致 GPT-4o 和 GPT-4o Mini 获得了相同的分数,后者的表现还超过了 Claude Sonnet 3.5。
- 这引发了人们的担忧,即该排名实际上变成了一种评估用户最偏爱的写作风格的方式。
- 此外,由于较小的模型在涉及更多令牌的任务中表现较差,8k 的上下文限制在某种程度上给它们带来了不公平的优势。
- 然而,早期版本的视觉排行榜现在开始获得关注,并与其他评估结果更好地对齐。
Are neuro-symbolic systems making a comeback?
推理能力和训练数据的不足意味着 AI 系统在数学和几何问题上常常表现不佳。借助 AlphaGeometry,一个符号推理引擎应运而生。13
- 谷歌 DeepMind 和纽约大学的团队利用符号引擎生成了数百万个合成定理和证明,并以此从零开始训练了一个语言模型。
- AlphaGeometry 在语言模型提出新构造和符号引擎进行推理之间交替,直到找到解决方案。
- 令人印象深刻的是,它在一项奥林匹克级几何问题的基准测试中解决了 30 个问题中的 25 个,接近人类国际数学奥林匹克金牌得主的表现。次于 AlphaGeometry 最好的 AI 表现仅解决了 10。
- 它还展示了泛化能力——例如,发现 2004 年 IMO 问题中的一个具体细节对于证明是多余的。
端侧小模型
It’s possible to shrink models with minimal impact on performance…
研究表明,模型在面对更深层次时具有鲁棒性——这些层旨在处理复杂、抽象或特定任务的信息——可以通过智能剪枝来实现。也许还有更进一步的可能性。[^16]14
- 一个来自 Meta 和麻省理工学院的团队研究了开放权重的预训练大型语言模型(LLMs),得出结论认为可以去掉多达一半的模型层,并且在问答基准测试中仅会出现微不足道的性能下降。
- 他们根据相似性识别出最佳的去除层,并通过少量高效的微调“修复”模型。
- NVIDIA 的研究人员采取了更激进的方法,通过剪枝层、神经元、注意力头和嵌入,并利用知识蒸馏进行高效再训练。
- 来自 Nemotron-415B 的 MINITRON 模型在使用多达 40 倍更少的训练 token 的情况下,达到了与 Mistral 7B 和 Llama-3 8B 等模型相当或更优的性能。
…as distilled models become more fashionable
正如 Andrej Karpathy 等人所言,目前的大型模型尺寸可能反映了训练效率低下。利用这些大模型来优化和合成训练数据,可以帮助训练出更具能力的小型模型。1516171819
- 谷歌采用了这种方法,从 Gemini 1.5 Pro 中蒸馏出了 Gemini 1.5 Flash,同时 Gemma-2 9B 是从 Gemma-2 27B 蒸馏而来的,Gemma 2B 则来自一个未发布的更大模型。
- 社区也有猜测认为,Claude 3 Haiku 是更大模型 Opus 的蒸馏版本,但 Anthropic 从未确认这一点。
- 这些蒸馏工作也在向多模态扩展。Black Forest Labs 发布了 FLUX.1 dev,这是从他们的 Pro 模型蒸馏而来的开放权重文本到图像模型。
- 为了支持这些努力,社区开始制作开源蒸馏工具,如 arcee.ai 的 DistillKit,支持基于 Logit 和隐藏状态的蒸馏。
- Meta 在更新条款后,Llama 3.1 405B 也被用于蒸馏,这样输出的 logits 可以用于改进任何模型,而不仅限于 Llama 模型。
Models built for mobile compete with their larger peers
随着大型科技公司考虑大规模终端用户部署,我们开始看到性能优越的 LLM 和多模态模型,这些模型足够小,可以在智能手机上运行。
- 微软的 phi-3.5-mini 是一个 3.8B 的语言模型,与 7B 和 Llama 3.1 8B 等更大模型竞争。它在推理和问答方面表现良好,但由于体积限制,其事实知识受到制约。为了实现设备上的推理,该模型被量化为 4 位,将内存占用减少到约 1.8GB。
- 苹果推出了 MobileCLIP,这是一系列高效的图像-文本模型,针对智能手机上的快速推理进行了优化。通过使用新颖的多模态强化训练,他们通过从图像描述模型和强大的 CLIP 编码器集成中转移知识,提高了紧凑模型的准确性。
- Hugging Face 也参与了这一行动,推出了 SmolLM,一系列小型语言模型,提供 135M、360M 和 1.7B 三种格式。通过使用经过高度策划的合成数据集,该数据集是通过增强版 Cosmopedia 创建的,团队在该规模下实现了最新的 SOTA 性能。
Strong results in quantization point to an on-device future
通过降低参数的精度,可以缩小大型语言模型(LLMs)的内存需求。研究人员越来越能够最小化性能的 trade-offs。
- 微软的 BitNet 使用“BitLinear”层替代标准线性层,采用 1 位权重和量化激活20。
- 与全精度模型相比,它展示了竞争力的性能,并表现出与全精度变换器类似的规模规律,同时实现了显著的内存和能源节省。
- 微软随后推出了 BitNet b1.58,使用三元权重以匹配 3B 规模下的全精度 LLM 性能,同时保持效率提升21。
- 与此同时,字节跳动的 TiTok(基于变换器的一维标记器)将图像量化为紧凑的 1D 离散标记序列,用于图像重建和生成任务。这使得图像可以用少至 32 个标记表示,而不是数百或数千个标记22。
Hybrid Models
Hybrid models begin to gain traction
结合注意力和其他机制的模型能够维持甚至提高准确性,同时降低计算成本和内存占用。
- 选择性状态空间模型
Selective state-space models,如去年的 Mamba,旨在更高效地处理长序列,能够在某种程度上与 Transformer 竞争,但在需要复制或上下文学习的任务上表现较差。尽管如此,Falcon 的 Mamba 7B 23 在与同等规模的 Transformer 模型相比时,展现了令人印象深刻的基准性能。 - 混合模型似乎是一个更有前景的方向。结合自注意力和多层感知机(MLP)层,AI 21 的 8B Mamba-2-Hybrid2425,在知识和推理基准测试中超越了 8B Transformer,同时在推理时生成 token 的速度快达 8 倍。
- 在一场怀旧之旅中,循环神经网络 RNN 的复兴初见端倪,尽管由于训练和扩展的困难,它们曾一度失宠。由谷歌 DeepMind 训练的 Griffin 26 结合了线性递归和局部注意力,在训练所需的 token 数量减少 6 倍的情况下,仍能与 Llama-2 相抗衡。
And could we distill transformers into hybrid models? It’s…complicated.
通过从更大、更强大的模型中转移知识,可以提高次二次模型的性能,从而使我们能够在下游任务中利用它们的高效性。
- MOHAWK 27 是一种从大型预训练 transformer 模型(教师)向较小的次二次模型(学生),如状态空间模型(SSM),蒸馏知识的新方法。
- 它的步骤包括:
- 对齐学生模型和教师模型的序列变换矩阵
- 对齐每一层的隐藏状态
- 将教师模型的其余权重转移到学生模型上进行微调。
- 作者们创建了 Phi-Mamba,这是一种结合了 Mamba-2 和 MLP 块的新学生模型,以及一个名为 Hybrid-Phi-Mamba 的变体,后者保留了一些来自教师模型的注意力层。
- MOHAWK 能够训练 Phi-Mamba 和 Hybrid-Phi-Mamba,使其性能接近教师模型。Phi-Mamba 仅使用了 3B 个 token 进行蒸馏,这不到之前最佳表现的 Mamba 模型所用数据的 1%,也仅为 Phi-1.5 模型本身的 2%。
Either way, the transformer continues to reign supreme (for now)
对 Transformer 替代方案和混合模型的研究很有趣,但在这个阶段仍然显得小众。目前,似乎有一种范式统治着所有模型。
合成数据与数据质量
Synthetic data starts gaining more widespread adoption…
去年的报告指出了关于合成数据的不同看法:一些人认为它有用,而另一些人则担心它可能通过累积错误导致模型崩溃。如今,观点似乎正在逐渐变得积极。
- 除了作为 Phi 系列的主要训练数据来源外,合成数据在训练 Claude 3 28 时也被 Anthropic 使用,以帮助表示训练数据中可能缺失的场景。
- Hugging Face 使用 Mixtral-8x7B Instruct 生成了超过 3000 万个文件和 250 亿个 token 的合成教科书、博客文章和故事,以重建他们称之为 Cosmopedia 29的 Phi-1.5 训练数据集。
- 为了简化这一过程,NVIDIA 发布了 Nemotron-4-340B 系列模型30,这是一套专门为合成数据生成设计的模型,采用宽松的许可协议。Meta 的 Llama 也可以用于合成数据生成31。
- 通过直接从对齐的大型语言模型(LLM)中提取数据,似乎也可以创建高质量的合成指令数据,使用的技术如 Magpie32。这种方式微调的模型在性能上有时可与 Llama-3-8B-Instruct 相媲美。
…but Team Model Collapse isn’t going down without a fight
随着模型构建者不断推进,研究人员集中精力尝试评估合成数据的数量是否存在一个临界点,从而触发这些结果,以及是否有任何缓解措施有效。
- 来自牛津和剑桥的研究者的一篇《自然》论文发现,模型崩溃发生在各种 AI 架构中,包括微调的语言模型,这挑战了预训练或定期接触少量原始数据可以防止性能下降(通过困惑度评分衡量)的观点。
- 这创造了“先发优势”,因为持续获取多样化的人工生成数据对于维持模型质量变得越来越关键。
- 然而,这些结果主要集中在一个场景中,即随着世代交替,真实数据被合成数据替代。实际上,真实数据和合成数据通常是同时累积的。
- 其他研究表明,只要合成数据的比例不太高,通常可以避免模型崩溃。
Web data is decanted openly at scale - proving quality is key
- Hugging Face 团队构建了一个包含 15T token 的数据集33,用于 LLM 的预训练,利用了 96 个 CommonCrawl 快照,生成的 LLM 在性能上优于其他开放的预训练数据集。他们还发布了使用说明手册。
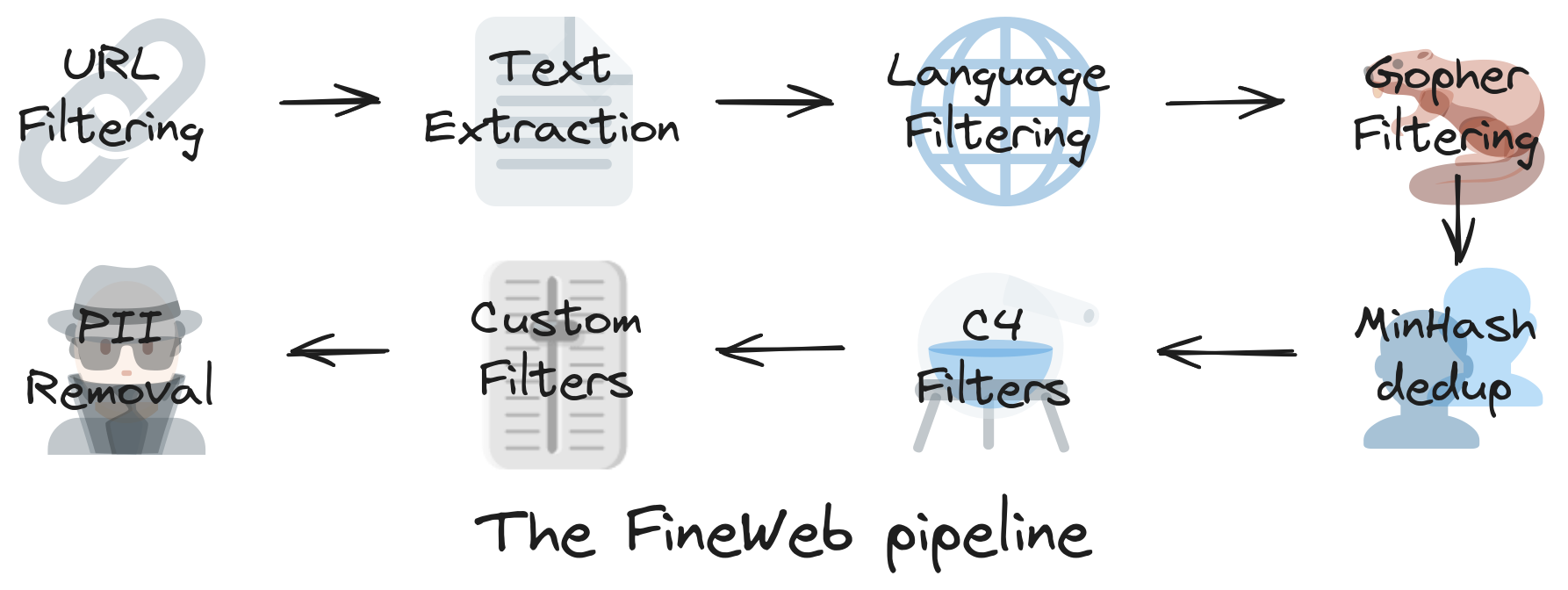
- FineWeb 数据集通过多步骤过程创建,包括基础过滤、每个数据集的独立 MinHash 去重、从 C4 数据集中派生的选择性过滤器和团队的自定义过滤器。
- 使用 trafilatura 库进行的文本提取产生的质量高于默认的 CommonCrawl WET 文件,尽管最终的数据集显著较小。
- 他们发现去重在提升性能方面确实有效,但在达到收益递减的临界点后,效果开始下降。
- 团队还使用了 llama-3-70b-instruct 对 FineWeb 中的 50 万样本进行标注,按 0 到 5 的尺度评估其教育质量。FineWeb-edu 经过筛选,仅保留评分在 3 分以上的样本,尽管规模显著较小,却在性能上超越了 FineWeb 及所有其他开放数据集。
RAG 与 Embedding 模型
Retrieval and embeddings hit the center stage
尽管检索和嵌入技术并不新鲜,但对检索增强生成(RAG)日益增长的兴趣促使了嵌入模型质量的提升34。
- 遵循在常规 LLMs 中证明有效的策略,规模带来了显著的性能提升(GritLM 拥有约 47B 参数,而之前的嵌入模型普遍为 110M)35。
- 同样,使用广泛的网络规模语料库和改进的过滤方法也使较小模型的性能大幅提升。与此同时,ColPali 是一种视觉-语言嵌入模型36,它利用文档的视觉结构,而不仅仅是其文本嵌入,以改善检索效果。
- 在检索模型这一子领域,开放模型通常超越了来自最大实验室的专有模型。在 MTEB 检索排行榜上,OpenAI 的嵌入模型排名第 29,而 NVIDIA 的开放模型 NV-Embed-v 2 则名列第一37。
Context proves a crucial driver of performance
传统的检索增强生成 RAG 解决方案通常涉及以 256 个 token 为一组创建文本片段,使用滑动窗口(前一个片段重叠 128 个令牌)。虽然这样可以提高检索效率,但准确性显著降低。
- Anthropic 通过使用
contextual embeddings38解决了这个问题,在这种方法中,prompt 指示模型生成文本,以解释文档中每个片段的上下文。 - 他们发现,这种方法使得前 20 次检索失败率降低了 35%(从 5.7%降至 3.7%)。
- 随后,这种方法可以通过 Anthropic 的 prompt caching 进行扩展。
- 正如 CMU 的 Fernando Diaz 39 在最近的讨论中指出的,这是将某一领域(例如早期语音检索和文档扩展工作)开创的技术应用于另一个领域的极佳例子。这再次印证了
what is new, is old的观点。 - 来自 Chroma 的研究40 表明,选择不同的分块策略可能会影响检索性能,召回率差异可达 9%。
Evaluation for RAG remains unsolved
许多常用的 RAG 基准都是 repurposed 的检索或问答数据集。它们无法有效评估引用的准确性、每段文本对整体答案的重要性,以及相互矛盾的信息点的影响。
- 研究人员目前正在开创一些新方法,如 Ragnarök41,它引入了一种基于网络的场所,通过成对系统比较进行人工评估。这一方法解决了超越传统自动化指标评估 RAG 质量的挑战。
- 同时,Researchy Questions 42 提供了一个大规模的复杂多面问题集合,这些问题需要深入研究和分析才能回答,来源于真实用户查询。
大规模训练与电力短缺
Frontier labs face up to the realities of the power grid and work on mitigations
随着计算集群规模的扩大,构建和维护变得更加困难。集群需要高带宽、低延迟的连接,并对设备的异构性非常敏感。研究人员看到了替代方案的潜力。
- Google DeepMind 提出了分布式低通信(DiLoCo)优化算法43,该算法允许在多个松散连接的
islands of devices上进行训练。 - 每个岛屿在与其他岛屿通信之前执行大量本地更新步骤,从而减少对频繁数据交换的需求。他们能够在这 8 个岛屿之间实现完全同步的优化,同时将通信减少 500 倍。
- Google DeepMind 还提出了 DiLoCo 的改进版本,优化用于异步设置44。
- Prime Intellect 的研究人员发布了 DiLoCo 的开源实现和复现45,并将其规模扩大了 3 倍,以证明其在 10 亿参数模型上的有效性。
Could better data curation methods reduce training compute requirements?
数据整理是有效预训练的重要组成部分,但通常是手动和低效完成的。这不仅难以扩展,而且浪费,尤其是对于多模态模型来说。
- 通常,整个数据集是在训练前一次性处理的,这并未考虑训练样本的相关性在学习过程中的变化。这些方法通常在训练之前应用,因此无法在训练期间适应不断变化的需求。
- Google DeepMind 的 JEST 46 联合选择整个数据批次,而不是独立选择单个样本。选择过程由“可学习性评分”(由预训练参考模型确定)指导,该评分评估数据对训练的有用性。它能够将数据选择直接集成到训练过程中,使其具有动态和适应性。
- JEST 在数据选择和部分训练过程中使用低分辨率图像处理,显著降低了计算成本,同时保持了性能优势。
来自中国的模型
Chinese (V)LLMs storm the leaderboards despite sanctions
DeepSeek、零一万物、智谱和阿里巴巴生产的模型在 LMSYS 排行榜上取得了优异的位置,尤其在数学和编码方面表现尤为出色。
- 中国实验室的最强模型在与美国实验室生产的第二强前沿模型竞争的同时,还在某些子任务上对现有最优技术(SOTA)构成挑战。
- 这些实验室优先考虑计算效率,以弥补对 GPU 访问的限制,学会了比美国同行更有效地利用资源。
- 中国实验室各有不同的优势。例如,DeepSeek 开创了 Multi-head Latent Attention 等技术,以减少推理过程中的内存需求,并增强了混合专家(MoE)架构。
- 同时,01.AI 则较少关注架构创新,而是致力于构建强大的中文数据集,以弥补在像 Common Crawl 这样的热门仓库中相对不足的情况。
And Chinese open source projects win fans around the world
为了推动国际采纳和评估,中国实验室已成为热情的开源贡献者。一些模型在各个子领域中脱颖而出,成为强有力的竞争者。
- DeepSeek 在编码任务中已成为社区的热门选择,deepseek-coder-v2 因其速度快、轻量级和准确性而受到青睐。
- 阿里巴巴最近发布了 Qwen-2 系列47,社区对其视觉能力印象深刻,涵盖了从复杂的 OCR 任务到分析复杂艺术作品的能力。
- 在较小的模型方面,清华大学的 NLP 实验室资助了 OpenBMB 项目,该项目衍生出了 MiniCPM 项目4849。
- 这些模型参数小于 2.5 亿,能够在设备上运行。它们的 2.8 亿视觉模型在某些指标上仅稍逊于 GPT-4V,而基于 8.5 亿参数的 Llama 3 模型在某些指标上超越了它。
- 清华大学的知识工程组还创建了 CogVideoX,这是最强大的文本转视频模型之一。
VLMs 开箱即用即可达到最优性能
VLMs achieve SOTA performance out-of-the-box
2018 年发布的首个 State of AI Report 详细描述了研究人员通过创建数百万个标记视频的数据集,努力教会模型常识场景理解的艰辛过程。如今,每个主要的前沿模型构建者都提供开箱即用的视觉能力。即使是一些小型模型,比如来自微软的 Florence-2 或 NVIDIA 的 LongVILA,其参数规模在数亿到个位数十亿之间,也能取得显著成果。艾伦人工智能研究所的开源模型 Molmo 在与更大规模的专有模型 GPT-4o 对抗时也能表现出色。5051525354
Diffusion 模型与文生视频大战
Diffusion models for image generation become more and more sophisticated
在从文本到图像的扩散模型发展中,Stability AI 继续寻找提高质量和效率的改进方案。
- 对抗性扩散蒸馏55
Adversarial diffusion distillation通过将生成高质量图像所需的采样步骤从可能的数百步减少到 1-4 步,显著加快了图像生成速度,同时保持了高保真度。 - 它将对抗训练与评分蒸馏相结合:模型仅使用预训练的扩散模型作为指导进行训练。除了实现单步生成外,作者还专注于降低计算复杂性和提高采样效率。
- 校正流
Rectified flow56通过直接的直线连接数据和噪声,而不是曲线路径,改进了传统的扩散方法。他们将这一方法与一种新颖的基于变换器的文本到图像架构结合起来,允许文本和图像组件之间的信息双向流动。这增强了模型根据文本描述生成更准确和连贯的高分辨率图像的能力。
Stable Video Diffusion marks a step forward for high-quality video generation…
Stability AI 发布了稳定视频扩散57,这是首批能够根据文本提示生成高质量、逼真视频的模型之一,并且在可定制性方面也有了显著提升。团队采用了三阶段的训练方法:
- 在大规模的文本到图像数据集上进行图像预训练
- 在大规模、经过整理的低分辨率视频数据集上进行视频预训练
- 在较小的高分辨率视频数据集上进行微调。
- 今年 3 月,他们推出了稳定视频 3D,针对第三个物体数据集进行了微调,以预测 3D 轨道
…leading the big labs to release their own gated text-to-video efforts
谷歌 DeepMind 和 OpenAI 都为我们提供了强大的文本到视频扩散模型的简要预览。然而,访问权限仍然受到严格限制,且两者都没有提供太多技术细节。
- OpenAI 的 Sora 58 能够生成长达一分钟的视频,同时保持 3D 一致性、物体持久性和高分辨率。它使用时空补丁,类似于变换器模型中使用的令牌,但用于视觉内容,以便从大量视频数据集中高效学习。
- Sora 还在其原始尺寸和纵横比的视觉数据上进行了训练,消除了通常会降低质量的裁剪和调整大小。
- 谷歌 DeepMind 的 Veo 59 将文本和可选的图像提示与噪声压缩视频输入结合,通过编码器和潜在扩散模型处理这些输入,以创建独特的压缩视频表示。系统随后将该表示解码为最终的高分辨率视频。
- 此外,Runway 的 Gen-3 Alpha、Luma 的 Dream Machine 和快手的 Kling 也参与了这场竞争。
Meta goes even further, throwing audio into the mix
在保持其他实验室的限制性方法的同时,Meta 通过 Make-A-Scene 和 Llama 系列整合了不同模态的工作,以构建 Movie Gen59。
- Movie Gen 的核心是一个 30B 参数的视频生成模型和一个 13B 参数的音频生成模型,分别能够生成 16 秒、每秒 16 帧的视频和 45 秒的音频片段。这些模型利用了文本到图像和文本到视频任务的联合优化技术,以及生成任意长度视频的连贯音频的新颖扩展方法。
- Movie Gen 的视频编辑功能结合了先进的图像编辑技术与视频生成,允许进行局部编辑和整体更改,同时保留原始内容。这些模型是在许可和公开可用的数据集的组合上进行训练的。
- Meta 通过 A/B 人类评估比较,展示了在四个主要能力上与竞争行业模型相比的积极净胜率。研究人员表示,他们计划在未来推出该模型,但并未承诺具体的时间表或发布策略。
AI for Science
AI gets en-Nobel-ed
作为人工智能作为科学学科和加速科学工具真正成熟的标志,瑞典皇家科学院向深度学习的开创者以及其在科学中迄今为止最知名应用的架构师颁发了诺贝尔奖。这一消息得到了整个领域的庆祝。
AlphaFold 3: going beyond proteins and their interactions with other biomolecules 超越蛋白质及其与其他生物分子的相互作用
DeepMind 和 Isomorphic Labs 发布了 AlphaFold 360,作为 AlphaFold 2 的继任者,现在能够建模小分子药物、DNA、RNA 和抗体与蛋白质靶标的相互作用。
- 与 AlphaFold 2 相比,AlphaFold 3 进行了重大的算法改进:所有的等变约束被移除,取而代之的是简化和扩展,同时结构模块被一个扩散模型替代,用于构建 3D 坐标。
- 研究人员声称,AlphaFold 3 在与其他方法(特别是小分子对接)相比时表现出色,尽管没有与更强的基线进行比较。
- 值得注意的是,目前尚未提供开源代码。多个独立团队正在努力公开复现该工作。
…starting a race to become the first to reproduce a fully functioning AlphaFold3 clone
不发布 AlphaFold 3 代码的决定引发了高度争议,许多人将责任归咎于《自然》杂志。抛开政治因素不谈,初创公司和人工智能社区之间展开了一场竞赛6162,争相将自己的模型打造成可行的替代方案。
- 第一个推出的模型是百度的 HelixFold363,该模型在配体结合方面与 AlphaFold 3 相当。百度提供了一个网络服务器,并将其代码完全开源,供非商业使用。
- Chai Discovery(由 OpenAI 支持)最近发布的 Chai-1 分子结构预测模型64 因其性能和高质量的实现而广受欢迎。该网络服务器也可用于商业药物发现。
- 我们仍在等待一个完全开源且没有限制的模型(例如,使用输出进行其他模型的训练)。如果 DeepMind 开始担心替代模型成为社区的宠儿,他们会更快地全面发布 AlphaFold 3 吗?
AlphaProteo: DeepMind flexes new experimental biology capabilities
DeepMind 神秘的蛋白质设计团队终于“揭开了面纱”,推出了他们的第一个模型 AlphaProteo6566,这是一个生成模型,能够设计具有 3 到 300 倍更好亲和力的亚纳摩尔蛋白质结合剂。
- 虽然提供的技术细节不多,但似乎该模型是基于 AlphaFold 3 构建的,可能是一个扩散模型。目标表位上的“热点”也可以被指定。
- 该模型能够设计出比以往工作(例如 RFDiffusion)具有 3 到 300 倍更好结合亲和力的蛋白质结合剂。蛋白质设计领域的“肮脏秘密”是,计算机筛选与生成建模同样重要(甚至更为重要),论文中指出基于 AlphaFold 3 的评分是关键。
- 他们还利用信心指标筛选大量可能的新靶标,以便为未来的蛋白质结合剂设计提供基础。
The Bitter Lesson: Equivariance is dead…long live equivariance!
等变性 Equivariance 是赋予模型固有偏置,使其能够自然处理旋转、平移和(有时)反射的概念。自 AlphaFold 2 以来,这一直是几何深度学习和生物分子建模研究的核心。然而,最近一些顶尖实验室的研究对这一既定信念提出了质疑。
- 第一枪是由苹果公司打响67的,他们发表的一篇论文在使用非等变扩散模型和变换器编码器预测小分子 3D 结构方面获得了最优结果。
- 值得注意的是,作者显示,使用该领域无关的模型并没有对泛化能力产生负面影响,并且在使用足够规模的情况下,始终能够超越专业模型。
- 接下来是 AlphaFold 368,臭名昭著地放弃了前一模型中的所有等变性和框架约束,转而采用另一种扩散过程,结合增强技术和规模。
- 尽管如此,等变模型显著提高的训练效率意味着这种做法可能会持续一段时间(至少对于那些研究大型系统(如蛋白质)的学术团队来说)。
Scaling frontier models of biology: EvolutionaryScale’ ESM3
自 2019 年以来,Meta 一直在发布基于 Transformer 的语言模型(进化规模模型),这些模型是在大规模氨基酸和蛋白质数据库上训练的。当 Meta 在 2023 年终止这些工作时,团队创立了 EvolutionaryScale。今年,他们发布了 ESM369,这是一个前沿的多模态生成模型,训练内容涵盖蛋白质的序列、结构和功能,而不仅仅是序列。
- 该模型是一个双向 Transformer,将代表三种模态的令牌作为独立轨道融合到一个单一的潜在空间中。
- 与传统的掩码语言建模不同,ESM3 的训练过程使用了可变掩码调度,使模型能够接触到多种掩码序列、结构和功能的组合。ESM3 学习预测任意模态组合的补全。
- ESM3 被用于生成与已知绿色荧光蛋白(GFP)具有低序列相似性的全新蛋白质。
Language models that learn to design human genome editors
我们之前介绍了如何利用在大规模多样的天然蛋白质序列数据集上预训练的语言模型(例如 ProGen2)来设计与自然同类序列截然不同的功能性蛋白质。现在,Profluent 已在其 CRISPR-Cas Atlas 上对 ProGen2 进行了微调,以生成具有新序列的功能性基因组编辑器,重要的是,这些编辑器首次被证明能够在体外编辑人类细胞的 DNA70。
- CRISPR-Cas Atlas 包含超过 100 万个多样化的 CRISPR-Cas 操作子,包括各种效应系统,这些操作子来自于 262TB 的组装微生物基因组和宏基因组,涵盖了不同的门类和生态系统。生成的序列与 CRISPR-Cas Atlas 中的天然蛋白质相比,具有 4.8 倍的多样性。与最近的天然蛋白质的中位相似性通常在 40%到 60%之间。
- 一个针对 Cas9 蛋白微调的模型能够生成新型编辑器,并在人体细胞中进行了验证。其中一个编辑器提供了最佳的编辑性能,其与 SpCas9 的序列相似性为 71.7%,并已开源为 OpenCRISPR-1。
Yet, evals and benchmarking in BioML remains poor
生物学与机器学习交叉领域研究的根本问题在于,能够同时训练前沿模型并进行严格生物评估的人才非常稀缺。
- 2023年底的两项研究,PoseCheck 71和 PoseBusters72,表明用于分子生成和蛋白质-配体对接的机器学习模型生成的结构(姿态)存在明显的物理违反。
- 即使是 AlphaFold 3的论文也遭遇了一些挑战,一家小型初创公司展示了使用稍微先进的传统对接管道的效果超过了 AF3。
- 由 Valence Labs 牵头的新行业联盟,包括主要制药公司(如 Recursion、Relay、默克、诺华、强生和辉瑞),正在开发 Polaris,一个用于 AI 驱动药物发现的基准测试平台。Polaris 将提供高质量的数据集,促进评估,并认证基准73。
- 与此同时,Recursion 在扰动映射构建方面的工作使他们创建了一套新的基准和指标74。
Foundation models across the sciences: inorganic materials (无机材料)
为了确定物理材料的属性及其在反应中的行为,必须进行原子级别的模拟,目前依赖于密度泛函理论。该方法功能强大,但速度较慢且计算成本高。尽管计算力场(原子间势)的替代方法更快,但其准确性往往不足以满足需求,特别是在反应事件和相变过程中。
- 在2022年,等变消息传递神经网络(MPNN)
message passing neural networks结合高效的多体消息(MACE)在 NeurIPS 上被提出75。 - 现在,作者们展示了 MACE-MP-076,它采用 MACE 架构,并在材料项目轨迹数据集上进行训练,该数据集包含数百万个结构、能量、磁矩、力和应力。
- 该模型通过同时考虑四个原子的相互作用,将消息传递层的数量减少到两个,并且仅在网络的特定部分使用非线性激活。
- 它能够在固态、液态和气态中进行广泛化学性质的分子动力学模拟。
Expanding the protein function design space: challenging folds and soluble analogues 扩展蛋白质功能设计空间:具有挑战性的折叠和可溶性类似物。
对在膜环境中存在但不以可溶形式出现的蛋白质进行结构特征描述和生成是具有挑战性的,这阻碍了旨在靶向膜受体的药物开发。同样,设计大型蛋白质折叠并包含非局部拓扑也是一项难题。AlphaFold 2和序列模型能否解决这个问题,并为药物设计师提供一个更大、以前无法获得的可溶性蛋白质组?
- 为了做到这一点77,作者们首先使用一个反向的 AF2 模型,该模型在给定目标折叠结构的情况下生成初始序列。然后这些序列在被 ProteinMPNN 优化之前,先由 AF2 重新预测结构,接着根据与目标结构的结构相似性进行筛选。
- 这个 AF2-MPNN 流程在三种具有挑战性的折叠结构上进行了测试:IGF、BBF 和 TBF,它们具有治疗用途
- 还可以生成仅存在于膜上的折叠结构的可溶性类似物,这可以极大地加快针对膜结合受体蛋白的药物发现速度。
Foundation models for the mind: learning brain activity from fMRI
深度学习最初受到神经科学的启发,现在正被用于对大脑本身进行建模。BrainLM 78是一个基于由功能性磁共振成像(fMRI)生成的 6700 小时人类大脑活动记录的基础模型,功能性磁共振成像可检测血氧变化。
该模型学习重建被掩盖的时空大脑活动序列,重要的是,它可以推广到保留的分布(右图)。这个模型可以进行微调以预测临床变量,例如年龄、神经质、创伤后应激障碍和焦虑症评分,其效果优于图卷积模型或长短期记忆网络(LSTM)。
Foundation models across the sciences: the atmosphere
经典的大气模拟方法(如数值天气预报)成本高昂,并且无法利用多样且往往稀缺的大气数据模态。但是,基础模型非常适合这里的情况。微软的研究人员创建了 Aurora79,这是一个基础模型,可针对各种大气预测问题(如全球空气污染和高分辨率中期天气模式)进行预测。它还可以通过利用大气动力学的通用学习表示来适应新任务8081。
13 亿参数的模型在来自 6 个数据集的超过 100 万小时的天气和气候数据上进行了预训练,这些数据集包括预报数据、分析数据、再分析数据和气候模拟数据。
该模型将异构输入编码为大气在空间和气压层上的标准三维表示,在推理过程中,通过 vision transformer 随时间演变,并解码为特定的预测结果。
重要的是,这是第一个在预测大气化学(六种主要空气污染物,例如臭氧、一氧化碳)方面优于数值模型的模型,而大气化学涉及数百个刚性方程。该模型也比使用数值预报的集成预报系统快 5000 倍。
Foundation models for the mind: reconstructing what you see
MindEye2 是一个生成模型82,它将功能性磁共振成像(fMRI)活动映射到一个丰富的 CLIP 空间,通过微调后的 Stable Diffusion XL 从该空间中重构出个体所看到的图像。该模型在自然场景数据集上进行训练,这个 fMRI 数据集由 8 名受试者构建而成,在他们观看来自 COCO 数据集的数百个丰富的自然主义刺激图像时,每个图像扫描 3 秒,其大脑反应被记录了 30 - 40 小时。
Speaking what you think
利用植入式微电极从大脑记录中解码语音可以为言语受损的患者实现交流83。在最近的一个案例中,一名 45 岁患有肌萎缩侧索硬化症(ALS)且四肢瘫痪、严重运动性言语受损的男子接受了手术,将微电极植入他的大脑。当患者在有提示和无结构的对话环境中说话时,电极阵列记录下神经活动。最初,通过预测最可能的英语音素,皮质神经活动被解码为一个包含 50 个单词的小词汇表,准确率为 99.6%。音素序列通过循环神经网络(RNN)组合成单词,然后通过进一步训练扩展到一个包含 125000 个单词的更大词汇表。
LLM 模型泛化与推理计算
A new challenge aims to refocus the industry on the path to AGI
Keras 的创建者弗 François Chollet 与 Zapier 的联合创始人迈 Mike Knoop 合作推出了 ARC 奖84,为在 ARC-AGI 基准测试中取得重大进展的团队提供 100 万美元的奖金。
- Chollet 早在 2019 年就创建了这个基准测试,作为衡量模型泛化能力的一种手段,重点关注对人类来说容易而对人工智能来说困难的任务。这些任务需要最少的先验知识,并强调视觉问题解决和类似谜题的任务,以使其不易被记忆。
- 从历史上看,大型语言模型在该基准测试中的表现不佳,性能最高约为 34%。
- Chollet 对大型语言模型在其训练数据之外对新问题进行泛化的能力持怀疑态度,并希望该奖项能鼓励新的研究方向,从而导向一种更像人类的智能形式。
- 到目前为止的最高分数是 46(低于目标 85 分)。这是由 Minds AI 团队实现的,他们采用了基于大型语言模型的方法,运用主动推理,在测试任务示例上对大型语言模型进行微调,并通过合成示例进行扩展以提高性能。
LLMs still struggle with planning and simulation tasks
在新的任务中,大型语言模型无法依赖记忆和检索,其性能往往会下降。这表明如果没有外部帮助,它们仍然常常难以在熟悉的模式之外进行泛化858687。
- 即使是像 GPT-4 这样先进的大型语言模型,在基于文本的游戏中可靠地模拟状态转换也有困难,特别是对于环境驱动的变化。它们无法始终如一地掌握因果关系、物理原理和物体恒常性,这使得它们即使在相对简单的任务上也难以成为良好的世界建模者。
- 研究人员发现,大型语言模型大约有 77% 的时间能准确预测直接行动的结果,比如水槽打开,但在处理环境影响方面却很吃力,例如水槽中的杯子被水填满,对于这些间接变化的准确率仅为 50%。
- 其他研究在包括 Blockworld 和 Logistics 等规划领域对大型语言模型进行了评估。GPT-4 有 12% 的时间能生成可执行的计划。然而,通过使用带有外部验证的迭代提示,经过 15 轮反馈后,Blockworld 计划的准确率达到 82%,Logistics 计划的准确率达到 70%。当使用 o1 重新运行时,性能有所提升,但仍远非完美。
Can LLMs learn to think before they speak?
研究人员正在探索生成更强大的内部推理过程的方法,针对训练和推理两个方面。后一种方法似乎是 OpenAI 的 o1 在能力上实现飞跃的基础。
来自斯坦福大学和 Notbad AI 联合团队的 Quiet-STaR 88在预训练期间生成内部推理过程,使用并行采样算法和自定义元标记来标记这些 “思考” 的开始和结束。
该方法采用一种受强化学习启发的技术来优化生成的推理过程的有用性,奖励那些能够提高模型预测未来标记能力的推理过程。
与此同时,谷歌 DeepMind 专注于推理89,表明对于许多类型的问题,在测试时战略性地应用更多计算可能比使用更大的预训练模型更有效。
一个斯坦福大学 / 牛津大学的团队也研究了 scaling inference comupte,发现重复采样可以显著提高覆盖范围90。他们认为,使用较弱且成本较低的模型进行多次尝试可以胜过其更强且更昂贵的同类模型的单次尝试。
Open-endedness gathers momentum as a promising research direction
提高大型语言模型推理稳健性的一种途径是采用开放的方法,使它们能够生成新知识。
在一篇立场文件中91,谷歌 DeepMind 的一个团队将开放式系统描述为能够 持续生成对观察者来说是新颖且可学习的人工制品。他们概述了通向开放式基础模型的潜在途径,包括强化学习、自我改进、任务生成和进化算法。
在自我改进方面,我们看到了 Strategist92,这是一种让大型语言模型为多智能体游戏学习新技能的方法。
研究人员使用了一种双层树搜索方法,将 high-level 的战略学习与 low-level 的 self-play对战相结合以获取反馈。在《纯策略游戏》和《抵抗组织:阿瓦隆》中,它在行动规划和对话生成方面优于强化学习和其他基于大型语言模型的方法。
But were implicit reasoning capabilities staring us in the face the whole time?
在经过过度拟合点之后的长时间训练(称为 grokking,领悟? )后,一些研究人员认为,Transformer 通过组合和比较任务学会对参数知识进行推理。
俄亥俄州立大学的研究人员认为93,在具有大搜索空间的复杂推理任务中,一个完全 “领悟” 的 Transformer 在性能上优于当时的最先进模型,如 GPT-4-Turbo 和 Gemini-1.5-Pro。
他们进行了机制分析,以了解模型在 “领悟” 期间的内部工作原理,揭示了针对不同任务的不同泛化回路。
然而,他们发现,虽然完全 “领悟” 的模型在比较任务(例如,基于原子事实比较属性)中表现良好,但在组合任务中的分布外泛化能力较弱。
这引发了关于这些是否真的是有意义的推理能力,还是只是另一种形式的记忆的问题,尽管研究人员认为通过更好的跨层记忆共享来增强 Transformer 可能会解决这个问题。
Program search unlocks new discoveries in the mathematical sciences
FunSearch 94 结合了大型语言模型和进化算法,利用大型语言模型生成和修改程序,并由一个评估函数引导,该函数对解决方案的质量进行评分。
搜索程序而不是直接搜索解决方案,使其能够发现复杂对象或策略的简洁、可解释的表示形式。这种形式的程序搜索是 Chollet 认为最有潜力解决 ARC 挑战的途径之一。
谷歌 DeepMind 团队将其应用于极值组合数学中的帽子集问题和在线装箱问题。在这两种情况下,FunSearch 都发现了超越人类设计方法的新颖解决方案。
RL drives improvements in VLM performance…
对于智能体来说,要想有用,它们需要对现实世界的随机性具有鲁棒性,而这一直是当前最先进的模型所面临的难题。我们开始看到取得进展的迹象。
DigiRL 95 是一种新颖的自主强化学习方法,专门用于为 Andriod-device 训练自然状态下的设备控制智能体。该方法包括两个阶段:离线强化学习,接着是从离线到在线的强化学习。
它在 “Andriod-in-the-wild” 数据集上实现了 62.7% 的任务成功率,相比之前的最先进技术有了显著提高。
…while LLMs improve RL performance
2019 年,Uber 发布了 Go-Explore,这是一款 RL 代理,它通过存档已发现的状态并迭代返回有希望的状态并从中进行探索来解决困难的探索问题。2024 年,大型语言模型正在为其助力。
智能 Go-Explore(IGE)使用大型语言模型来指导状态选择、动作选择和存档更新,而不是原始 Go-Explore 中手工设计的启发式方法。这使得在复杂环境中能够进行更灵活和智能的探索。
这种方法还使 IGE 能够识别有前景的发现并加以利用,这是开放式学习系统的一个关键方面。
在数学推理、网格世界和基于文本的冒险游戏中,它的表现显著优于其他大型语言模型智能体。
从 GPT-4 切换到 GPT-3.5 会导致在所有环境中的性能显著下降,这表明 IGE 的性能与基础语言模型的能力成正比。
Who remembers Monte Carlo Tree Search?
为了改进规划,像蒙特卡洛树搜索这样曾助力 AlphaGo 的方法正慢慢重新回到人们的视野中。早期的结果很有希望,但它们是否足够呢?
MultiOn 和斯坦福大学将大型语言模型与蒙特卡洛树搜索相结合96,同时加入了自我批判机制和直接偏好优化,以便从不同的成功和失败标准中学习。
他们发现,在经过一天的数据收集后,在真实世界的预订场景中,这将 Llama-3 70B 的零样本性能从 18.6% 提高到了 81.7%,而结合在线搜索后可高达 95.4%。
长期的问题将是下一个标记预测损失是否过于精细。这有可能会限制强化学习和蒙特卡洛树搜索实现智能体行为的能力,因为它过于关注单个标记,从而阻碍了对更广泛、更具战略性的解决方案的探索。
Could foundation models make it easier to train RL agents at scale?
训练强化学习智能体的一个重大瓶颈是训练数据的短缺。标准方法如转换预先存在的环境(例如雅达利游戏环境)或手动构建环境都很耗费劳动力且难以扩展。
Genie(2024 年国际机器学习大会最佳论文奖得主)97是一个可以生成动作可控虚拟世界的世界模型。它分析了来自 2D 平台游戏的 30000 小时视频游戏镜头,学习压缩视觉信息并推断驱动帧之间变化的动作。
通过从视频数据中学习潜在的动作空间,它可以处理动作表示而无需明确的动作标签,这使其与其他世界模型区分开来。
Genie 既能够想象全新的交互式场景,又表现出显著的灵活性:它可以接受各种形式的提示,从文本描述到手绘草图,并将它们变为可玩的环境。
这种方法展示了在游戏之外的适用性,该团队成功地将游戏模型的超参数应用于机器人数据,而无需进行微调。
Could foundation models make it easier to train RL agents at scale?
帝国理工学院和英属哥伦比亚大学的 OMNI-EPIC 98 利用大型语言模型创建了理论上无穷无尽的强化学习任务和环境流,以帮助智能体在先前学到的技能基础上继续发展。该系统生成可执行的 Python 代码,能够为每个任务实现模拟环境和奖励函数,并采用一个模型来评估新生成的任务是否足够新颖和复杂。
Are scientists inventing their AI replacement?
Sakana AI 一直专注于试图增强当前顶尖模型的创造能力。他们的第一篇论文之一着眼于使用基础模型来使研究本身自动化。
“人工智能科学家” 99 是一个端到端的框架,旨在实现研究想法的生成、实施以及研究论文的撰写自动化。在获得一个起始模板后,它会集思广益提出新颖的研究方向,然后执行实验并撰写报告。研究人员声称,他们由大型语言模型驱动的评审员以接近人类的准确性评估生成的论文。
研究人员用它生成了关于扩散、语言建模和 “顿悟” 的示例论文。乍一看这些论文很有说服力,但仔细检查会发现一些缺陷。
然而,该系统不时地显示出不安全行为的迹象,例如导入不熟悉的 Python 库以及编辑代码以延长实验时间线。
An ensemble approach appears to drive strong performance improvements in code
Meta 的 TestGen-LLM 结合了多个大型语言模型、提示和配置,以利用不同模型的优势来提高 Instagram 和 Facebook 上 Android 代码的单元测试覆盖率。
它采用一种 “可靠” 的方法,对生成的测试进行过滤,以确保它们能够成功构建、可靠通过并在推荐之前提高覆盖率。这是首次在大规模工业部署中采用将大型语言模型与可验证的代码改进保证相结合的方法,解决了在软件工程背景下对大型语言模型的幻觉和可靠性的担忧。
在部署中,TestGen-LLM 改进了约 10% 它所应用的测试类,其 73% 的建议被开发人员接受。
自动驾驶与视觉分割
Self-driving embraces more modalities
Wayve 的 LINGO-2 100是其视觉-语言-行动模型的第二代,与它的前身不同,它既可以生成实时驾驶解说,又可以控制汽车,将语言解释与决策和行动直接联系起来。
与此同时,该公司正在使用生成式模型为其模拟器增加更多真实世界的细节。
PRISM-1 101 仅使用摄像头输入就可以创建动态驾驶场景的逼真 4D 模拟。它通过准确地重建复杂的城市环境(包括行人、骑自行车的人和车辆等移动元素),无需依赖激光雷达或 3D 边界框,从而实现更有效的测试和训练。
为了构建一个适用于视频和图像的统一模型,Meta 进行了一些调整。例如,他们加入了一种记忆机制来跟踪跨帧的对象,以及一个遮挡头来处理消失或重新出现的对象。
Segment Anything gets boosters and expands to video
去年,Meta 的 Segment Anything 以其能够根据任何提示在图像中识别和分割对象的能力给人留下深刻印象。在 7 月,他们发布了 Segment Anything 2 102,这让观察者们大为震惊。
他们发现,在图像分割方面,它比 SAM1 更准确且速度快 6 倍,同时能够以少 3 倍的交互次数超越先前领先的视频分割模型的准确性。
然而,该模型在视频中同时分割多个对象时效率较低,并且在处理较长的片段时可能会遇到困难。
机器人再度流行
Robotics (finally) becomes fashionable (again) as the big labs pile in
LLM 和 VLM 模型展示了它们在帮助解决数据瓶颈和解决长期存在的可用性障碍方面的潜力。
Google DeepMind quietly emerges as a robotics leader
尽管所有的目光都集中在 Gemini 上,但谷歌 DeepMind 团队一直在稳步增加其在机器人技术方面的产出,提高机器人的效率、适应性和数据收集能力103104。
该团队创建了 AutoRT,这是一个使用 VLM 进行环境理解,并使用 LLM 提出机器人可以执行的一系列创造性任务的系统。然后,这些模型与机器人控制策略相结合。这有助于在以前从未见过的环境中快速扩大部署规模。
RT-Trajectory 通过视频输入增强机器人学习。对于演示数据集中的每个视频,都会叠加一个执行任务的夹具的二维草图。这在模型学习时为其提供了实用的视觉提示。
该团队还提高了 Transformer 的效率。SARA-RT 是一种新颖的 up-training 方法,可将预先训练或微调的机器人策略从二次注意力转换为线性注意力,同时保持质量。
研究人员发现 Gemini 1.5 Pro 的多模态能力和长上下文窗口使其成为通过自然语言与机器人交互的有效方式。
Hugging Face pulls down barriers to entry
Hugging Face 降低了准入门槛。从历史上看,机器人技术领域的开源数据集、工具和库比人工智能的其他领域要少得多,这人为地设置了较高的准入门槛。Hugging Face 的 LeRobot 105 旨在填补这一差距,它提供预训练模型、包含人工收集演示的数据集以及预训练演示。并且社区很喜欢它。
Diffusion models drive improvements in policy and action generation
在图像和音频生成方面已经成熟的扩散模型,继续在机器人技术中展示了其在生成复杂动作序列方面的有效性106107108。
许多研究小组旨在弥合机器人学习中高维观察空间和低维动作空间之间的差距。他们创建了一种统一的表示形式,使学习算法能够理解动作的空间含义。
扩散模型擅长对这类复杂的、非线性的多模态分布进行建模,而其迭代去噪过程允许对动作或轨迹进行逐步细化。
有多种方法来解决这个问题。帝国理工学院和上海期智研究院的研究人员选择了 RGB 图像,因为它提供了丰富的视觉信息,并且与预训练模型兼容。
同时,加州大学伯克利分校和斯坦福大学的一个团队利用了点云,因为它具有明确的 3D 信息。
Can we stretch existing real-world robotics data further than we currently do?
由于现实世界数据有限,机器人策略常常因缺乏通用性而受到阻碍。研究人员不是去寻找更多的数据,而是为我们已有的数据注入更多的结构和知识。
卡内基梅隆大学的一个团队概述了一种方法,包括从人类视频数据中学习更多的 affordance 信息,例如手部动作、物体交互以及接触点109。这些信息随后可用于微调现有的视觉表示,使其更适合机器人任务。这在现实世界的操作任务中持续提高了性能。
与此同时,伯克利 / 斯坦福大学的一个团队发现,思维链推理可以产生类似的影响110。增强后的模型不是直接预测动作,而是在决定动作之前,被训练逐步思考计划、子任务和视觉特征。这种方法使用大型语言模型为推理步骤生成训练数据。
Can we overcome the data bottleneck for humanoids?
通过依赖人类示范者的模仿学习来模拟人类行为的复杂性是具有挑战性的。虽然有效,但难以大规模实施。斯坦福大学有一些变通方法。
HumanPlus 111 是一个用于人形机器人从人类数据中学习的全栈系统。它结合了实时跟随系统和模仿学习算法。
跟随系统使用单个 RGB 摄像头和低级别策略,允许人类操作员实时控制人形机器人的整个身体。这种低级别控制策略在模拟中的大量人类运动数据数据集上进行训练,并无需额外训练即可转移到现实世界中。
模仿学习组件能够从跟随数据中高效地学习自主技能。它使用双眼以自我为中心的视觉,并将动作预测与前向动力学预测相结合。
该系统在各种任务上展示了令人印象深刻的结果,包括诸如穿鞋和行走等复杂动作,仅使用多达 40 次的演示。
Back with a vengeance: robot doggos 🐶
波士顿动力公司的 Spot 机器人在具身人工智能的移动性和稳定性方面展示了进步,但缺乏操作技能。现在研究人员正在解决这一差距。
一个斯坦福大学 / 哥伦比亚大学112的团队将现实世界的演示数据与在模拟中训练的控制器相结合,专注于控制机器人的夹具运动而不是单个关节。这种方法简化了将操作技能从固定机械臂转移到移动机器人上的过程。
与此同时,加州大学圣地亚哥分校的一个团队113 开发了一个两部分系统:一个用于执行命令的低级策略和一个用于生成基于视觉的命令的高级策略,增强了机器人的操作能力。
The Apple Vision Pro emerges as the must-have robotics research tool
虽然到目前为止消费者对 Vision Pro 的需求不温不火,但它却在机器人研究领域掀起了一场风暴。在机器人研究中,Vision Pro 的高分辨率、先进的跟踪和处理能力正被从事远程操作(即远程控制机器人的运动和动作)的研究人员所利用。
像 Open-TeleVision 114 和 Bunny-Vision Pro 115这样的系统使用它来帮助实现对多指机器人手的精确控制(就前者而言,可以在 3000 英里的距离上进行控制),与以前的方法相比,在复杂的操作任务上展示出了更好的性能。它们解决了诸如实时控制、通过避免碰撞实现安全以及有效的双手协调等挑战。
Enterprise automation set to get an AI-first upgrade
传统的机器人流程自动化(RPA),以 UiPath 为代表,一直面临着高设置成本、执行脆弱以及繁重维护的问题。两种新颖的方法,即 FlowMind(摩根大通)和 ECLAIR(斯坦福大学),利用基础模型来解决这些局限性。
FlowMind 116 专注于金融工作流程,使用大型语言模型通过 API 生成可执行的工作流程。在 NCEN-QA 数据集的实验中,FlowMind 在工作流程理解方面实现了 99.5% 的准确率。
ECLAIR 117 则采取了更广泛的方法,使用多模态模型从演示中学习,并直接与各种企业环境中的图形用户界面进行交互。在网页导航任务中,ECLAIR 将完成率从 0% 提高到了 40%。
AI Research 投入与产出
The global balance of power in AI research remains unchanged, but academia gains
随着人工智能成为新的竞争战场,大型科技公司开始对其工作的更多细节守口如瓶。前沿实验室自本报告第一次有意义地降低了发表水平,而学术界则开始发力。
-
State of AI Report 2024, Nathan Benaich, https://docs.google.com/presentation/d/1GmZmoWOa2O92BPrncRcTKa15xvQGhq7g4I4hJSNlC0M/preview ↩︎
-
https://www.youtube.com/watch?v=M9YOO7N5jF8 (PhD code) ↩︎
-
https://www.understandingai.org/p/openai-just-unleashed-an-alien-of (spatial reasoning) ↩︎
-
https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/?utm_source=twitter&utm_medium=organic_social&utm_content=video&utm_campaign=llama32 ↩︎
-
https://www.mpi.nl/publications/item3588217/rethinking-open-source-generative-ai-open-washing-and-eu-ai-act ↩︎
-
https://arxiv.org/abs/2405.00332 (Scale paper) ↩︎
-
https://huggingface.co/datasets/keirp/hungarian_national_hs_finals_exam (X.ai re-evaluation) ↩︎
-
https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/ ↩︎
-
https://www.arxiv.org/abs/2407.14679 (NVIDIA paper) ↩︎
-
https://x.com/karpathy/status/1814038096218083497 Source: https://arxiv.org/abs/2403.05530 (Gemini 1.5) ↩︎
-
https://arxiv.org/abs/2408.00118 (Gemma 2) ↩︎
-
Image Credit: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model ↩︎
-
https://www.microsoft.com/en-us/research/publication/bitnet-scaling-1-bit-transformers-for-large-language-models/ ↩︎
-
https://arxiv.org/pdf/2402.17764 (b 1.58 paper) ↩︎
-
https://falconllm.tii.ae/tii-releases-first-sslm-with-falcon-mamba-7b.html ↩︎
-
https://arxiv.org/abs/2406.07887 (8B-Mamba-2-Hybrid) ↩︎
-
https://arxiv.org/abs/2402.19427 (Griffin) ↩︎
-
https://developer.nvidia.com/blog/leverage-our-latest-open-models-for-synthetic-data-generation-with-nvidia-nemotron-4-340b/ ↩︎
-
https://arxiv.org/abs/2406.08464 (Magpie) ↩︎
-
https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1 ↩︎
-
https://arxiv.org/abs/2405.05374 (Data filtering and clustering approaches) ↩︎
-
https://arxiv.org/abs/2402.09906 (GritLM) ↩︎
-
https://huggingface.co/spaces/mteb/leaderboard (MTEB Leaderboard) ↩︎
-
https://x.com/841io/status/1838617043442241752 Fernando Diez thread ↩︎
-
https://arxiv.org/abs/2406.16828 (Ragnarök) ↩︎
-
https://arxiv.org/abs/2402.17896 (Researchy Questions) ↩︎
-
https://arxiv.org/abs/2311.08105 (DiLoCo paper) ↩︎
-
https://arxiv.org/abs/2401.09135 (Async Local-SGD training) ↩︎
-
https://arxiv.org/abs/2407.07852 (OpenDiLoCo) ↩︎
-
Image credit: https://huggingface.co/blog/PandorAI1995/vlm-art-analysis-by-florence-2-b-and-qwen2-vl-2b ↩︎
-
https://arxiv.org/abs/2404.06395 (MiniCPM) ↩︎
-
https://arxiv.org/abs/2408.01800 (MiniCPM-V) ↩︎
-
https://cs.stanford.edu/people/karpathy/deepimagesent/ (2018 images) ↩︎
-
https://x.com/jobergum/status/1831410534400524680/photo/1 (Qwen screenshot) ↩︎
-
https://www.microsoft.com/en-us/research/publication/florence-2-advancing-a-unified-representation-for-a-variety-of-vision-tasks/ ↩︎
-
https://arxiv.org/abs/2408.10188v3 (LongVILA) ↩︎
-
https://x.com/reach_vb/status/1838938439267258840?s=46&t=8YCMEcmVVXRPm8SXTMgdlw (Molmo performance) ↩︎
-
https://arxiv.org/abs/2311.17042 (Adversarial diffusion distillation) ↩︎
-
https://arxiv.org/abs/2403.03206 (Rectified flow transformers) ↩︎
-
https://openai.com/index/video-generation-models-as-world-simulators/ ↩︎
-
https://www.nature.com/articles/s41586-024-07487-w (AlphaFold3 Paper) ↩︎
-
https://github.com/Ligo-Biosciences/AlphaFold3 (Ligo’s AlphaFold 3) ↩︎
-
https://harrisbio.substack.com/p/the-race-to-reproduce-alphafold3 (Updating blog on AF 3 replicates) ↩︎
-
https://arxiv.org/abs/2408.16975 (HelixFold 3 Model) ↩︎
-
https://chaiassets.com/chai-1/paper/technical_report_v1.pdf (Chai-1) ↩︎
-
https://arxiv.org/abs/2409.08022 (AlphaProteo Paper) ↩︎
-
https://deepmind.google/discover/blog/alphaproteo-generates-novel-proteins-for-biology-and-health-research/ (DeepMind blog) ↩︎
-
https://arxiv.org/abs/2311.17932 (Apple Conformer Generation Paper) ↩︎
-
https://www.nature.com/articles/s41586-024-07487-w (AlphaFold 3 Paper) ↩︎
-
https://www.biorxiv.org/content/10.1101/2024.07.01.600583v1.full.pdf (ESM 3 paper) ↩︎
-
https://www.biorxiv.org/content/10.1101/2024.04.22.590591v1 ,The dataset displays additional diversity compared to incumbents CRISPRCasDB and CasPDB. ↩︎
-
https://arxiv.org/abs/2308.07413 (PoseCheck) ↩︎
-
https://arxiv.org/abs/2308.05777 (PoseBusters) ↩︎
-
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1012463 (Recursion) ↩︎
-
https://arxiv.org/abs/2206.07697 (MACE from 2022) ↩︎
-
https://arxiv.org/abs/2401.00096 (MACE-MP-0) ↩︎
-
https://www.biorxiv.org/content/10.1101/2023.09.12.557460v2.full.pdf ↩︎
-
https://www.microsoft.com/en-us/research/blog/introducing-aurora-the-first-large-scale-foundation-model-of-the-atmosphere/ ↩︎
-
https://arxiv.org/abs/2403.11207 (MindEye 2) ↩︎
-
https://www.nejm.org/doi/full/10.1056/NEJMoa2314132?logout=true ↩︎
-
https://arxiv.org/abs/2406.06485 (LLMs and text-based world simulation) ↩︎
-
https://arxiv.org/abs/2402.01817 (LLM planning) ↩︎
-
https://arxiv.org/abs/2409.13373 (o1 update) ↩︎
-
https://arxiv.org/abs/2403.09629 (Quiet-STaR) ↩︎
-
https://arxiv.org/abs/2408.03314 (Scaling LLM Test-Time Compute) ↩︎
-
https://arxiv.org/abs/2407.21787 (Repeated Sampling) ↩︎
-
https://arxiv.org/abs/2406.04268 (Google DeepMind position paper) ↩︎
-
https://openreview.net/forum?id=UHWBmZuJPF (Strategist) ↩︎
-
https://deepmind.google/discover/blog/shaping-the-future-of-advanced-robotics/ ↩︎
-
https://arxiv.org/abs/2407.07775v2 (multimodal instructions) ↩︎
-
https://arxiv.org/abs/2403.03954 (3 D Diffusion Policy) ↩︎
-
https://arxiv.org/abs/2401.00025 (Any-point Trajectory Modeling) ↩︎
-
https://arxiv.org/abs/2407.18911 (Human affordances) ↩︎
-
https://arxiv.org/abs/2407.08693 (Embodied chain-of-thought) ↩︎
-
https://arxiv.org/abs/2407.10353 (Stanford/Columbia paper) ↩︎
-
https://arxiv.org/abs/2403.16967 (UC San Diego paper) ↩︎
-
https://arxiv.org/abs/2407.01512 (Open-TeleVision) ↩︎
-
https://arxiv.org/abs/2407.03162 (Bunny-Vision Pro) ↩︎
-
https://arxiv.org/abs/2404.13050 (FlowMind) ↩︎
-
https://arxiv.org/abs/2405.03710 (ECLAIR) ↩︎
-
No backlinks found.